 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAM-DETR: Boundary-Aligned Moment Detection Transformer for Temporal Sentence Grounding in Videos
Nov 30, 2023Temporal sentence grounding aims to localize moments relevant to a language description. Recently, DETR-like approaches have shown notable progress by decoding the center and length of a target moment from learnable queries. However, they suffer from the issue of center misalignment raised by the inherent ambiguity of moment centers, leading to inaccurate predictions. To remedy this problem, we introduce a novel boundary-oriented moment formulation. In our paradigm, the model no longer needs to find the precise center but instead suffices to predict any anchor point within the interval, from which the onset and offset are directly estimated. Based on this idea, we design a Boundary-Aligned Moment Detection Transformer (BAM-DETR), equipped with a dual-pathway decoding process. Specifically, it refines the anchor and boundaries within parallel pathways using global and boundary-focused attention, respectively. This separate design allows the model to focus on desirable regions, enabling precise refinement of moment predictions. Further, we propose a quality-based ranking method, ensuring that proposals with high localization qualities are prioritized over incomplete ones. Extensive experiments verify the advantages of our methods, where our model records new state-of-the-art results on three benchmarks. Code is at https://github.com/Pilhyeon/BAM-DETR.
Small Objects Matters in Weakly-supervised Semantic Segmentation
Sep 25, 2023Weakly-supervised semantic segmentation (WSSS) performs pixel-wise classification given only image-level labels for training. Despite the difficulty of this task, the research community has achieved promising results over the last five years. Still, current WSSS literature misses the detailed sense of how well the methods perform on different sizes of objects. Thus we propose a novel evaluation metric to provide a comprehensive assessment across different object sizes and collect a size-balanced evaluation set to complement PASCAL VOC. With these two gadgets, we reveal that the existing WSSS methods struggle in capturing small objects. Furthermore, we propose a size-balanced cross-entropy loss coupled with a proper training strategy. It generally improves existing WSSS methods as validated upon ten baselines on three different datasets.
Improving Diversity in Zero-Shot GAN Adaptation with Semantic Variations
Aug 21, 2023Training deep generative models usually requires a large amount of data. To alleviate the data collection cost, the task of zero-shot GAN adaptation aims to reuse well-trained generators to synthesize images of an unseen target domain without any further training samples. Due to the data absence, the textual description of the target domain and the vision-language models, e.g., CLIP, are utilized to effectively guide the generator. However, with only a single representative text feature instead of real images, the synthesized images gradually lose diversity as the model is optimized, which is also known as mode collapse. To tackle the problem, we propose a novel method to find semantic variations of the target text in the CLIP space. Specifically, we explore diverse semantic variations based on the informative text feature of the target domain while regularizing the uncontrolled deviation of the semantic information. With the obtained variations, we design a novel directional moment loss that matches the first and second moments of image and text direction distributions. Moreover, we introduce elastic weight consolidation and a relation consistency loss to effectively preserve valuable content information from the source domain, e.g., appearances. Through extensive experiments, we demonstrate the efficacy of the proposed methods in ensuring sample diversity in various scenarios of zero-shot GAN adaptation. We also conduct ablation studies to validate the effect of each proposed component. Notably, our model achieves a new state-of-the-art on zero-shot GAN adaptation in terms of both diversity and quality.
AesPA-Net: Aesthetic Pattern-Aware Style Transfer Networks
Aug 08, 2023To deliver the artistic expression of the target style, recent studies exploit the attention mechanism owing to its ability to map the local patches of the style image to the corresponding patches of the content image. However, because of the low semantic correspondence between arbitrary content and artworks, the attention module repeatedly abuses specific local patches from the style image, resulting in disharmonious and evident repetitive artifacts. To overcome this limitation and accomplish impeccable artistic style transfer, we focus on enhancing the attention mechanism and capturing the rhythm of patterns that organize the style. In this paper, we introduce a novel metric, namely pattern repeatability, that quantifies the repetition of patterns in the style image. Based on the pattern repeatability, we propose Aesthetic Pattern-Aware style transfer Networks (AesPA-Net) that discover the sweet spot of local and global style expressions. In addition, we propose a novel self-supervisory task to encourage the attention mechanism to learn precise and meaningful semantic correspondence. Lastly, we introduce the patch-wise style loss to transfer the elaborate rhythm of local patterns. Through qualitative and quantitative evaluations, we verify the reliability of the proposed pattern repeatability that aligns with human perception, and demonstrate the superiority of the proposed framework.
Decomposed Cross-modal Distillation for RGB-based Temporal Action Detection
Mar 30, 2023
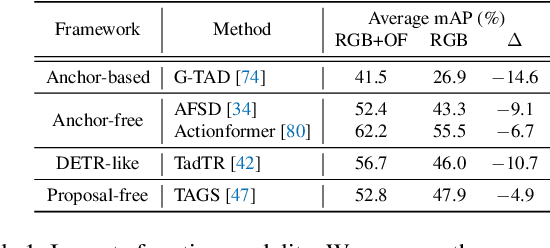

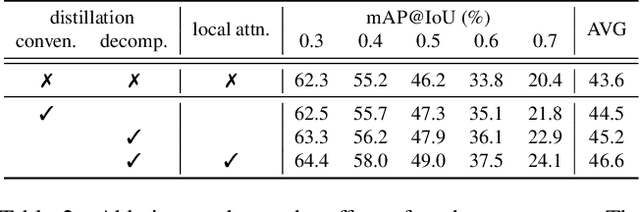
Temporal action detection aims to predict the time intervals and the classes of action instances in the video. Despite the promising performance, existing two-stream models exhibit slow inference speed due to their reliance on computationally expensive optical flow. In this paper, we introduce a decomposed cross-modal distillation framework to build a strong RGB-based detector by transferring knowledge of the motion modality. Specifically, instead of direct distillation, we propose to separately learn RGB and motion representations, which are in turn combined to perform action localization. The dual-branch design and the asymmetric training objectives enable effective motion knowledge transfer while preserving RGB information intact. In addition, we introduce a local attentive fusion to better exploit the multimodal complementarity. It is designed to preserve the local discriminability of the features that is important for action localization. Extensive experiments on the benchmarks verify the effectiveness of the proposed method in enhancing RGB-based action detectors. Notably, our framework is agnostic to backbones and detection heads, bringing consistent gains across different model combinations.
BallGAN: 3D-aware Image Synthesis with a Spherical Background
Jan 22, 2023



3D-aware GANs aim to synthesize realistic 3D scenes such that they can be rendered in arbitrary perspectives to produce images. Although previous methods produce realistic images, they suffer from unstable training or degenerate solutions where the 3D geometry is unnatural. We hypothesize that the 3D geometry is underdetermined due to the insufficient constraint, i.e., being classified as real image to the discriminator is not enough. To solve this problem, we propose to approximate the background as a spherical surface and represent a scene as a union of the foreground placed in the sphere and the thin spherical background. It reduces the degree of freedom in the background field. Accordingly, we modify the volume rendering equation and incorporate dedicated constraints to design a novel 3D-aware GAN framework named BallGAN. BallGAN has multiple advantages as follows. 1) It produces more reasonable 3D geometry; the images of a scene across different viewpoints have better photometric consistency and fidelity than the state-of-the-art methods. 2) The training becomes much more stable. 3) The foreground can be separately rendered on top of different arbitrary backgrounds.
Source-free Subject Adaptation for EEG-based Visual Recognition
Jan 20, 2023



This paper focuses on subject adaptation for EEG-based visual recognition. It aims at building a visual stimuli recognition system customized for the target subject whose EEG samples are limited, by transferring knowledge from abundant data of source subjects. Existing approaches consider the scenario that samples of source subjects are accessible during training. However, it is often infeasible and problematic to access personal biological data like EEG signals due to privacy issues. In this paper, we introduce a novel and practical problem setup, namely source-free subject adaptation, where the source subject data are unavailable and only the pre-trained model parameters are provided for subject adaptation. To tackle this challenging problem, we propose classifier-based data generation to simulate EEG samples from source subjects using classifier responses. Using the generated samples and target subject data, we perform subject-independent feature learning to exploit the common knowledge shared across different subjects. Notably, our framework is generalizable and can adopt any subject-independent learning method. In the experiments on the EEG-ImageNet40 benchmark, our model brings consistent improvements regardless of the choice of subject-independent learning. Also, our method shows promising performance, recording top-1 test accuracy of 74.6% under the 5-shot setting even without relying on source data. Our code can be found at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Source_Free_Subject_Adaptation_for_EEG.
Exploiting Shape Cues for Weakly Supervised Semantic Segmentation
Aug 08, 2022
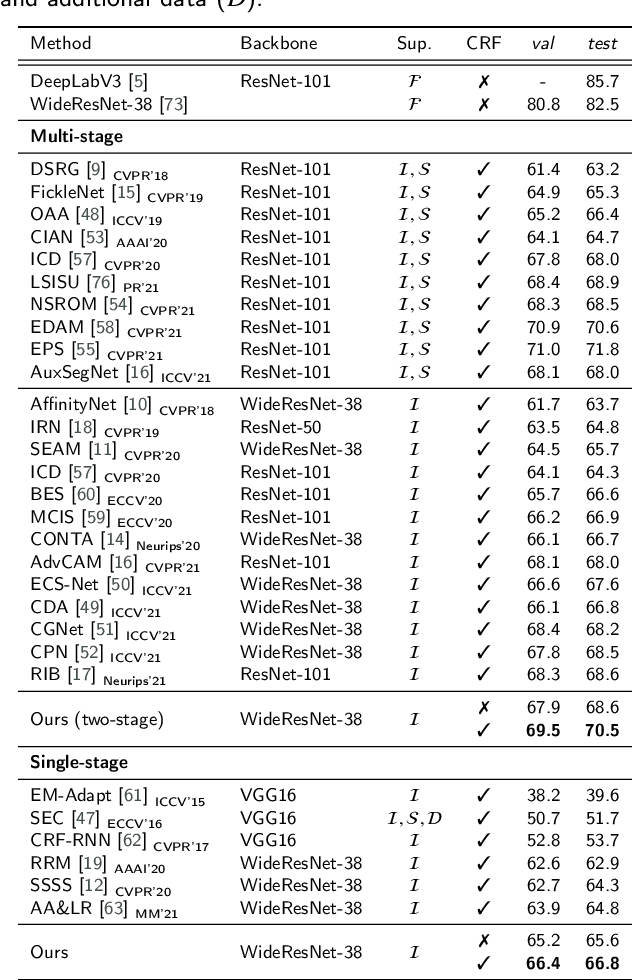
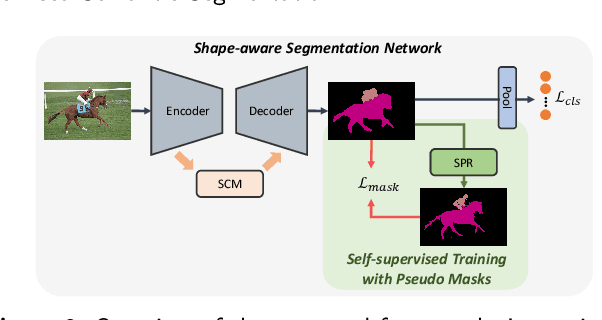
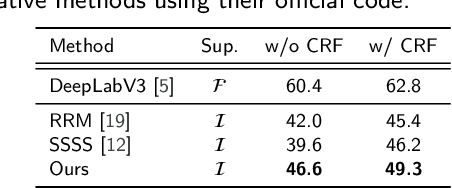
Weakly supervised semantic segmentation (WSSS) aims to produce pixel-wise class predictions with only image-level labels for training. To this end, previous methods adopt the common pipeline: they generate pseudo masks from class activation maps (CAMs) and use such masks to supervise segmentation networks. However, it is challenging to derive comprehensive pseudo masks that cover the whole extent of objects due to the local property of CAMs, i.e., they tend to focus solely on small discriminative object parts. In this paper, we associate the locality of CAMs with the texture-biased property of convolutional neural networks (CNNs). Accordingly, we propose to exploit shape information to supplement the texture-biased CNN features, thereby encouraging mask predictions to be not only comprehensive but also well-aligned with object boundaries. We further refine the predictions in an online fashion with a novel refinement method that takes into account both the class and the color affinities, in order to generate reliable pseudo masks to supervise the model. Importantly, our model is end-to-end trained within a single-stage framework and therefore efficient in terms of the training cost. Through extensive experiments on PASCAL VOC 2012, we validate the effectiveness of our method in producing precise and shape-aligned segmentation results. Specifically, our model surpasses the existing state-of-the-art single-stage approaches by large margins. What is more, it also achieves a new state-of-the-art performance over multi-stage approaches, when adopted in a simple two-stage pipeline without bells and whistles.
* Accepted by Pattern Recognition. The first two authors contributed equally
Exploiting Domain Transferability for Collaborative Inter-level Domain Adaptive Object Detection
Jul 20, 2022
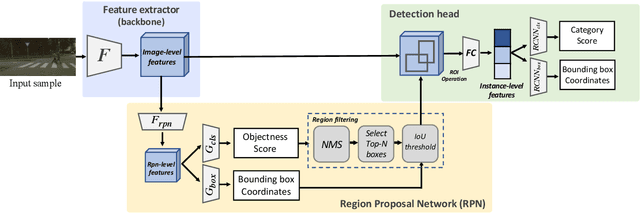
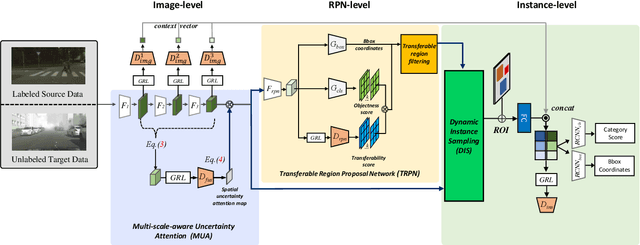
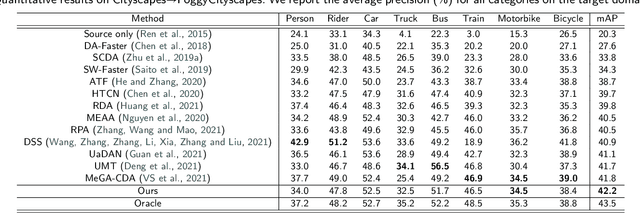
Domain adaptation for object detection (DAOD) has recently drawn much attention owing to its capability of detecting target objects without any annotations. To tackle the problem, previous works focus on aligning features extracted from partial levels (e.g., image-level, instance-level, RPN-level) in a two-stage detector via adversarial training. However, individual levels in the object detection pipeline are closely related to each other and this inter-level relation is unconsidered yet. To this end, we introduce a novel framework for DAOD with three proposed components: Multi-scale-aware Uncertainty Attention (MUA), Transferable Region Proposal Network (TRPN), and Dynamic Instance Sampling (DIS). With these modules, we seek to reduce the negative transfer effect during training while maximizing transferability as well as discriminability in both domains. Finally, our framework implicitly learns domain invariant regions for object detection via exploiting the transferable information and enhances the complementarity between different detection levels by collaboratively utilizing their domain information. Through ablation studies and experiments, we show that the proposed modules contribute to the performance improvement in a synergic way, demonstrating the effectiveness of our method. Moreover, our model achieves a new state-of-the-art performance on various benchmarks.
* Accepted to Expert Systems with Applications. The first three authors contributed equally
Fair Contrastive Learning for Facial Attribute Classification
Mar 30, 2022
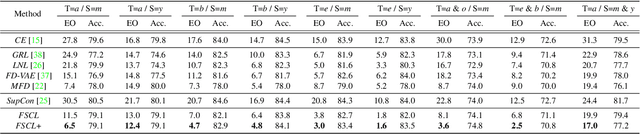
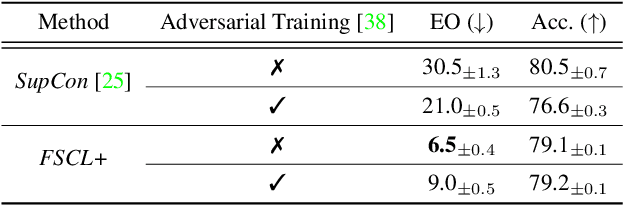
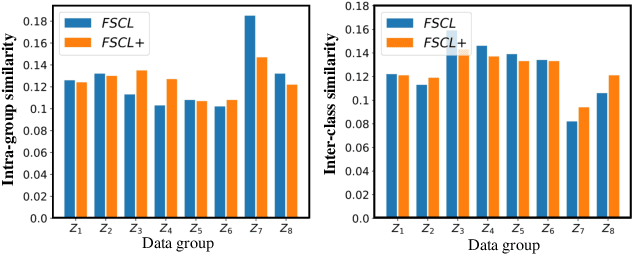
Learning visual representation of high quality is essential for image classification. Recently, a series of contrastive representation learning methods have achieved preeminent success. Particularly, SupCon outperformed the dominant methods based on cross-entropy loss in representation learning. However, we notice that there could be potential ethical risks in supervised contrastive learning. In this paper, we for the first time analyze unfairness caused by supervised contrastive learning and propose a new Fair Supervised Contrastive Loss (FSCL) for fair visual representation learning. Inheriting the philosophy of supervised contrastive learning, it encourages representation of the same class to be closer to each other than that of different classes, while ensuring fairness by penalizing the inclusion of sensitive attribute information in representation. In addition, we introduce a group-wise normalization to diminish the disparities of intra-group compactness and inter-class separability between demographic groups that arouse unfair classification. Through extensive experiments on CelebA and UTK Face, we validate that the proposed method significantly outperforms SupCon and existing state-of-the-art methods in terms of the trade-off between top-1 accuracy and fairness. Moreover, our method is robust to the intensity of data bias and effectively works in incomplete supervised settings. Our code is available at https://github.com/sungho-CoolG/FSCL.