 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Light Image Enhancement Challenge at NTIRE 2026
Apr 19, 2026This paper presents a comprehensive review of the NTIRE 2026 Low Light Image Enhancement Challenge, highlighting the proposed solutions and final results. The objective of this challenge is to identify effective networks capable of producing clearer and visually compelling images in diverse and challenging conditions by learning representative visual cues with the purpose of restoring information loss due to low-contrast and noisy images. A total of 195 participants registered for the first track and 153 for the second track of the competition, and 22 teams ultimately submitted valid entries. This paper thoroughly evaluates the state-of-the-art advances in (joint denoising and) low-light image enhancement, showcasing the significant progress in the field, while leveraging samples of our novel dataset.
PUMPS: Skeleton-Agnostic Point-based Universal Motion Pre-Training for Synthesis in Human Motion Tasks
Jul 27, 2025Motion skeletons drive 3D character animation by transforming bone hierarchies, but differences in proportions or structure make motion data hard to transfer across skeletons, posing challenges for data-driven motion synthesis. Temporal Point Clouds (TPCs) offer an unstructured, cross-compatible motion representation. Though reversible with skeletons, TPCs mainly serve for compatibility, not for direct motion task learning. Doing so would require data synthesis capabilities for the TPC format, which presents unexplored challenges regarding its unique temporal consistency and point identifiability. Therefore, we propose PUMPS, the primordial autoencoder architecture for TPC data. PUMPS independently reduces frame-wise point clouds into sampleable feature vectors, from which a decoder extracts distinct temporal points using latent Gaussian noise vectors as sampling identifiers. We introduce linear assignment-based point pairing to optimise the TPC reconstruction process, and negate the use of expensive point-wise attention mechanisms in the architecture. Using these latent features, we pre-train a motion synthesis model capable of performing motion prediction, transition generation, and keyframe interpolation. For these pre-training tasks, PUMPS performs remarkably well even without native dataset supervision, matching state-of-the-art performance. When fine-tuned for motion denoising or estimation, PUMPS outperforms many respective methods without deviating from its generalist architecture.
See360: Novel Panoramic View Interpolation
Jan 07, 2024


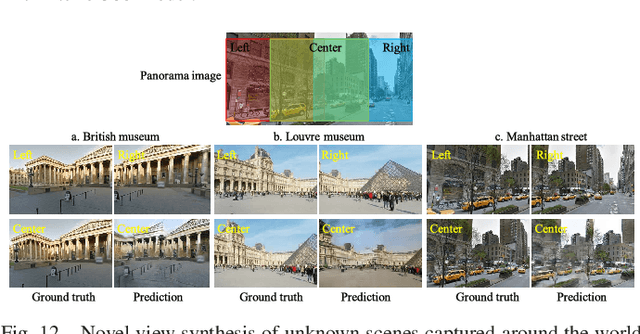
We present See360, which is a versatile and efficient framework for 360 panoramic view interpolation using latent space viewpoint estimation. Most of the existing view rendering approaches only focus on indoor or synthetic 3D environments and render new views of small objects. In contrast, we suggest to tackle camera-centered view synthesis as a 2D affine transformation without using point clouds or depth maps, which enables an effective 360? panoramic scene exploration. Given a pair of reference images, the See360 model learns to render novel views by a proposed novel Multi-Scale Affine Transformer (MSAT), enabling the coarse-to-fine feature rendering. We also propose a Conditional Latent space AutoEncoder (C-LAE) to achieve view interpolation at any arbitrary angle. To show the versatility of our method, we introduce four training datasets, namely UrbanCity360, Archinterior360, HungHom360 and Lab360, which are collected from indoor and outdoor environments for both real and synthetic rendering. Experimental results show that the proposed method is generic enough to achieve real-time rendering of arbitrary views for all four datasets. In addition, our See360 model can be applied to view synthesis in the wild: with only a short extra training time (approximately 10 mins), and is able to render unknown real-world scenes. The superior performance of See360 opens up a promising direction for camera-centered view rendering and 360 panoramic view interpolation.
* 12 pages, 10 figures
Domain Transfer in Latent Space Wins on Image Super-Resolution -- a Non-Denoising Model
Nov 20, 2023Large scale image super-resolution is a challenging computer vision task, since vast information is missing in a highly degraded image, say for example forscale x16 super-resolution. Diffusion models are used successfully in recent years in extreme super-resolution applications, in which Gaussian noise is used as a means to form a latent photo-realistic space, and acts as a link between the space of latent vectors and the latent photo-realistic space. There are quite a few sophisticated mathematical derivations on mapping the statistics of Gaussian noises making Diffusion Models successful. In this paper we propose a simple approach which gets away from using Gaussian noise but adopts some basic structures of diffusion models for efficient image super-resolution. Essentially, we propose a DNN to perform domain transfer between neighbor domains, which can learn the differences in statistical properties to facilitate gradual interpolation with results of reasonable quality. Further quality improvement is achieved by conditioning the domain transfer with reference to the input LR image. Experimental results show that our method outperforms not only state-of-the-art large scale super resolution models, but also the current diffusion models for image super-resolution. The approach can readily be extended to other image-to-image tasks, such as image enlightening, inpainting, denoising, etc.
Intelligent Painter: Picture Composition With Resampling Diffusion Model
Oct 31, 2022Have you ever thought that you can be an intelligent painter? This means that you can paint a picture with a few expected objects in mind, or with a desirable scene. This is different from normal inpainting approaches for which the location of specific objects cannot be determined. In this paper, we present an intelligent painter that generate a person's imaginary scene in one go, given explicit hints. We propose a resampling strategy for Denoising Diffusion Probabilistic Model (DDPM) to intelligently compose harmonized scenery images by injecting explicit landmark inputs at specific locations. By exploiting the diffusion property, we resample efficiently to produce realistic images. Experimental results show that our resampling method favors the semantic meaning of the generated output efficiently and generate less blurry output. Quantitative analysis of image quality assessment shows that our method produces higher perceptual quality images compared with the state-of-the-art methods.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Name Your Style: An Arbitrary Artist-aware Image Style Transfer
Mar 05, 2022
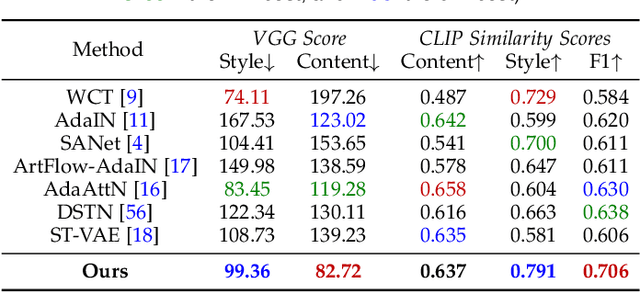
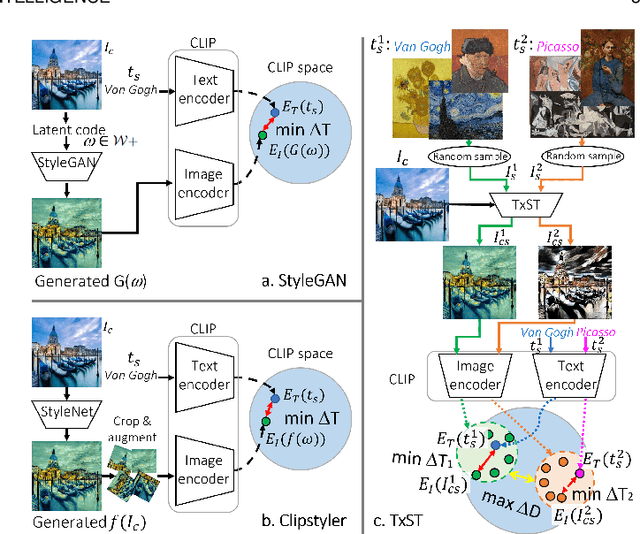
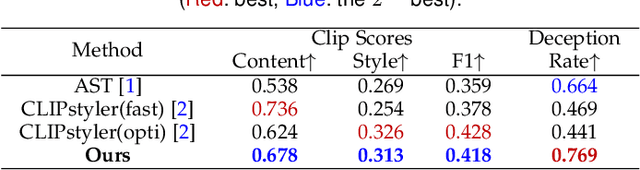
Image style transfer has attracted widespread attention in the past few years. Despite its remarkable results, it requires additional style images available as references, making it less flexible and inconvenient. Using text is the most natural way to describe the style. More importantly, text can describe implicit abstract styles, like styles of specific artists or art movements. In this paper, we propose a text-driven image style transfer (TxST) that leverages advanced image-text encoders to control arbitrary style transfer. We introduce a contrastive training strategy to effectively extract style descriptions from the image-text model (i.e., CLIP), which aligns stylization with the text description. To this end, we also propose a novel and efficient attention module that explores cross-attentions to fuse style and content features. Finally, we achieve an arbitrary artist-aware image style transfer to learn and transfer specific artistic characters such as Picasso, oil painting, or a rough sketch. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods on both image and textual styles. Moreover, it can mimic the styles of one or many artists to achieve attractive results, thus highlighting a promising direction in image style transfer.
Variational AutoEncoder for Reference based Image Super-Resolution
Jun 08, 2021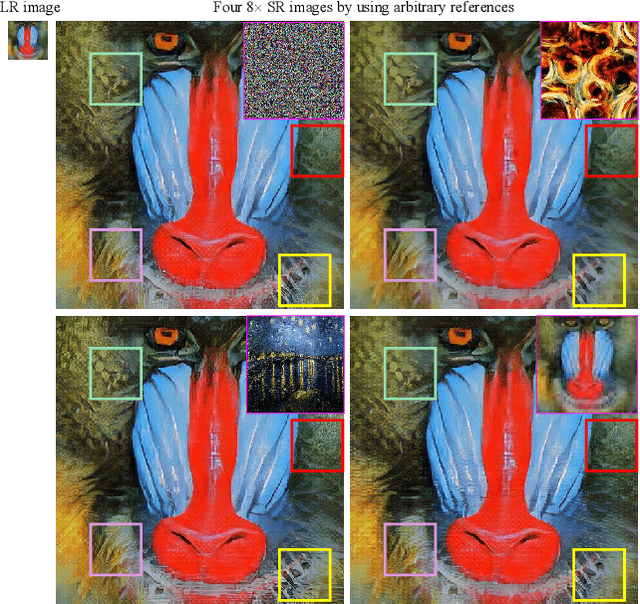

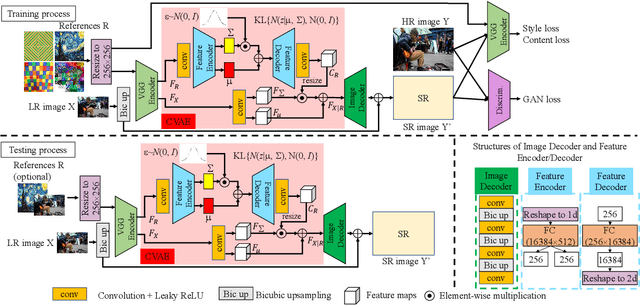
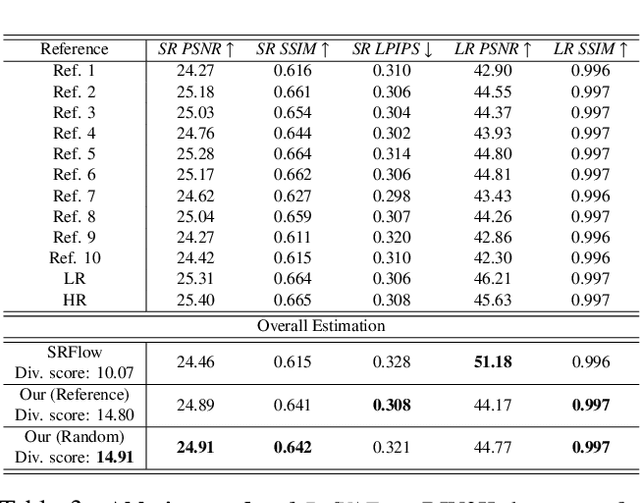
In this paper, we propose a novel reference based image super-resolution approach via Variational AutoEncoder (RefVAE). Existing state-of-the-art methods mainly focus on single image super-resolution which cannot perform well on large upsampling factors, e.g., 8$\times$. We propose a reference based image super-resolution, for which any arbitrary image can act as a reference for super-resolution. Even using random map or low-resolution image itself, the proposed RefVAE can transfer the knowledge from the reference to the super-resolved images. Depending upon different references, the proposed method can generate different versions of super-resolved images from a hidden super-resolution space. Besides using different datasets for some standard evaluations with PSNR and SSIM, we also took part in the NTIRE2021 SR Space challenge and have provided results of the randomness evaluation of our approach. Compared to other state-of-the-art methods, our approach achieves higher diverse scores.
* 10 pages, 6 figures
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020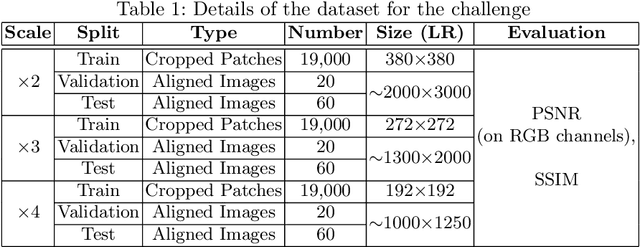
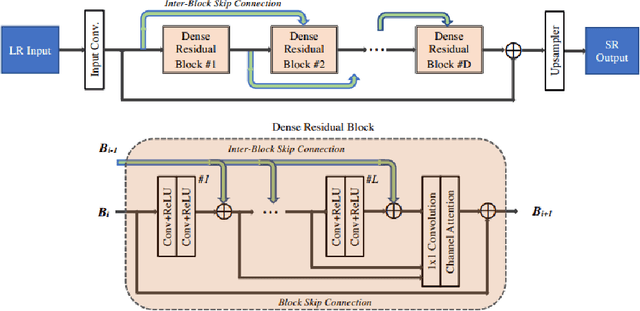
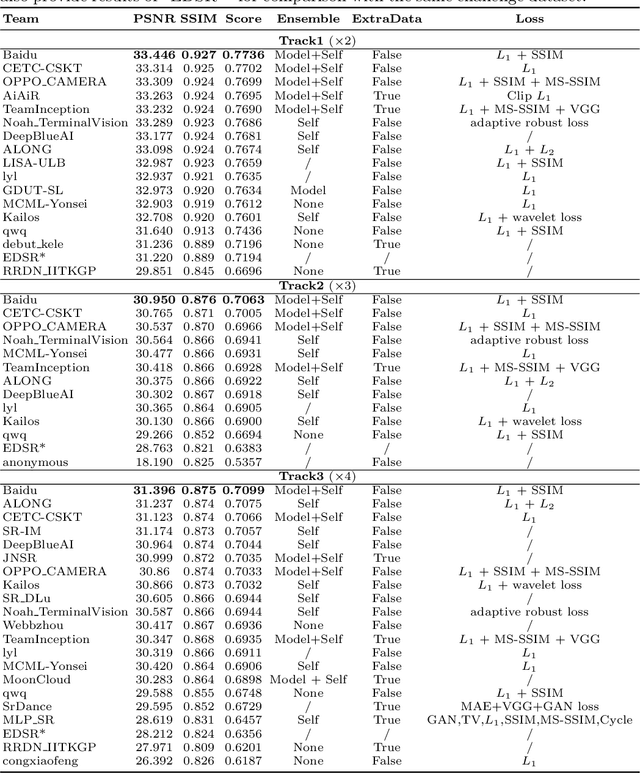
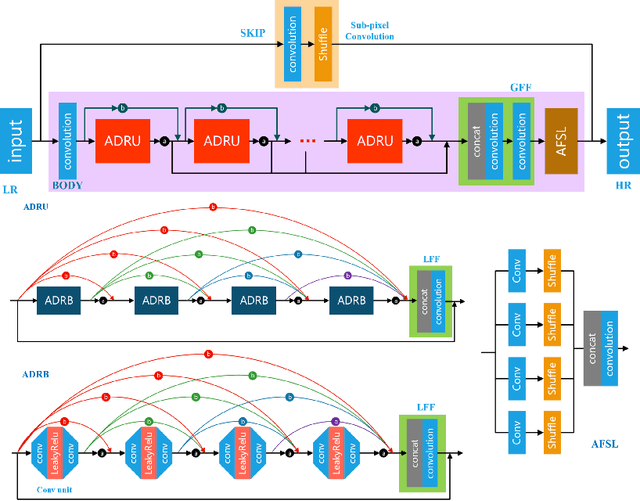
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
Deep Relighting Networks for Image Light Source Manipulation
Aug 19, 2020

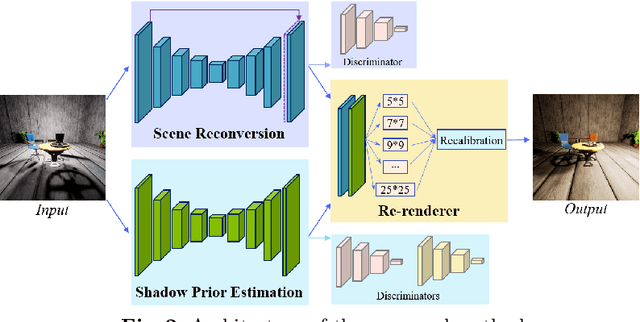
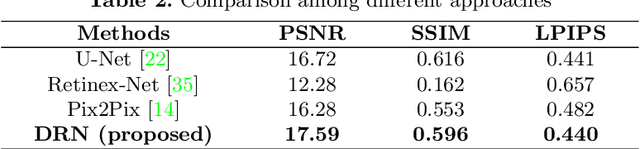
Manipulating the light source of given images is an interesting task and useful in various applications, including photography and cinematography. Existing methods usually require additional information like the geometric structure of the scene, which may not be available for most images. In this paper, we formulate the single image relighting task and propose a novel Deep Relighting Network (DRN) with three parts: 1) scene reconversion, which aims to reveal the primary scene structure through a deep auto-encoder network, 2) shadow prior estimation, to predict light effect from the new light direction through adversarial learning, and 3) re-renderer, to combine the primary structure with the reconstructed shadow view to form the required estimation under the target light source. Experimental results show that the proposed method outperforms other possible methods, both qualitatively and quantitatively. Specifically, the proposed DRN has achieved the best PSNR in the "AIM2020 - Any to one relighting challenge" of the 2020 ECCV conference.