 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2O-SDF: Two-phase Learning for 3D Indoor Reconstruction using Object Surface Fields
Feb 13, 2024Advanced techniques using Neural Radiance Fields (NeRF), Signed Distance Fields (SDF), and Occupancy Fields have recently emerged as solutions for 3D indoor scene reconstruction. We introduce a novel two-phase learning approach, H2O-SDF, that discriminates between object and non-object regions within indoor environments. This method achieves a nuanced balance, carefully preserving the geometric integrity of room layouts while also capturing intricate surface details of specific objects. A cornerstone of our two-phase learning framework is the introduction of the Object Surface Field (OSF), a novel concept designed to mitigate the persistent vanishing gradient problem that has previously hindered the capture of high-frequency details in other methods. Our proposed approach is validated through several experiments that include ablation studies.
Exploiting Domain Transferability for Collaborative Inter-level Domain Adaptive Object Detection
Jul 20, 2022
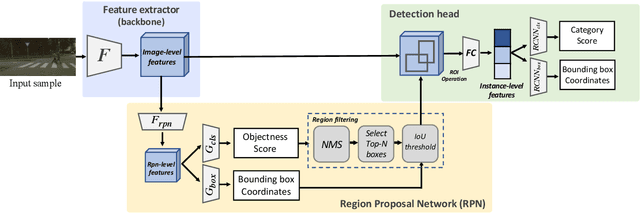
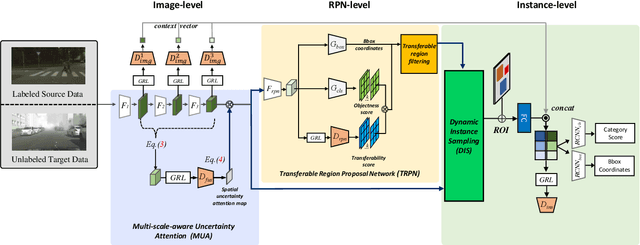
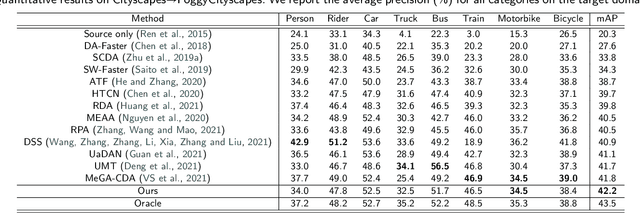
Domain adaptation for object detection (DAOD) has recently drawn much attention owing to its capability of detecting target objects without any annotations. To tackle the problem, previous works focus on aligning features extracted from partial levels (e.g., image-level, instance-level, RPN-level) in a two-stage detector via adversarial training. However, individual levels in the object detection pipeline are closely related to each other and this inter-level relation is unconsidered yet. To this end, we introduce a novel framework for DAOD with three proposed components: Multi-scale-aware Uncertainty Attention (MUA), Transferable Region Proposal Network (TRPN), and Dynamic Instance Sampling (DIS). With these modules, we seek to reduce the negative transfer effect during training while maximizing transferability as well as discriminability in both domains. Finally, our framework implicitly learns domain invariant regions for object detection via exploiting the transferable information and enhances the complementarity between different detection levels by collaboratively utilizing their domain information. Through ablation studies and experiments, we show that the proposed modules contribute to the performance improvement in a synergic way, demonstrating the effectiveness of our method. Moreover, our model achieves a new state-of-the-art performance on various benchmarks.
* Accepted to Expert Systems with Applications. The first three authors contributed equally
FairFaceGAN: Fairness-aware Facial Image-to-Image Translation
Dec 02, 2020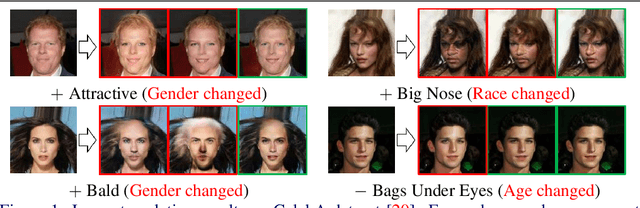
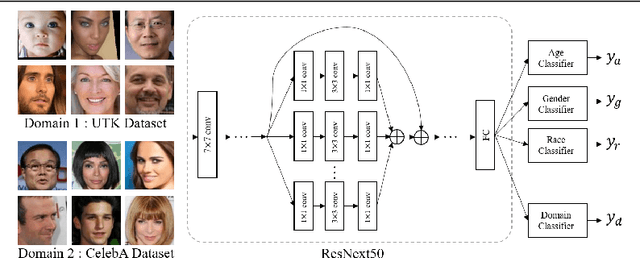

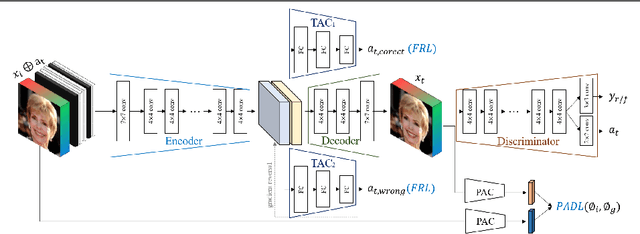
In this paper, we introduce FairFaceGAN, a fairness-aware facial Image-to-Image translation model, mitigating the problem of unwanted translation in protected attributes (e.g., gender, age, race) during facial attributes editing. Unlike existing models, FairFaceGAN learns fair representations with two separate latents - one related to the target attributes to translate, and the other unrelated to them. This strategy enables FairFaceGAN to separate the information about protected attributes and that of target attributes. It also prevents unwanted translation in protected attributes while target attributes editing. To evaluate the degree of fairness, we perform two types of experiments on CelebA dataset. First, we compare the fairness-aware classification performances when augmenting data by existing image translation methods and FairFaceGAN respectively. Moreover, we propose a new fairness metric, namely Frechet Protected Attribute Distance (FPAD), which measures how well protected attributes are preserved. Experimental results demonstrate that FairFaceGAN shows consistent improvements in terms of fairness over the existing image translation models. Further, we also evaluate image translation performances, where FairFaceGAN shows competitive results, compared to those of existing methods.