 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Textual Inversion for Personalized Text-to-Image Generation
Dec 15, 2025Textual Inversion (TI) is an efficient approach to text-to-image personalization but often fails on complex prompts. We trace these failures to embedding norm inflation: learned tokens drift to out-of-distribution magnitudes, degrading prompt conditioning in pre-norm Transformers. Empirically, we show semantics are primarily encoded by direction in CLIP token space, while inflated norms harm contextualization; theoretically, we analyze how large magnitudes attenuate positional information and hinder residual updates in pre-norm blocks. We propose Directional Textual Inversion (DTI), which fixes the embedding magnitude to an in-distribution scale and optimizes only direction on the unit hypersphere via Riemannian SGD. We cast direction learning as MAP with a von Mises-Fisher prior, yielding a constant-direction prior gradient that is simple and efficient to incorporate. Across personalization tasks, DTI improves text fidelity over TI and TI-variants while maintaining subject similarity. Crucially, DTI's hyperspherical parameterization enables smooth, semantically coherent interpolation between learned concepts (slerp), a capability that is absent in standard TI. Our findings suggest that direction-only optimization is a robust and scalable path for prompt-faithful personalization.
GC-Fed: Gradient Centralized Federated Learning with Partial Client Participation
Mar 17, 2025Multi-source information fusion (MSIF) leverages diverse data streams to enhance decision-making, situational awareness, and system resilience. Federated Learning (FL) enables MSIF while preserving privacy but suffers from client drift under high data heterogeneity, leading to performance degradation. Traditional mitigation strategies rely on reference-based gradient adjustments, which can be unstable in partial participation settings. To address this, we propose Gradient Centralized Federated Learning (GC-Fed), a reference-free gradient correction method inspired by Gradient Centralization (GC). We introduce Local GC and Global GC, applying GC during local training and global aggregation, respectively. Our hybrid GC-Fed approach selectively applies GC at the feature extraction layer locally and at the classifier layer globally, improving training stability and model performance. Theoretical analysis and empirical results demonstrate that GC-Fed mitigates client drift and achieves state-of-the-art accuracy gains of up to 20% in heterogeneous settings.
ConTEXTure: Consistent Multiview Images to Texture
Jul 15, 2024We introduce ConTEXTure, a generative network designed to create a texture map/atlas for a given 3D mesh using images from multiple viewpoints. The process begins with generating a front-view image from a text prompt, such as 'Napoleon, front view', describing the 3D mesh. Additional images from different viewpoints are derived from this front-view image and camera poses relative to it. ConTEXTure builds upon the TEXTure network, which uses text prompts for six viewpoints (e.g., 'Napoleon, front view', 'Napoleon, left view', etc.). However, TEXTure often generates images for non-front viewpoints that do not accurately represent those viewpoints.To address this issue, we employ Zero123++, which generates multiple view-consistent images for the six specified viewpoints simultaneously, conditioned on the initial front-view image and the depth maps of the mesh for the six viewpoints. By utilizing these view-consistent images, ConTEXTure learns the texture atlas from all viewpoint images concurrently, unlike previous methods that do so sequentially. This approach ensures that the rendered images from various viewpoints, including back, side, bottom, and top, are free from viewpoint irregularities.
DreamStyler: Paint by Style Inversion with Text-to-Image Diffusion Models
Sep 13, 2023Recent progresses in large-scale text-to-image models have yielded remarkable accomplishments, finding various applications in art domain. However, expressing unique characteristics of an artwork (e.g. brushwork, colortone, or composition) with text prompts alone may encounter limitations due to the inherent constraints of verbal description. To this end, we introduce DreamStyler, a novel framework designed for artistic image synthesis, proficient in both text-to-image synthesis and style transfer. DreamStyler optimizes a multi-stage textual embedding with a context-aware text prompt, resulting in prominent image quality. In addition, with content and style guidance, DreamStyler exhibits flexibility to accommodate a range of style references. Experimental results demonstrate its superior performance across multiple scenarios, suggesting its promising potential in artistic product creation.
Improving Diversity in Zero-Shot GAN Adaptation with Semantic Variations
Aug 21, 2023Training deep generative models usually requires a large amount of data. To alleviate the data collection cost, the task of zero-shot GAN adaptation aims to reuse well-trained generators to synthesize images of an unseen target domain without any further training samples. Due to the data absence, the textual description of the target domain and the vision-language models, e.g., CLIP, are utilized to effectively guide the generator. However, with only a single representative text feature instead of real images, the synthesized images gradually lose diversity as the model is optimized, which is also known as mode collapse. To tackle the problem, we propose a novel method to find semantic variations of the target text in the CLIP space. Specifically, we explore diverse semantic variations based on the informative text feature of the target domain while regularizing the uncontrolled deviation of the semantic information. With the obtained variations, we design a novel directional moment loss that matches the first and second moments of image and text direction distributions. Moreover, we introduce elastic weight consolidation and a relation consistency loss to effectively preserve valuable content information from the source domain, e.g., appearances. Through extensive experiments, we demonstrate the efficacy of the proposed methods in ensuring sample diversity in various scenarios of zero-shot GAN adaptation. We also conduct ablation studies to validate the effect of each proposed component. Notably, our model achieves a new state-of-the-art on zero-shot GAN adaptation in terms of both diversity and quality.
AesPA-Net: Aesthetic Pattern-Aware Style Transfer Networks
Aug 08, 2023To deliver the artistic expression of the target style, recent studies exploit the attention mechanism owing to its ability to map the local patches of the style image to the corresponding patches of the content image. However, because of the low semantic correspondence between arbitrary content and artworks, the attention module repeatedly abuses specific local patches from the style image, resulting in disharmonious and evident repetitive artifacts. To overcome this limitation and accomplish impeccable artistic style transfer, we focus on enhancing the attention mechanism and capturing the rhythm of patterns that organize the style. In this paper, we introduce a novel metric, namely pattern repeatability, that quantifies the repetition of patterns in the style image. Based on the pattern repeatability, we propose Aesthetic Pattern-Aware style transfer Networks (AesPA-Net) that discover the sweet spot of local and global style expressions. In addition, we propose a novel self-supervisory task to encourage the attention mechanism to learn precise and meaningful semantic correspondence. Lastly, we introduce the patch-wise style loss to transfer the elaborate rhythm of local patterns. Through qualitative and quantitative evaluations, we verify the reliability of the proposed pattern repeatability that aligns with human perception, and demonstrate the superiority of the proposed framework.
DiffBlender: Scalable and Composable Multimodal Text-to-Image Diffusion Models
May 24, 2023The recent progress in diffusion-based text-to-image generation models has significantly expanded generative capabilities via conditioning the text descriptions. However, since relying solely on text prompts is still restrictive for fine-grained customization, we aim to extend the boundaries of conditional generation to incorporate diverse types of modalities, e.g., sketch, box, and style embedding, simultaneously. We thus design a multimodal text-to-image diffusion model, coined as DiffBlender, that achieves the aforementioned goal in a single model by training only a few small hypernetworks. DiffBlender facilitates a convenient scaling of input modalities, without altering the parameters of an existing large-scale generative model to retain its well-established knowledge. Furthermore, our study sets new standards for multimodal generation by conducting quantitative and qualitative comparisons with existing approaches. By diversifying the channels of conditioning modalities, DiffBlender faithfully reflects the provided information or, in its absence, creates imaginative generation.
Interactive Cartoonization with Controllable Perceptual Factors
Dec 19, 2022

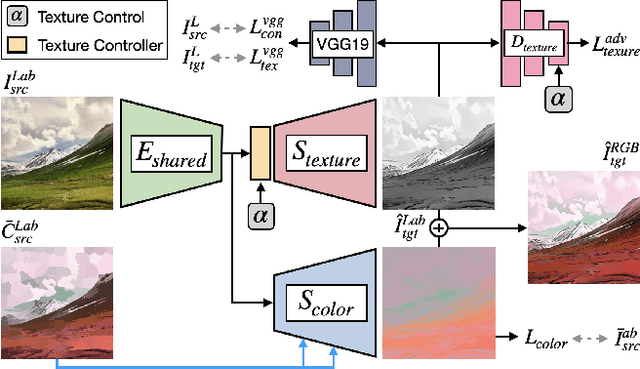
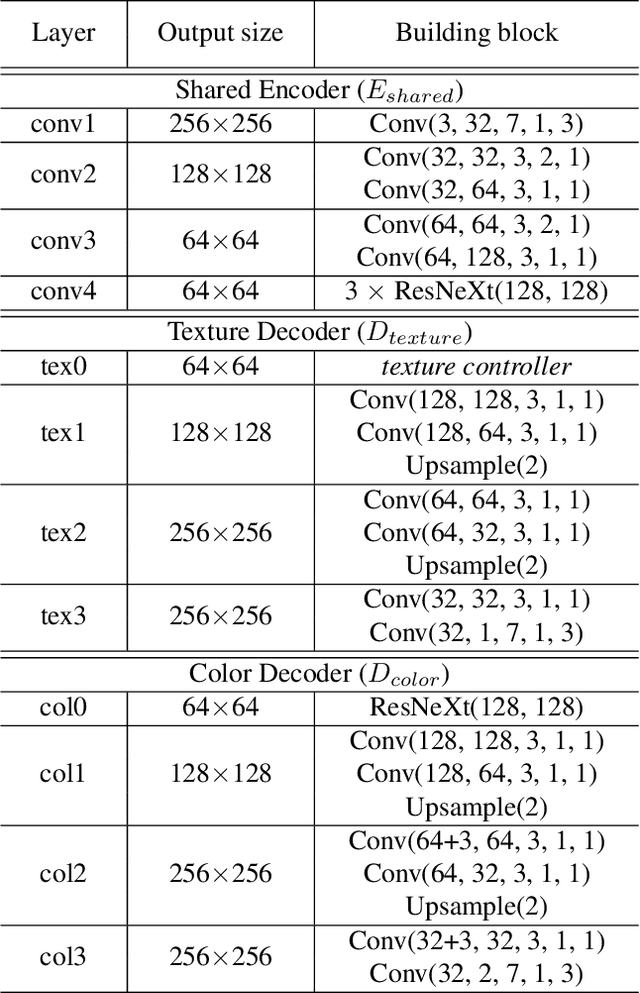
Cartoonization is a task that renders natural photos into cartoon styles. Previous deep cartoonization methods only have focused on end-to-end translation, which may hinder editability. Instead, we propose a novel solution with editing features of texture and color based on the cartoon creation process. To do that, we design a model architecture to have separate decoders, texture and color, to decouple these attributes. In the texture decoder, we propose a texture controller, which enables a user to control stroke style and abstraction to generate diverse cartoon textures. We also introduce an HSV color augmentation to induce the networks to generate diverse and controllable color translation. To the best of our knowledge, our work is the first deep approach to control the cartoonization at inference while showing profound quality improvement over to baselines.
Exploiting Domain Transferability for Collaborative Inter-level Domain Adaptive Object Detection
Jul 20, 2022
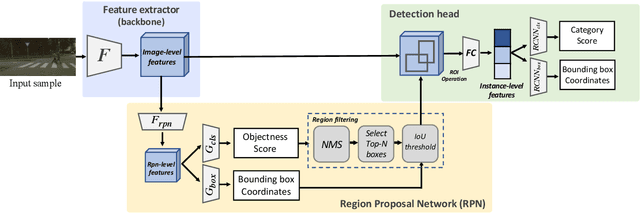
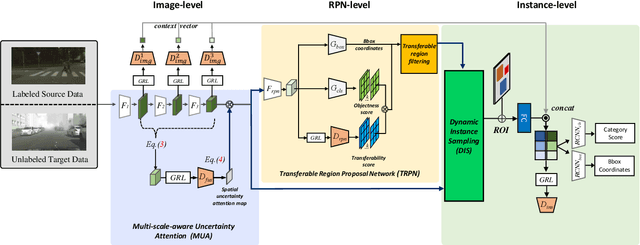
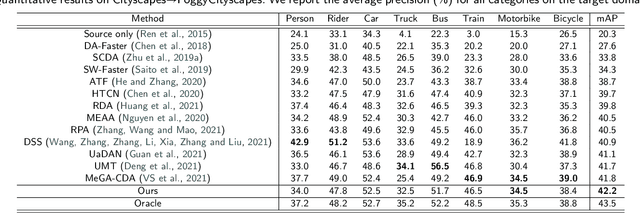
Domain adaptation for object detection (DAOD) has recently drawn much attention owing to its capability of detecting target objects without any annotations. To tackle the problem, previous works focus on aligning features extracted from partial levels (e.g., image-level, instance-level, RPN-level) in a two-stage detector via adversarial training. However, individual levels in the object detection pipeline are closely related to each other and this inter-level relation is unconsidered yet. To this end, we introduce a novel framework for DAOD with three proposed components: Multi-scale-aware Uncertainty Attention (MUA), Transferable Region Proposal Network (TRPN), and Dynamic Instance Sampling (DIS). With these modules, we seek to reduce the negative transfer effect during training while maximizing transferability as well as discriminability in both domains. Finally, our framework implicitly learns domain invariant regions for object detection via exploiting the transferable information and enhances the complementarity between different detection levels by collaboratively utilizing their domain information. Through ablation studies and experiments, we show that the proposed modules contribute to the performance improvement in a synergic way, demonstrating the effectiveness of our method. Moreover, our model achieves a new state-of-the-art performance on various benchmarks.
* Accepted to Expert Systems with Applications. The first three authors contributed equally
Feature Stylization and Domain-aware Contrastive Learning for Domain Generalization
Aug 19, 2021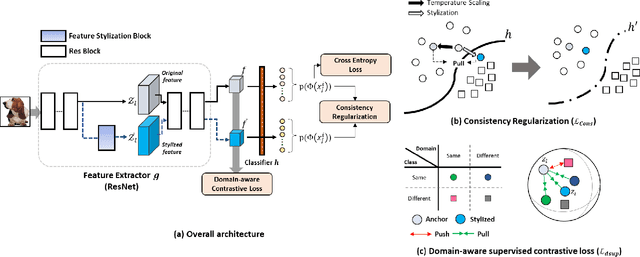
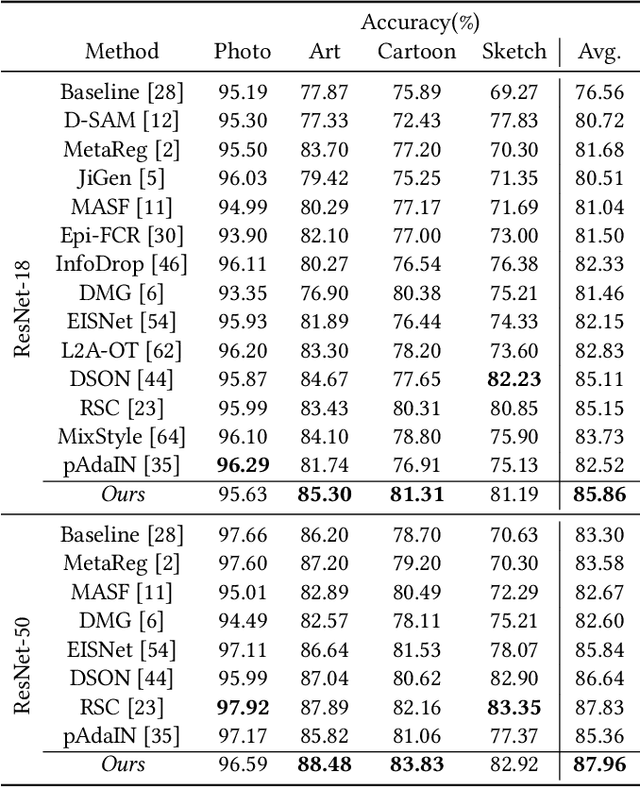
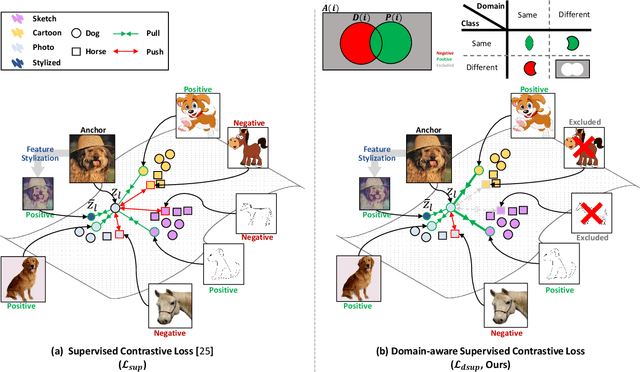
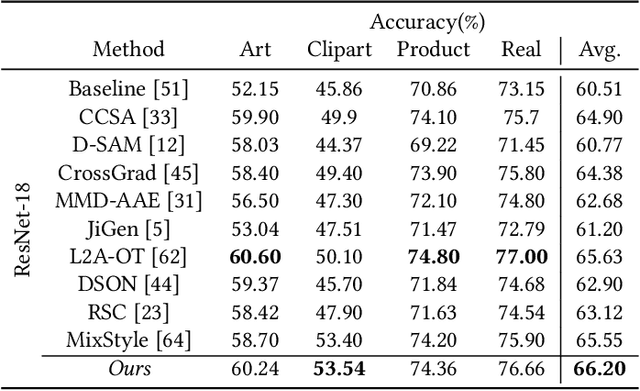
Domain generalization aims to enhance the model robustness against domain shift without accessing the target domain. Since the available source domains for training are limited, recent approaches focus on generating samples of novel domains. Nevertheless, they either struggle with the optimization problem when synthesizing abundant domains or cause the distortion of class semantics. To these ends, we propose a novel domain generalization framework where feature statistics are utilized for stylizing original features to ones with novel domain properties. To preserve class information during stylization, we first decompose features into high and low frequency components. Afterward, we stylize the low frequency components with the novel domain styles sampled from the manipulated statistics, while preserving the shape cues in high frequency ones. As the final step, we re-merge both components to synthesize novel domain features. To enhance domain robustness, we utilize the stylized features to maintain the model consistency in terms of features as well as outputs. We achieve the feature consistency with the proposed domain-aware supervised contrastive loss, which ensures domain invariance while increasing class discriminability. Experimental results demonstrate the effectiveness of the proposed feature stylization and the domain-aware contrastive loss. Through quantitative comparisons, we verify the lead of our method upon existing state-of-the-art methods on two benchmarks, PACS and Office-Home.