 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuET: Dual Execution for Test Output Prediction with Generated Code and Pseudocode
Apr 13, 2026This work addresses test output prediction, a key challenge in test case generation. To improve the reliability of predicted outputs by LLMs, prior approaches generate code first to ground predictions. One grounding strategy is direct execution of generated code, but even minor errors can cause failures. To address this, we introduce LLM-based pseudocode execution, which grounds prediction on more error-resilient pseudocode and simulates execution via LLM reasoning. We further propose DuET, a dual-execution framework that combines both approaches by functional majority voting. Our analysis shows the two approaches are complementary in overcoming the limitations of direct execution suffering from code errors, and pseudocode reasoning from hallucination. On LiveCodeBench, DuET achieves the state-of-the-art performance, improving Pass@1 by 13.6 pp.
Can David Beat Goliath? On Multi-Hop Reasoning with Resource-Constrained Agents
Jan 29, 2026While reinforcement learning (RL) has empowered multi-turn reasoning agents with retrieval and tools, existing successes largely depend on extensive on-policy rollouts in high-cost, high-accuracy regimes. Under realistic resource constraints that cannot support large models or dense explorations, however, small language model agents fall into a low-cost, low-accuracy regime, where limited rollout budgets lead to sparse exploration, sparse credit assignment, and unstable training. In this work, we challenge this trade-off and show that small language models can achieve strong multi-hop reasoning under resource constraints. We introduce DAVID-GRPO, a budget-efficient RL framework that (i) stabilizes early learning with minimal supervision, (ii) assigns retrieval credit based on evidence recall, and (iii) improves exploration by resampling truncated near-miss trajectories. Evaluated on agents up to 1.5B parameters trained on only four RTX 3090 GPUs, DAVID-GRPO consistently outperforms prior RL methods designed for large-scale settings on six multi-hop QA benchmarks. These results show that with the right inductive biases, small agents can achieve low training cost with high accuracy.
ConvCodeWorld: Benchmarking Conversational Code Generation in Reproducible Feedback Environments
Feb 27, 2025Large language models (LLMs) have proven invaluable for code generation, particularly in interactive settings. However, existing code generation benchmarks fail to capture the diverse feedback encountered in multi-turn interactions, limiting our ability to evaluate LLMs in these contexts. To address this gap, we present a set of novel benchmarks that explicitly model the quality of feedback provided to code generation LLMs. Our contributions are threefold: First, we introduce CONVCODEWORLD, a novel and reproducible environment for benchmarking interactive code generation. CONVCODEWORLD simulates 9 distinct interactive code generation scenarios while systematically combining three types of feedback: (a) compilation feedback; (b) execution feedback with varying test coverage; (c) verbal feedback generated by GPT-4o with different levels of expertise. Second, we introduce CONVCODEBENCH, a fast, static version of benchmark that uses pre-generated feedback logs, eliminating the need for costly dynamic verbal feedback generation while maintaining strong Spearman's rank correlations (0.82 to 0.99) with CONVCODEWORLD. Third, extensive evaluations of both closed-source and open-source LLMs including R1-Distill on CONVCODEWORLD reveal key insights: (a) LLM performance varies significantly based on the feedback provided; (b) Weaker LLMs, with sufficient feedback, can outperform single-turn results of state-of-the-art LLMs without feedback; (c) Training on a specific feedback combination can limit an LLM's ability to utilize unseen combinations; (d) LLMs solve problems in fewer turns (high MRR) may not solve as many problems overall (high Recall), and vice versa. All implementations and benchmarks will be made publicly available at https://huggingface.co/spaces/ConvCodeWorld/ConvCodeWorld
PERC: Plan-As-Query Example Retrieval for Underrepresented Code Generation
Dec 17, 2024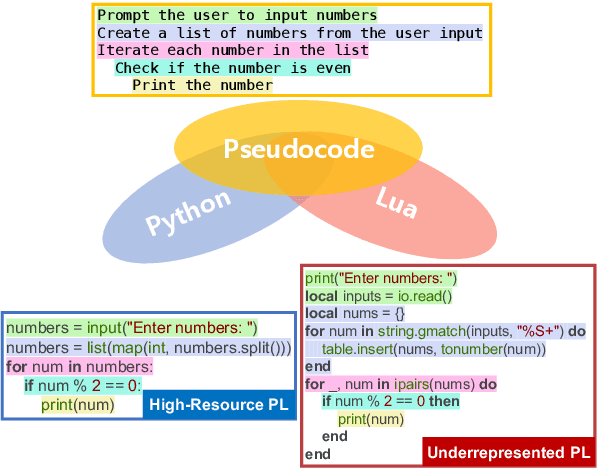
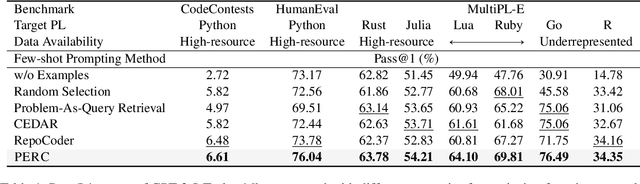
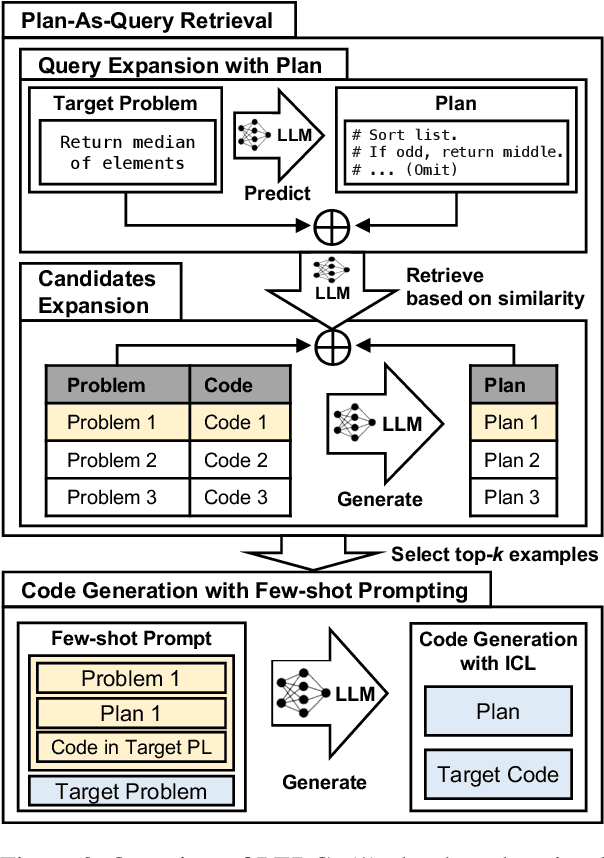
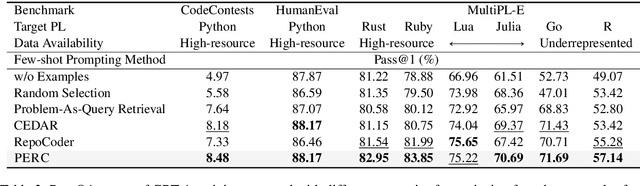
Code generation with large language models has shown significant promise, especially when employing retrieval-augmented generation (RAG) with few-shot examples. However, selecting effective examples that enhance generation quality remains a challenging task, particularly when the target programming language (PL) is underrepresented. In this study, we present two key findings: (1) retrieving examples whose presented algorithmic plans can be referenced for generating the desired behavior significantly improves generation accuracy, and (2) converting code into pseudocode effectively captures such algorithmic plans, enhancing retrieval quality even when the source and the target PLs are different. Based on these findings, we propose Plan-as-query Example Retrieval for few-shot prompting in Code generation (PERC), a novel framework that utilizes algorithmic plans to identify and retrieve effective examples. We validate the effectiveness of PERC through extensive experiments on the CodeContests, HumanEval and MultiPL-E benchmarks: PERC consistently outperforms the state-of-the-art RAG methods in code generation, both when the source and target programming languages match or differ, highlighting its adaptability and robustness in diverse coding environments.
Arctic-SnowCoder: Demystifying High-Quality Data in Code Pretraining
Sep 03, 2024



Recent studies have been increasingly demonstrating that high-quality data is crucial for effective pretraining of language models. However, the precise definition of "high-quality" remains underexplored. Focusing on the code domain, we introduce Arctic-SnowCoder-1.3B, a data-efficient base code model pretrained on 555B tokens through three phases of progressively refined data: (1) general pretraining with 500B standard-quality code tokens, preprocessed through basic filtering, deduplication, and decontamination, (2) continued pretraining with 50B high-quality tokens, selected from phase one by a BERT-style quality annotator trained to distinguish good code from random data, using positive examples drawn from high-quality code files, along with instruction data from Magicoder and StarCoder2-Instruct, and (3) enhanced pretraining with 5B synthetic data created by Llama-3.1-70B using phase two data as seeds, adapting the Magicoder approach for pretraining. Despite being trained on a limited dataset, Arctic-SnowCoder achieves state-of-the-art performance on BigCodeBench, a coding benchmark focusing on practical and challenging programming tasks, compared to similarly sized models trained on no more than 1T tokens, outperforming Phi-1.5-1.3B by 36%. Across all evaluated benchmarks, Arctic-SnowCoder-1.3B beats StarCoderBase-3B pretrained on 1T tokens. Additionally, it matches the performance of leading small base code models trained on trillions of tokens. For example, Arctic-SnowCoder-1.3B surpasses StarCoder2-3B, pretrained on over 3.3T tokens, on HumanEval+, a benchmark that evaluates function-level code generation, and remains competitive on BigCodeBench. Our evaluation presents a comprehensive analysis justifying various design choices for Arctic-SnowCoder. Most importantly, we find that the key to high-quality data is its alignment with the distribution of downstream applications.
ArchCode: Incorporating Software Requirements in Code Generation with Large Language Models
Aug 02, 2024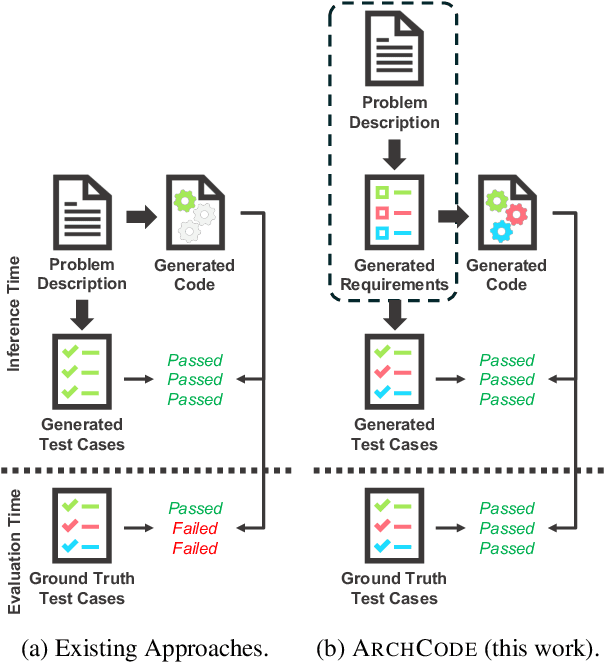



This paper aims to extend the code generation capability of large language models (LLMs) to automatically manage comprehensive software requirements from given textual descriptions. Such requirements include both functional (i.e. achieving expected behavior for inputs) and non-functional (e.g., time/space performance, robustness, maintainability) requirements. However, textual descriptions can either express requirements verbosely or may even omit some of them. We introduce ARCHCODE, a novel framework that leverages in-context learning to organize requirements observed in descriptions and to extrapolate unexpressed requirements from them. ARCHCODE generates requirements from given descriptions, conditioning them to produce code snippets and test cases. Each test case is tailored to one of the requirements, allowing for the ranking of code snippets based on the compliance of their execution results with the requirements. Public benchmarks show that ARCHCODE enhances to satisfy functional requirements, significantly improving Pass@k scores. Furthermore, we introduce HumanEval-NFR, the first evaluation of LLMs' non-functional requirements in code generation, demonstrating ARCHCODE's superiority over baseline methods. The implementation of ARCHCODE and the HumanEval-NFR benchmark are both publicly accessible.
ReACC: A Retrieval-Augmented Code Completion Framework
Mar 15, 2022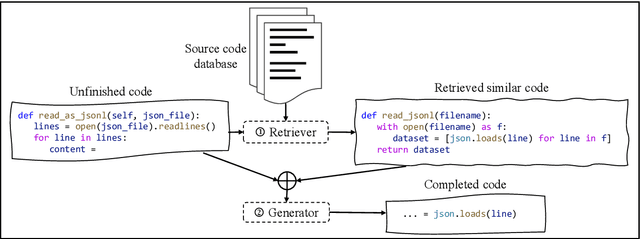

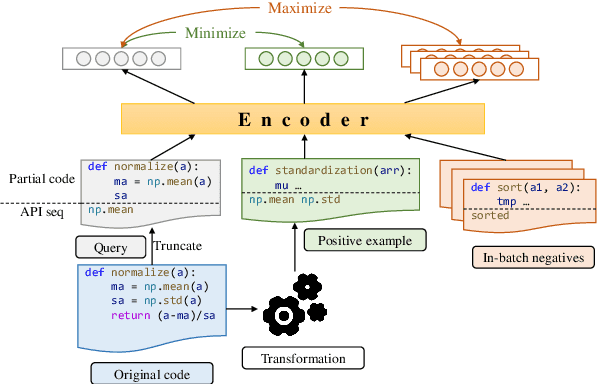
Code completion, which aims to predict the following code token(s) according to the code context, can improve the productivity of software development. Recent work has proved that statistical language modeling with transformers can greatly improve the performance in the code completion task via learning from large-scale source code datasets. However, current approaches focus only on code context within the file or project, i.e. internal context. Our distinction is utilizing "external" context, inspired by human behaviors of copying from the related code snippets when writing code. Specifically, we propose a retrieval-augmented code completion framework, leveraging both lexical copying and referring to code with similar semantics by retrieval. We adopt a stage-wise training approach that combines a source code retriever and an auto-regressive language model for programming language. We evaluate our approach in the code completion task in Python and Java programming languages, achieving a state-of-the-art performance on CodeXGLUE benchmark.