 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERC: Plan-As-Query Example Retrieval for Underrepresented Code Generation
Dec 17, 2024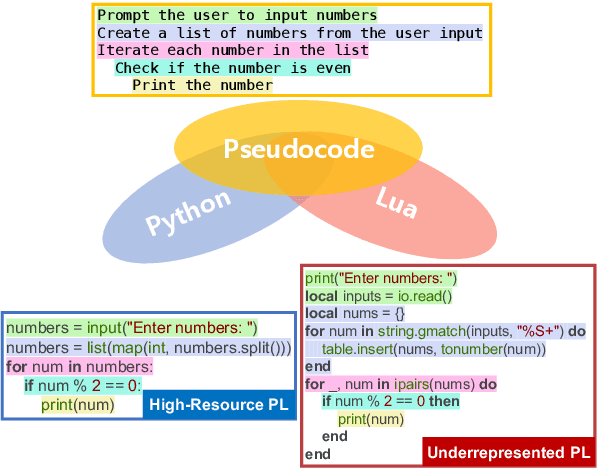
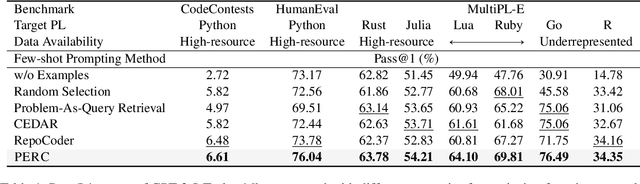
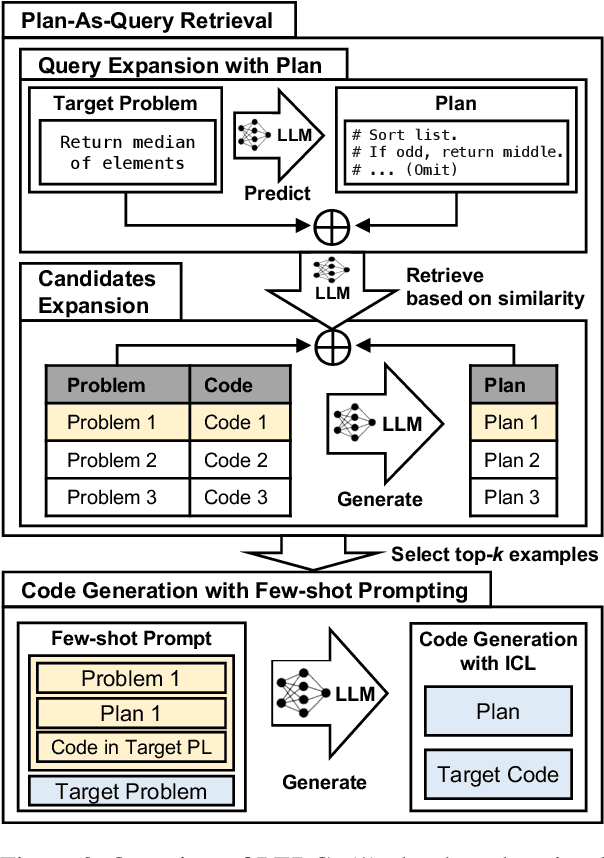
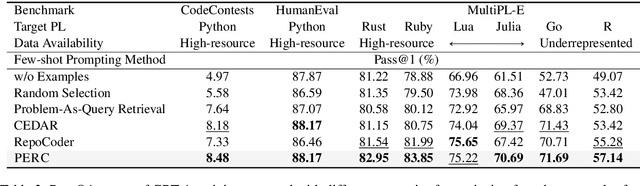
Code generation with large language models has shown significant promise, especially when employing retrieval-augmented generation (RAG) with few-shot examples. However, selecting effective examples that enhance generation quality remains a challenging task, particularly when the target programming language (PL) is underrepresented. In this study, we present two key findings: (1) retrieving examples whose presented algorithmic plans can be referenced for generating the desired behavior significantly improves generation accuracy, and (2) converting code into pseudocode effectively captures such algorithmic plans, enhancing retrieval quality even when the source and the target PLs are different. Based on these findings, we propose Plan-as-query Example Retrieval for few-shot prompting in Code generation (PERC), a novel framework that utilizes algorithmic plans to identify and retrieve effective examples. We validate the effectiveness of PERC through extensive experiments on the CodeContests, HumanEval and MultiPL-E benchmarks: PERC consistently outperforms the state-of-the-art RAG methods in code generation, both when the source and target programming languages match or differ, highlighting its adaptability and robustness in diverse coding environments.
ArchCode: Incorporating Software Requirements in Code Generation with Large Language Models
Aug 02, 2024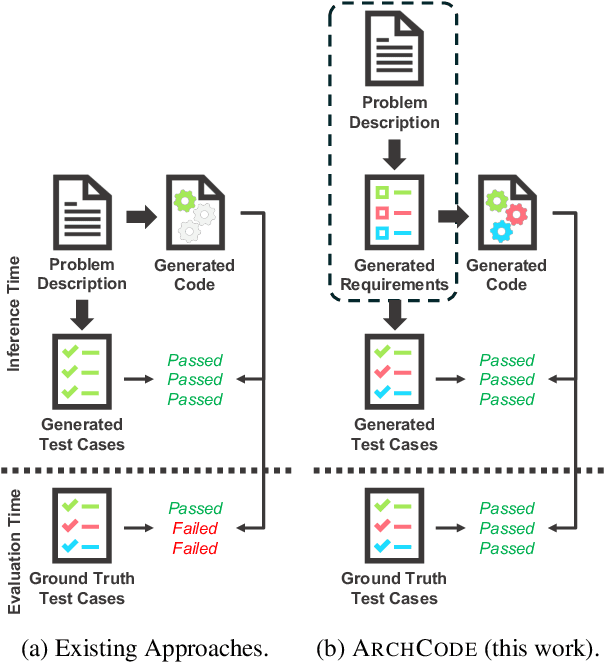



This paper aims to extend the code generation capability of large language models (LLMs) to automatically manage comprehensive software requirements from given textual descriptions. Such requirements include both functional (i.e. achieving expected behavior for inputs) and non-functional (e.g., time/space performance, robustness, maintainability) requirements. However, textual descriptions can either express requirements verbosely or may even omit some of them. We introduce ARCHCODE, a novel framework that leverages in-context learning to organize requirements observed in descriptions and to extrapolate unexpressed requirements from them. ARCHCODE generates requirements from given descriptions, conditioning them to produce code snippets and test cases. Each test case is tailored to one of the requirements, allowing for the ranking of code snippets based on the compliance of their execution results with the requirements. Public benchmarks show that ARCHCODE enhances to satisfy functional requirements, significantly improving Pass@k scores. Furthermore, we introduce HumanEval-NFR, the first evaluation of LLMs' non-functional requirements in code generation, demonstrating ARCHCODE's superiority over baseline methods. The implementation of ARCHCODE and the HumanEval-NFR benchmark are both publicly accessible.
H2O-SDF: Two-phase Learning for 3D Indoor Reconstruction using Object Surface Fields
Feb 13, 2024Advanced techniques using Neural Radiance Fields (NeRF), Signed Distance Fields (SDF), and Occupancy Fields have recently emerged as solutions for 3D indoor scene reconstruction. We introduce a novel two-phase learning approach, H2O-SDF, that discriminates between object and non-object regions within indoor environments. This method achieves a nuanced balance, carefully preserving the geometric integrity of room layouts while also capturing intricate surface details of specific objects. A cornerstone of our two-phase learning framework is the introduction of the Object Surface Field (OSF), a novel concept designed to mitigate the persistent vanishing gradient problem that has previously hindered the capture of high-frequency details in other methods. Our proposed approach is validated through several experiments that include ablation studies.