 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloneMem: Benchmarking Long-Term Memory for AI Clones
Jan 11, 2026AI Clones aim to simulate an individual's thoughts and behaviors to enable long-term, personalized interaction, placing stringent demands on memory systems to model experiences, emotions, and opinions over time. Existing memory benchmarks primarily rely on user-agent conversational histories, which are temporally fragmented and insufficient for capturing continuous life trajectories. We introduce CloneMem, a benchmark for evaluating longterm memory in AI Clone scenarios grounded in non-conversational digital traces, including diaries, social media posts, and emails, spanning one to three years. CloneMem adopts a hierarchical data construction framework to ensure longitudinal coherence and defines tasks that assess an agent's ability to track evolving personal states. Experiments show that current memory mechanisms struggle in this setting, highlighting open challenges for life-grounded personalized AI. Code and dataset are available at https://github.com/AvatarMemory/CloneMemBench
Does Memory Need Graphs? A Unified Framework and Empirical Analysis for Long-Term Dialog Memory
Jan 07, 2026Graph structures are increasingly used in dialog memory systems, but empirical findings on their effectiveness remain inconsistent, making it unclear which design choices truly matter. We present an experimental, system-oriented analysis of long-term dialog memory architectures. We introduce a unified framework that decomposes dialog memory systems into core components and supports both graph-based and non-graph approaches. Under this framework, we conduct controlled, stage-wise experiments on LongMemEval and HaluMem, comparing common design choices in memory representation, organization, maintenance, and retrieval. Our results show that many performance differences are driven by foundational system settings rather than specific architectural innovations. Based on these findings, we identify stable and reliable strong baselines for future dialog memory research.
Toward Training Superintelligent Software Agents through Self-Play SWE-RL
Dec 21, 2025While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.
Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?
Nov 17, 2025



Large Language Models (LLMs) are reshaping almost all industries, including software engineering. In recent years, a number of LLM agents have been proposed to solve real-world software problems. Such software agents are typically equipped with a suite of coding tools and can autonomously decide the next actions to form complete trajectories to solve end-to-end software tasks. While promising, they typically require dedicated design and may still be suboptimal, since it can be extremely challenging and costly to exhaust the entire agent scaffold design space. Recognizing that software agents are inherently software themselves that can be further refined/modified, researchers have proposed a number of self-improving software agents recently, including the Darwin-Gödel Machine (DGM). Meanwhile, such self-improving agents require costly offline training on specific benchmarks and may not generalize well across different LLMs or benchmarks. In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that Live-SWE-agent can achieve an impressive solve rate of 75.4% without test-time scaling, outperforming all existing open-source software agents and approaching the performance of the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%.
Visual Instance-aware Prompt Tuning
Jul 10, 2025Visual Prompt Tuning (VPT) has emerged as a parameter-efficient fine-tuning paradigm for vision transformers, with conventional approaches utilizing dataset-level prompts that remain the same across all input instances. We observe that this strategy results in sub-optimal performance due to high variance in downstream datasets. To address this challenge, we propose Visual Instance-aware Prompt Tuning (ViaPT), which generates instance-aware prompts based on each individual input and fuses them with dataset-level prompts, leveraging Principal Component Analysis (PCA) to retain important prompting information. Moreover, we reveal that VPT-Deep and VPT-Shallow represent two corner cases based on a conceptual understanding, in which they fail to effectively capture instance-specific information, while random dimension reduction on prompts only yields performance between the two extremes. Instead, ViaPT overcomes these limitations by balancing dataset-level and instance-level knowledge, while reducing the amount of learnable parameters compared to VPT-Deep. Extensive experiments across 34 diverse datasets demonstrate that our method consistently outperforms state-of-the-art baselines, establishing a new paradigm for analyzing and optimizing visual prompts for vision transformers.
MoRE-Brain: Routed Mixture of Experts for Interpretable and Generalizable Cross-Subject fMRI Visual Decoding
May 21, 2025Decoding visual experiences from fMRI offers a powerful avenue to understand human perception and develop advanced brain-computer interfaces. However, current progress often prioritizes maximizing reconstruction fidelity while overlooking interpretability, an essential aspect for deriving neuroscientific insight. To address this gap, we propose MoRE-Brain, a neuro-inspired framework designed for high-fidelity, adaptable, and interpretable visual reconstruction. MoRE-Brain uniquely employs a hierarchical Mixture-of-Experts architecture where distinct experts process fMRI signals from functionally related voxel groups, mimicking specialized brain networks. The experts are first trained to encode fMRI into the frozen CLIP space. A finetuned diffusion model then synthesizes images, guided by expert outputs through a novel dual-stage routing mechanism that dynamically weighs expert contributions across the diffusion process. MoRE-Brain offers three main advancements: First, it introduces a novel Mixture-of-Experts architecture grounded in brain network principles for neuro-decoding. Second, it achieves efficient cross-subject generalization by sharing core expert networks while adapting only subject-specific routers. Third, it provides enhanced mechanistic insight, as the explicit routing reveals precisely how different modeled brain regions shape the semantic and spatial attributes of the reconstructed image. Extensive experiments validate MoRE-Brain's high reconstruction fidelity, with bottleneck analyses further demonstrating its effective utilization of fMRI signals, distinguishing genuine neural decoding from over-reliance on generative priors. Consequently, MoRE-Brain marks a substantial advance towards more generalizable and interpretable fMRI-based visual decoding. Code will be publicly available soon: https://github.com/yuxiangwei0808/MoRE-Brain.
Bi-LSTM based Multi-Agent DRL with Computation-aware Pruning for Agent Twins Migration in Vehicular Embodied AI Networks
May 09, 2025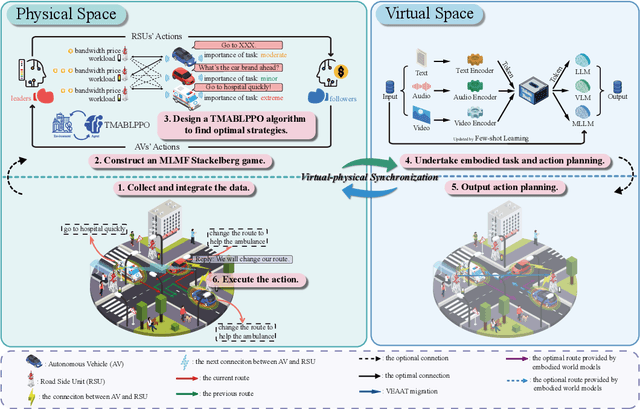
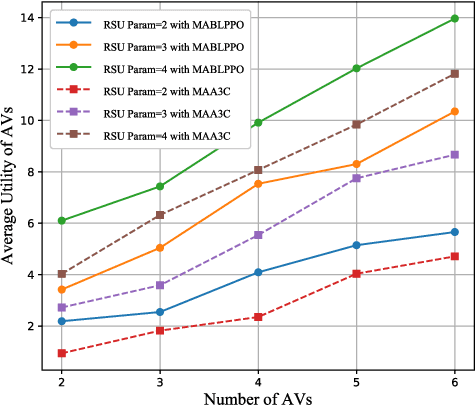
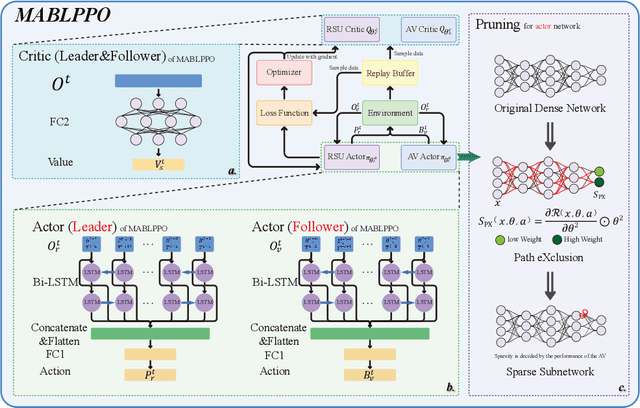
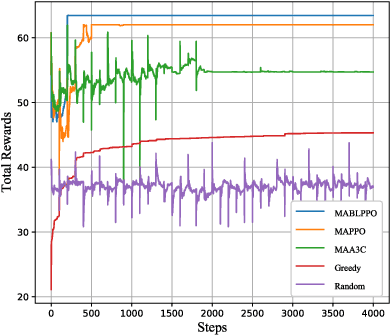
With the advancement of large language models and embodied Artificial Intelligence (AI) in the intelligent transportation scenarios, the combination of them in intelligent transportation spawns the Vehicular Embodied AI Network (VEANs). In VEANs, Autonomous Vehicles (AVs) are typical agents whose local advanced AI applications are defined as vehicular embodied AI agents, enabling capabilities such as environment perception and multi-agent collaboration. Due to computation latency and resource constraints, the local AI applications and services running on vehicular embodied AI agents need to be migrated, and subsequently referred to as vehicular embodied AI agent twins, which drive the advancement of vehicular embodied AI networks to offload intensive tasks to Roadside Units (RSUs), mitigating latency problems while maintaining service quality. Recognizing workload imbalance among RSUs in traditional approaches, we model AV-RSU interactions as a Stackelberg game to optimize bandwidth resource allocation for efficient migration. A Tiny Multi-Agent Bidirectional LSTM Proximal Policy Optimization (TMABLPPO) algorithm is designed to approximate the Stackelberg equilibrium through decentralized coordination. Furthermore, a personalized neural network pruning algorithm based on Path eXclusion (PX) dynamically adapts to heterogeneous AV computation capabilities by identifying task-critical parameters in trained models, reducing model complexity with less performance degradation. Experimental validation confirms the algorithm's effectiveness in balancing system load and minimizing delays, demonstrating significant improvements in vehicular embodied AI agent deployment.
4D Multimodal Co-attention Fusion Network with Latent Contrastive Alignment for Alzheimer's Diagnosis
Apr 23, 2025



Multimodal neuroimaging provides complementary structural and functional insights into both human brain organization and disease-related dynamics. Recent studies demonstrate enhanced diagnostic sensitivity for Alzheimer's disease (AD) through synergistic integration of neuroimaging data (e.g., sMRI, fMRI) with behavioral cognitive scores tabular data biomarkers. However, the intrinsic heterogeneity across modalities (e.g., 4D spatiotemporal fMRI dynamics vs. 3D anatomical sMRI structure) presents critical challenges for discriminative feature fusion. To bridge this gap, we propose M2M-AlignNet: a geometry-aware multimodal co-attention network with latent alignment for early AD diagnosis using sMRI and fMRI. At the core of our approach is a multi-patch-to-multi-patch (M2M) contrastive loss function that quantifies and reduces representational discrepancies via geometry-weighted patch correspondence, explicitly aligning fMRI components across brain regions with their sMRI structural substrates without one-to-one constraints. Additionally, we propose a latent-as-query co-attention module to autonomously discover fusion patterns, circumventing modality prioritization biases while minimizing feature redundancy. We conduct extensive experiments to confirm the effectiveness of our method and highlight the correspondance between fMRI and sMRI as AD biomarkers.
EfficientMT: Efficient Temporal Adaptation for Motion Transfer in Text-to-Video Diffusion Models
Mar 26, 2025



The progress on generative models has led to significant advances on text-to-video (T2V) generation, yet the motion controllability of generated videos remains limited. Existing motion transfer methods explored the motion representations of reference videos to guide generation. Nevertheless, these methods typically rely on sample-specific optimization strategy, resulting in high computational burdens. In this paper, we propose EfficientMT, a novel and efficient end-to-end framework for video motion transfer. By leveraging a small set of synthetic paired motion transfer samples, EfficientMT effectively adapts a pretrained T2V model into a general motion transfer framework that can accurately capture and reproduce diverse motion patterns. Specifically, we repurpose the backbone of the T2V model to extract temporal information from reference videos, and further propose a scaler module to distill motion-related information. Subsequently, we introduce a temporal integration mechanism that seamlessly incorporates reference motion features into the video generation process. After training on our self-collected synthetic paired samples, EfficientMT enables general video motion transfer without requiring test-time optimization. Extensive experiments demonstrate that our EfficientMT outperforms existing methods in efficiency while maintaining flexible motion controllability. Our code will be available https://github.com/PrototypeNx/EfficientMT.
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
Feb 25, 2025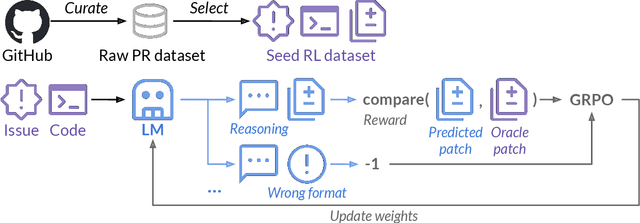


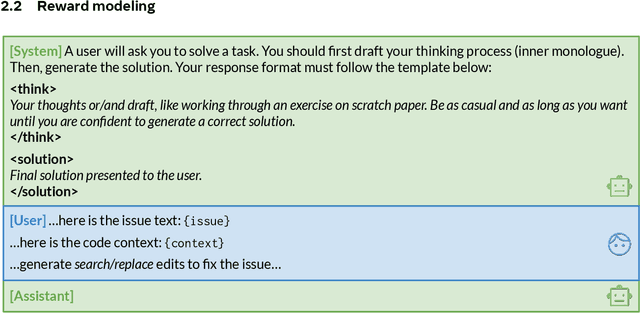
The recent DeepSeek-R1 release has demonstrated the immense potential of reinforcement learning (RL) in enhancing the general reasoning capabilities of large language models (LLMs). While DeepSeek-R1 and other follow-up work primarily focus on applying RL to competitive coding and math problems, this paper introduces SWE-RL, the first approach to scale RL-based LLM reasoning for real-world software engineering. Leveraging a lightweight rule-based reward (e.g., the similarity score between ground-truth and LLM-generated solutions), SWE-RL enables LLMs to autonomously recover a developer's reasoning processes and solutions by learning from extensive open-source software evolution data -- the record of a software's entire lifecycle, including its code snapshots, code changes, and events such as issues and pull requests. Trained on top of Llama 3, our resulting reasoning model, Llama3-SWE-RL-70B, achieves a 41.0% solve rate on SWE-bench Verified -- a human-verified collection of real-world GitHub issues. To our knowledge, this is the best performance reported for medium-sized (<100B) LLMs to date, even comparable to leading proprietary LLMs like GPT-4o. Surprisingly, despite performing RL solely on software evolution data, Llama3-SWE-RL has even emerged with generalized reasoning skills. For example, it shows improved results on five out-of-domain tasks, namely, function coding, library use, code reasoning, mathematics, and general language understanding, whereas a supervised-finetuning baseline even leads to performance degradation on average. Overall, SWE-RL opens up a new direction to improve the reasoning capabilities of LLMs through reinforcement learning on massive software engineering data.