 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Zero-Cost Protection Against Mimicry by Personalized Diffusion Models
Dec 16, 2024Recent advancements in diffusion models revolutionize image generation but pose risks of misuse, such as replicating artworks or generating deepfakes. Existing image protection methods, though effective, struggle to balance protection efficacy, invisibility, and latency, thus limiting practical use. We introduce perturbation pre-training to reduce latency and propose a mixture-of-perturbations approach that dynamically adapts to input images to minimize performance degradation. Our novel training strategy computes protection loss across multiple VAE feature spaces, while adaptive targeted protection at inference enhances robustness and invisibility. Experiments show comparable protection performance with improved invisibility and drastically reduced inference time. The code and demo are available at \url{https://webtoon.github.io/impasto}
Imperceptible Protection against Style Imitation from Diffusion Models
Mar 28, 2024Recent progress in diffusion models has profoundly enhanced the fidelity of image generation. However, this has raised concerns about copyright infringements. While prior methods have introduced adversarial perturbations to prevent style imitation, most are accompanied by the degradation of artworks' visual quality. Recognizing the importance of maintaining this, we develop a visually improved protection method that preserves its protection capability. To this end, we create a perceptual map to identify areas most sensitive to human eyes. We then adjust the protection intensity guided by an instance-aware refinement. We also integrate a perceptual constraints bank to further improve the imperceptibility. Results show that our method substantially elevates the quality of the protected image without compromising on protection efficacy.
DreamStyler: Paint by Style Inversion with Text-to-Image Diffusion Models
Sep 13, 2023Recent progresses in large-scale text-to-image models have yielded remarkable accomplishments, finding various applications in art domain. However, expressing unique characteristics of an artwork (e.g. brushwork, colortone, or composition) with text prompts alone may encounter limitations due to the inherent constraints of verbal description. To this end, we introduce DreamStyler, a novel framework designed for artistic image synthesis, proficient in both text-to-image synthesis and style transfer. DreamStyler optimizes a multi-stage textual embedding with a context-aware text prompt, resulting in prominent image quality. In addition, with content and style guidance, DreamStyler exhibits flexibility to accommodate a range of style references. Experimental results demonstrate its superior performance across multiple scenarios, suggesting its promising potential in artistic product creation.
AesPA-Net: Aesthetic Pattern-Aware Style Transfer Networks
Aug 08, 2023To deliver the artistic expression of the target style, recent studies exploit the attention mechanism owing to its ability to map the local patches of the style image to the corresponding patches of the content image. However, because of the low semantic correspondence between arbitrary content and artworks, the attention module repeatedly abuses specific local patches from the style image, resulting in disharmonious and evident repetitive artifacts. To overcome this limitation and accomplish impeccable artistic style transfer, we focus on enhancing the attention mechanism and capturing the rhythm of patterns that organize the style. In this paper, we introduce a novel metric, namely pattern repeatability, that quantifies the repetition of patterns in the style image. Based on the pattern repeatability, we propose Aesthetic Pattern-Aware style transfer Networks (AesPA-Net) that discover the sweet spot of local and global style expressions. In addition, we propose a novel self-supervisory task to encourage the attention mechanism to learn precise and meaningful semantic correspondence. Lastly, we introduce the patch-wise style loss to transfer the elaborate rhythm of local patterns. Through qualitative and quantitative evaluations, we verify the reliability of the proposed pattern repeatability that aligns with human perception, and demonstrate the superiority of the proposed framework.
Magnitude Attention-based Dynamic Pruning
Jun 08, 2023



Existing pruning methods utilize the importance of each weight based on specified criteria only when searching for a sparse structure but do not utilize it during training. In this work, we propose a novel approach - \textbf{M}agnitude \textbf{A}ttention-based Dynamic \textbf{P}runing (MAP) method, which applies the importance of weights throughout both the forward and backward paths to explore sparse model structures dynamically. Magnitude attention is defined based on the magnitude of weights as continuous real-valued numbers enabling a seamless transition from a redundant to an effective sparse network by promoting efficient exploration. Additionally, the attention mechanism ensures more effective updates for important layers within the sparse network. In later stages of training, our approach shifts from exploration to exploitation, exclusively updating the sparse model composed of crucial weights based on the explored structure, resulting in pruned models that not only achieve performance comparable to dense models but also outperform previous pruning methods on CIFAR-10/100 and ImageNet.
DiffBlender: Scalable and Composable Multimodal Text-to-Image Diffusion Models
May 24, 2023The recent progress in diffusion-based text-to-image generation models has significantly expanded generative capabilities via conditioning the text descriptions. However, since relying solely on text prompts is still restrictive for fine-grained customization, we aim to extend the boundaries of conditional generation to incorporate diverse types of modalities, e.g., sketch, box, and style embedding, simultaneously. We thus design a multimodal text-to-image diffusion model, coined as DiffBlender, that achieves the aforementioned goal in a single model by training only a few small hypernetworks. DiffBlender facilitates a convenient scaling of input modalities, without altering the parameters of an existing large-scale generative model to retain its well-established knowledge. Furthermore, our study sets new standards for multimodal generation by conducting quantitative and qualitative comparisons with existing approaches. By diversifying the channels of conditioning modalities, DiffBlender faithfully reflects the provided information or, in its absence, creates imaginative generation.
LPMM: Intuitive Pose Control for Neural Talking-Head Model via Landmark-Parameter Morphable Model
May 17, 2023



While current talking head models are capable of generating photorealistic talking head videos, they provide limited pose controllability. Most methods require specific video sequences that should exactly contain the head pose desired, being far from user-friendly pose control. Three-dimensional morphable models (3DMM) offer semantic pose control, but they fail to capture certain expressions. We present a novel method that utilizes parametric control of head orientation and facial expression over a pre-trained neural-talking head model. To enable this, we introduce a landmark-parameter morphable model (LPMM), which offers control over the facial landmark domain through a set of semantic parameters. Using LPMM, it is possible to adjust specific head pose factors, without distorting other facial attributes. The results show our approach provides intuitive rig-like control over neural talking head models, allowing both parameter and image-based inputs.
Interactive Cartoonization with Controllable Perceptual Factors
Dec 19, 2022

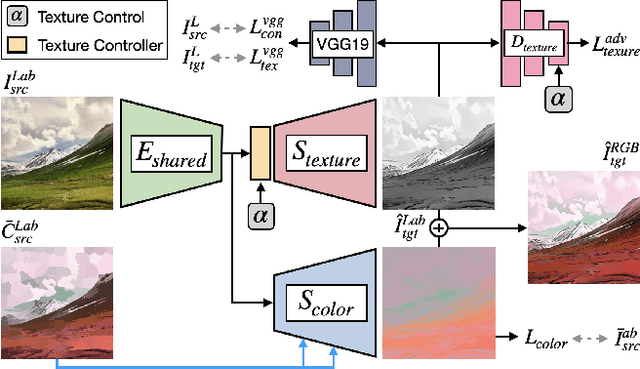
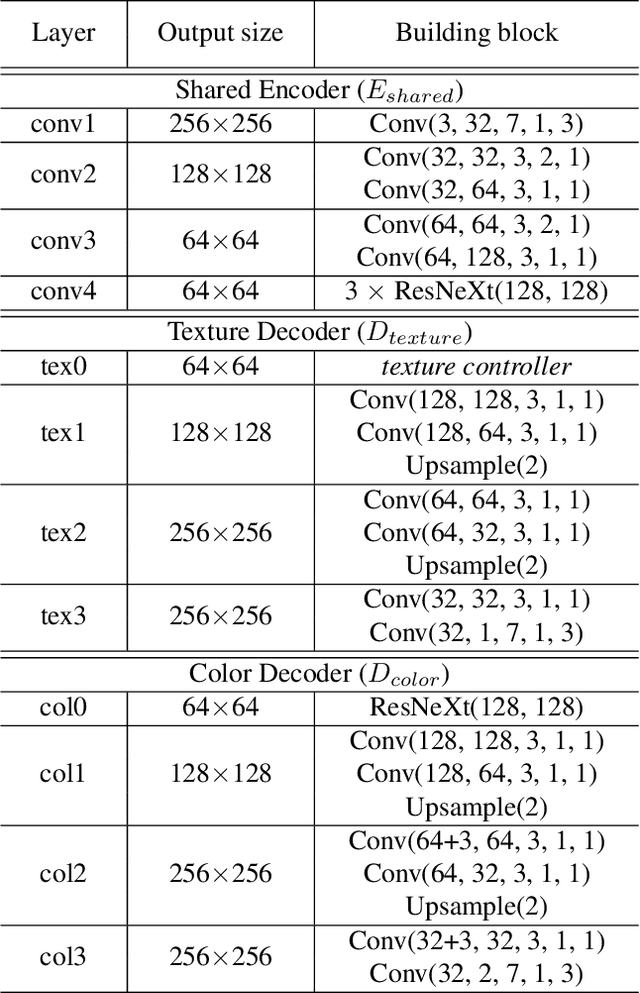
Cartoonization is a task that renders natural photos into cartoon styles. Previous deep cartoonization methods only have focused on end-to-end translation, which may hinder editability. Instead, we propose a novel solution with editing features of texture and color based on the cartoon creation process. To do that, we design a model architecture to have separate decoders, texture and color, to decouple these attributes. In the texture decoder, we propose a texture controller, which enables a user to control stroke style and abstraction to generate diverse cartoon textures. We also introduce an HSV color augmentation to induce the networks to generate diverse and controllable color translation. To the best of our knowledge, our work is the first deep approach to control the cartoonization at inference while showing profound quality improvement over to baselines.
WebtoonMe: A Data-Centric Approach for Full-Body Portrait Stylization
Oct 19, 2022
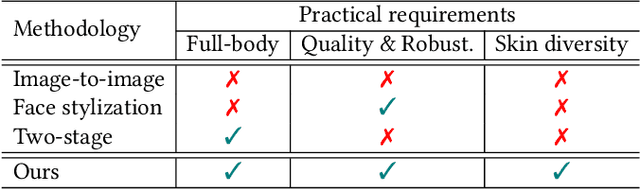
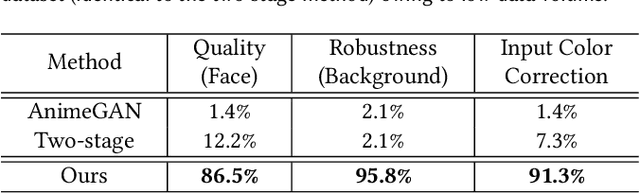
Full-body portrait stylization, which aims to translate portrait photography into a cartoon style, has drawn attention recently. However, most methods have focused only on converting face regions, restraining the feasibility of use in real-world applications. A recently proposed two-stage method expands the rendering area to full bodies, but the outputs are less plausible and fail to achieve quality robustness of non-face regions. Furthermore, they cannot reflect diverse skin tones. In this study, we propose a data-centric solution to build a production-level full-body portrait stylization system. Based on the two-stage scheme, we construct a novel and advanced dataset preparation paradigm that can effectively resolve the aforementioned problems. Experiments reveal that with our pipeline, high-quality portrait stylization can be achieved without additional losses or architectural changes.
Cross-Domain Style Mixing for Face Cartoonization
May 25, 2022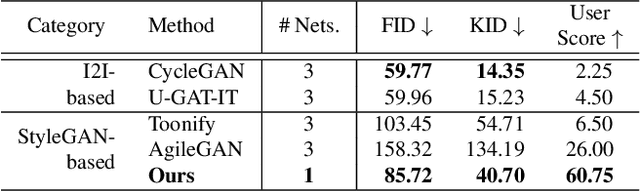

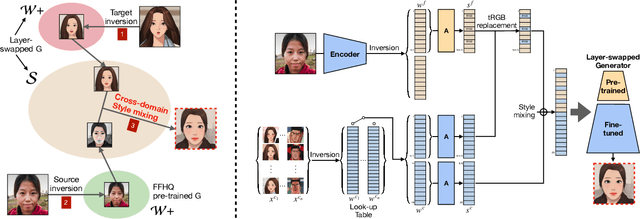
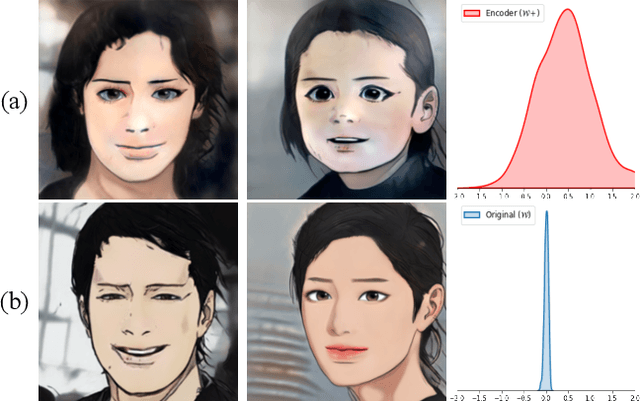
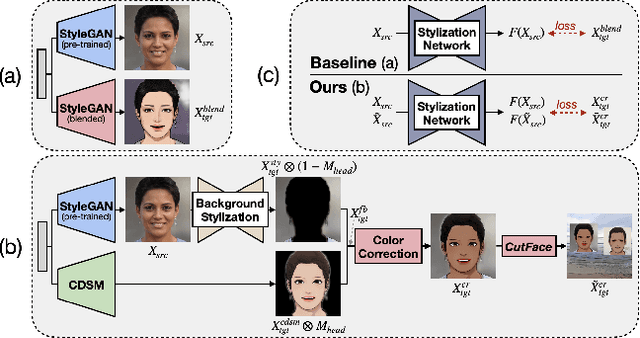
Cartoon domain has recently gained increasing popularity. Previous studies have attempted quality portrait stylization into the cartoon domain; however, this poses a great challenge since they have not properly addressed the critical constraints, such as requiring a large number of training images or the lack of support for abstract cartoon faces. Recently, a layer swapping method has been used for stylization requiring only a limited number of training images; however, its use cases are still narrow as it inherits the remaining issues. In this paper, we propose a novel method called Cross-domain Style mixing, which combines two latent codes from two different domains. Our method effectively stylizes faces into multiple cartoon characters at various face abstraction levels using only a single generator without even using a large number of training images.