 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Relevance to Authority: Authority-aware Generative Retrieval in Web Search Engines
Apr 15, 2026Generative information retrieval (GenIR) formulates the retrieval process as a text-to-text generation task, leveraging the vast knowledge of large language models. However, existing works primarily optimize for relevance while often overlooking document trustworthiness. This is critical in high-stakes domains like healthcare and finance, where relying solely on semantic relevance risks retrieving unreliable information. To address this, we propose an Authority-aware Generative Retriever (AuthGR), the first framework that incorporates authority into GenIR. AuthGR consists of three key components: (i) Multimodal Authority Scoring, which employs a vision-language model to quantify authority from textual and visual cues; (ii) a Three-stage Training Pipeline to progressively instill authority awareness into the retriever; and (iii) a Hybrid Ensemble Pipeline for robust deployment. Offline evaluations demonstrate that AuthGR successfully enhances both authority and accuracy, with our 3B model matching a 14B baseline. Crucially, large-scale online A/B tests and human evaluations conducted on the commercial web search platform confirm significant improvements in real-world user engagement and reliability.
QUPID: Quantified Understanding for Enhanced Performance, Insights, and Decisions in Korean Search Engines
May 12, 2025Large language models (LLMs) have been widely used for relevance assessment in information retrieval. However, our study demonstrates that combining two distinct small language models (SLMs) with different architectures can outperform LLMs in this task. Our approach -- QUPID -- integrates a generative SLM with an embedding-based SLM, achieving higher relevance judgment accuracy while reducing computational costs compared to state-of-the-art LLM solutions. This computational efficiency makes QUPID highly scalable for real-world search systems processing millions of queries daily. In experiments across diverse document types, our method demonstrated consistent performance improvements (Cohen's Kappa of 0.646 versus 0.387 for leading LLMs) while offering 60x faster inference times. Furthermore, when integrated into production search pipelines, QUPID improved nDCG@5 scores by 1.9%. These findings underscore how architectural diversity in model combinations can significantly enhance both search relevance and operational efficiency in information retrieval systems.
Magnitude Attention-based Dynamic Pruning
Jun 08, 2023



Existing pruning methods utilize the importance of each weight based on specified criteria only when searching for a sparse structure but do not utilize it during training. In this work, we propose a novel approach - \textbf{M}agnitude \textbf{A}ttention-based Dynamic \textbf{P}runing (MAP) method, which applies the importance of weights throughout both the forward and backward paths to explore sparse model structures dynamically. Magnitude attention is defined based on the magnitude of weights as continuous real-valued numbers enabling a seamless transition from a redundant to an effective sparse network by promoting efficient exploration. Additionally, the attention mechanism ensures more effective updates for important layers within the sparse network. In later stages of training, our approach shifts from exploration to exploitation, exclusively updating the sparse model composed of crucial weights based on the explored structure, resulting in pruned models that not only achieve performance comparable to dense models but also outperform previous pruning methods on CIFAR-10/100 and ImageNet.
Interactive Cartoonization with Controllable Perceptual Factors
Dec 19, 2022

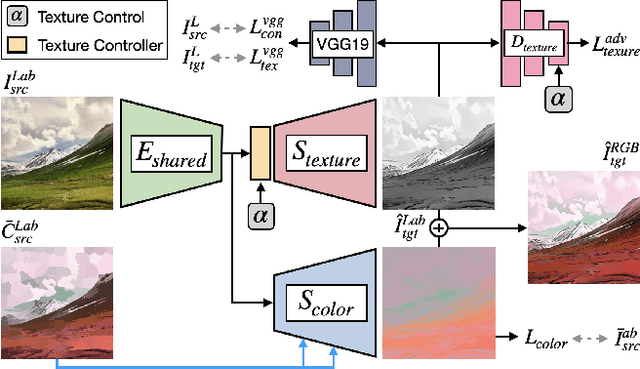
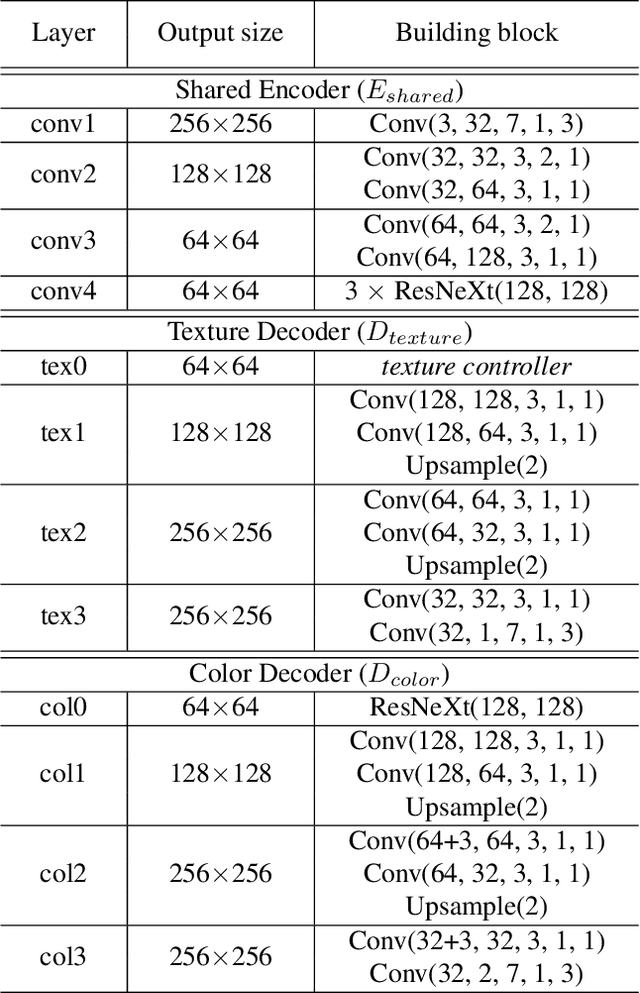
Cartoonization is a task that renders natural photos into cartoon styles. Previous deep cartoonization methods only have focused on end-to-end translation, which may hinder editability. Instead, we propose a novel solution with editing features of texture and color based on the cartoon creation process. To do that, we design a model architecture to have separate decoders, texture and color, to decouple these attributes. In the texture decoder, we propose a texture controller, which enables a user to control stroke style and abstraction to generate diverse cartoon textures. We also introduce an HSV color augmentation to induce the networks to generate diverse and controllable color translation. To the best of our knowledge, our work is the first deep approach to control the cartoonization at inference while showing profound quality improvement over to baselines.
WebtoonMe: A Data-Centric Approach for Full-Body Portrait Stylization
Oct 19, 2022
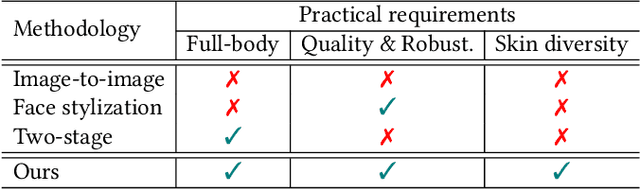
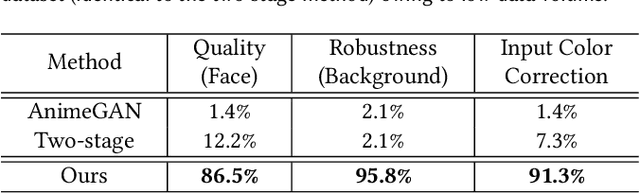
Full-body portrait stylization, which aims to translate portrait photography into a cartoon style, has drawn attention recently. However, most methods have focused only on converting face regions, restraining the feasibility of use in real-world applications. A recently proposed two-stage method expands the rendering area to full bodies, but the outputs are less plausible and fail to achieve quality robustness of non-face regions. Furthermore, they cannot reflect diverse skin tones. In this study, we propose a data-centric solution to build a production-level full-body portrait stylization system. Based on the two-stage scheme, we construct a novel and advanced dataset preparation paradigm that can effectively resolve the aforementioned problems. Experiments reveal that with our pipeline, high-quality portrait stylization can be achieved without additional losses or architectural changes.
Cross-Domain Style Mixing for Face Cartoonization
May 25, 2022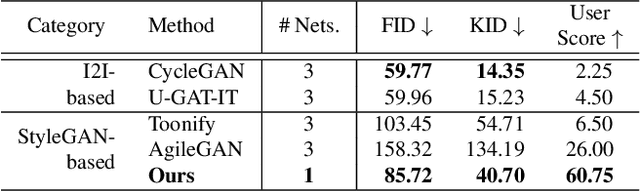

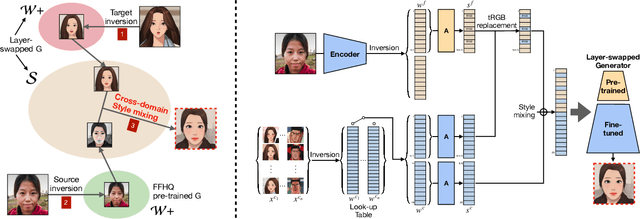
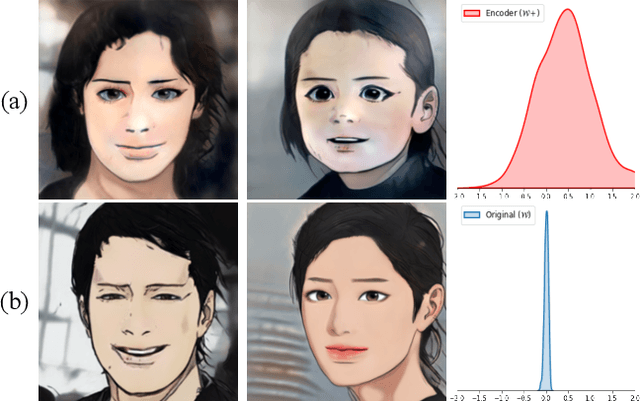
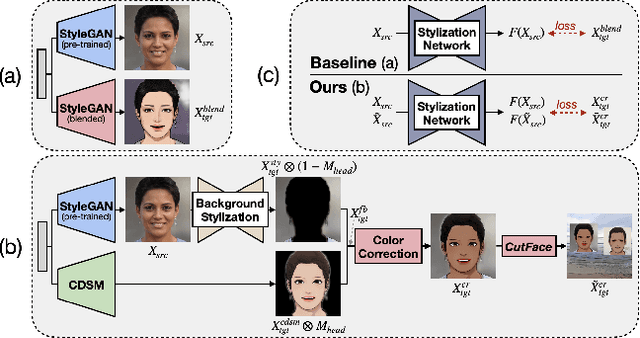
Cartoon domain has recently gained increasing popularity. Previous studies have attempted quality portrait stylization into the cartoon domain; however, this poses a great challenge since they have not properly addressed the critical constraints, such as requiring a large number of training images or the lack of support for abstract cartoon faces. Recently, a layer swapping method has been used for stylization requiring only a limited number of training images; however, its use cases are still narrow as it inherits the remaining issues. In this paper, we propose a novel method called Cross-domain Style mixing, which combines two latent codes from two different domains. Our method effectively stylizes faces into multiple cartoon characters at various face abstraction levels using only a single generator without even using a large number of training images.
Fine-Tuning StyleGAN2 For Cartoon Face Generation
Jun 22, 2021



Recent studies have shown remarkable success in the unsupervised image to image (I2I) translation. However, due to the imbalance in the data, learning joint distribution for various domains is still very challenging. Although existing models can generate realistic target images, it's difficult to maintain the structure of the source image. In addition, training a generative model on large data in multiple domains requires a lot of time and computer resources. To address these limitations, we propose a novel image-to-image translation method that generates images of the target domain by finetuning a stylegan2 pretrained model. The stylegan2 model is suitable for unsupervised I2I translation on unbalanced datasets; it is highly stable, produces realistic images, and even learns properly from limited data when applied with simple fine-tuning techniques. Thus, in this paper, we propose new methods to preserve the structure of the source images and generate realistic images in the target domain. The code and results are available at https://github.com/happy-jihye/Cartoon-StyleGan2