 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFall Risk and Gait Analysis in Community-Dwelling Older Adults using World-Spaced 3D Human Mesh Recovery
Apr 13, 2026Gait assessment is a key clinical indicator of fall risk and overall health in older adults. However, standard clinical practice is largely limited to stopwatch-measured gait speed. We present a pipeline that leverages a 3D Human Mesh Recovery (HMR) model to extract gait parameters from recordings of older adults completing the Timed Up and Go (TUG) test. From videos recorded across different community centers, we extract and analyze spatiotemporal gait parameters, including step time, sit-to-stand duration, and step length. We found that video-derived step time was significantly correlated with IMU-based insole measurements. Using linear mixed effects models, we confirmed that shorter, more variable step lengths and longer sit-to-stand durations were predicted by higher self-rated fall risk and fear of falling. These findings demonstrate that our pipeline can enable accessible and ecologically valid gait analysis in community settings.
GraspDiffusion: Synthesizing Realistic Whole-body Hand-Object Interaction
Oct 17, 2024



Recent generative models can synthesize high-quality images but often fail to generate humans interacting with objects using their hands. This arises mostly from the model's misunderstanding of such interactions, and the hardships of synthesizing intricate regions of the body. In this paper, we propose GraspDiffusion, a novel generative method that creates realistic scenes of human-object interaction. Given a 3D object mesh, GraspDiffusion first constructs life-like whole-body poses with control over the object's location relative to the human body. This is achieved by separately leveraging the generative priors for 3D body and hand poses, optimizing them into a joint grasping pose. The resulting pose guides the image synthesis to correctly reflect the intended interaction, allowing the creation of realistic and diverse human-object interaction scenes. We demonstrate that GraspDiffusion can successfully tackle the relatively uninvestigated problem of generating full-bodied human-object interactions while outperforming previous methods. Code and models will be available at https://webtoon.github.io/GraspDiffusion
Zero-Shot Learning for the Primitives of 3D Affordance in General Objects
Jan 24, 2024



One of the major challenges in AI is teaching machines to precisely respond and utilize environmental functionalities, thereby achieving the affordance awareness that humans possess. Despite its importance, the field has been lagging in terms of learning, especially in 3D, as annotating affordance accompanies a laborious process due to the numerous variations of human-object interaction. The low availability of affordance data limits the learning in terms of generalization for object categories, and also simplifies the representation of affordance, capturing only a fraction of the affordance. To overcome these challenges, we propose a novel, self-supervised method to generate the 3D affordance examples given only a 3D object, without any manual annotations. The method starts by capturing the 3D object into images and creating 2D affordance images by inserting humans into the image via inpainting diffusion models, where we present the Adaptive Mask algorithm to enable human insertion without altering the original details of the object. The method consequently lifts inserted humans back to 3D to create 3D human-object pairs, where the depth ambiguity is resolved within a depth optimization framework that utilizes pre-generated human postures from multiple viewpoints. We also provide a novel affordance representation defined on relative orientations and proximity between dense human and object points, that can be easily aggregated from any 3D HOI datasets. The proposed representation serves as a primitive that can be manifested to conventional affordance representations via simple transformations, ranging from physically exerted affordances to nonphysical ones. We demonstrate the efficacy of our method and representation by generating the 3D affordance samples and deriving high-quality affordance examples from the representation, including contact, orientation, and spatial occupancies.
Chupa: Carving 3D Clothed Humans from Skinned Shape Priors using 2D Diffusion Probabilistic Models
May 19, 2023



We propose a 3D generation pipeline that uses diffusion models to generate realistic human digital avatars. Due to the wide variety of human identities, poses, and stochastic details, the generation of 3D human meshes has been a challenging problem. To address this, we decompose the problem into 2D normal map generation and normal map-based 3D reconstruction. Specifically, we first simultaneously generate realistic normal maps for the front and backside of a clothed human, dubbed dual normal maps, using a pose-conditional diffusion model. For 3D reconstruction, we ``carve'' the prior SMPL-X mesh to a detailed 3D mesh according to the normal maps through mesh optimization. To further enhance the high-frequency details, we present a diffusion resampling scheme on both body and facial regions, thus encouraging the generation of realistic digital avatars. We also seamlessly incorporate a recent text-to-image diffusion model to support text-based human identity control. Our method, namely, Chupa, is capable of generating realistic 3D clothed humans with better perceptual quality and identity variety.
LPMM: Intuitive Pose Control for Neural Talking-Head Model via Landmark-Parameter Morphable Model
May 17, 2023



While current talking head models are capable of generating photorealistic talking head videos, they provide limited pose controllability. Most methods require specific video sequences that should exactly contain the head pose desired, being far from user-friendly pose control. Three-dimensional morphable models (3DMM) offer semantic pose control, but they fail to capture certain expressions. We present a novel method that utilizes parametric control of head orientation and facial expression over a pre-trained neural-talking head model. To enable this, we introduce a landmark-parameter morphable model (LPMM), which offers control over the facial landmark domain through a set of semantic parameters. Using LPMM, it is possible to adjust specific head pose factors, without distorting other facial attributes. The results show our approach provides intuitive rig-like control over neural talking head models, allowing both parameter and image-based inputs.
Interactive Cartoonization with Controllable Perceptual Factors
Dec 19, 2022

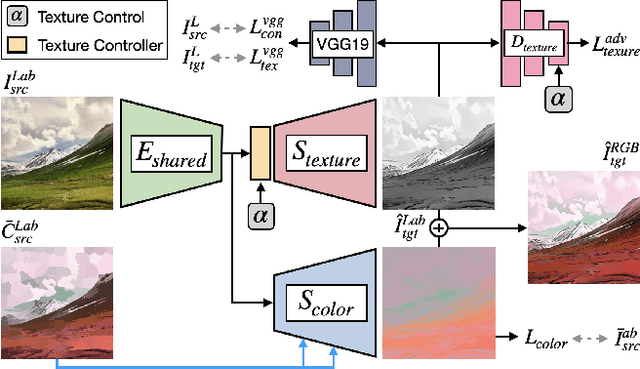
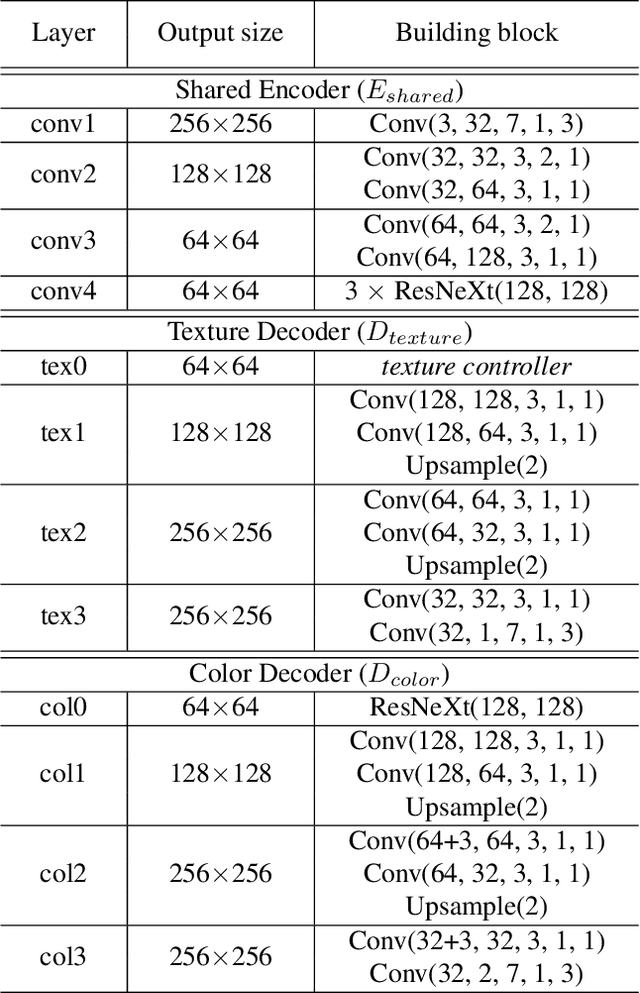
Cartoonization is a task that renders natural photos into cartoon styles. Previous deep cartoonization methods only have focused on end-to-end translation, which may hinder editability. Instead, we propose a novel solution with editing features of texture and color based on the cartoon creation process. To do that, we design a model architecture to have separate decoders, texture and color, to decouple these attributes. In the texture decoder, we propose a texture controller, which enables a user to control stroke style and abstraction to generate diverse cartoon textures. We also introduce an HSV color augmentation to induce the networks to generate diverse and controllable color translation. To the best of our knowledge, our work is the first deep approach to control the cartoonization at inference while showing profound quality improvement over to baselines.
KoDF: A Large-scale Korean DeepFake Detection Dataset
Mar 18, 2021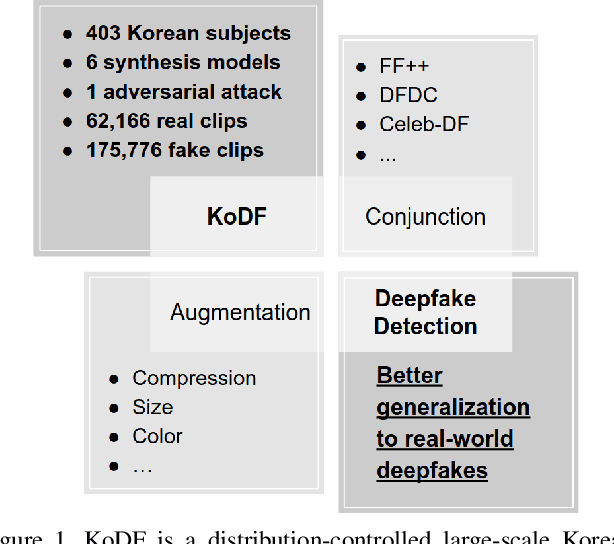
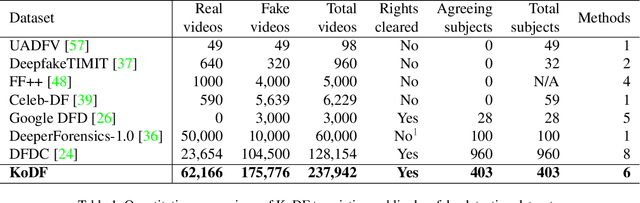
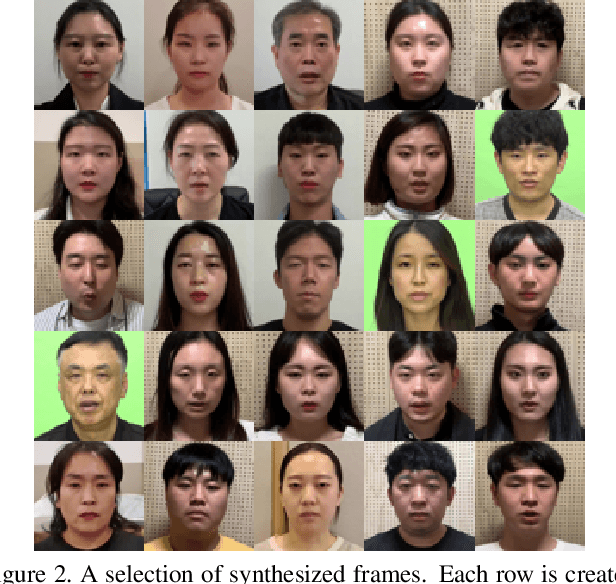
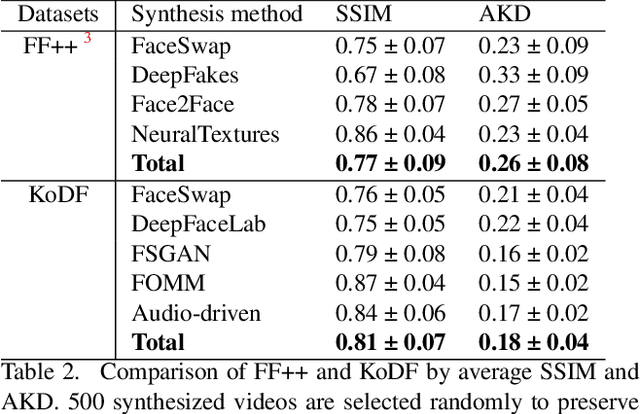
A variety of effective face-swap and face-reenactment methods have been publicized in recent years, democratizing the face synthesis technology to a great extent. Videos generated as such have come to be collectively called deepfakes with a negative connotation, for various social problems they have caused. Facing the emerging threat of deepfakes, we have built the Korean DeepFake Detection Dataset (KoDF), a large-scale collection of synthesized and real videos focused on Korean subjects. In this paper, we provide a detailed description of methods used to construct the dataset, experimentally show the discrepancy between the distributions of KoDF and existing deepfake detection datasets, and underline the importance of using multiple datasets for real-world generalization. KoDF is publicly available at https://moneybrain-research.github.io/kodf in its entirety (i.e. real clips, synthesized clips, clips with additive noise, and their corresponding metadata).