 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-View Training for Instruction-Following Information Retrieval
Apr 20, 2026Instruction-following information retrieval (IF-IR) studies retrieval systems that must not only find documents relevant to a query, but also obey explicit user constraints such as required attributes, exclusions, or output preferences. However, most retrievers are trained primarily for semantic relevance and often fail to distinguish documents that match the topic from those that satisfy the instruction. We propose a dual-view data synthesis strategy based on polarity reversal: given a query, a document that is relevant under the instruction, and a hard negative that matches the query but violates the instruction, we prompt an LLM to generate a complementary instruction under which the two documents swap relevance labels. By presenting the same document pair under complementary instructions that invert their relevance labels, the training signal forces the retriever to reconsider the same candidate set through the instruction, rather than relying on fixed topical cues. On a 305M-parameter encoder, our method improves performance on the FollowIR benchmark by 45%, surpassing general-purpose embedding models of comparable or larger scale. Through head-to-head comparisons at matched data budgets, we further show that data diversity and instruction supervision play complementary roles: the former preserves general retrieval quality, while the latter improves instruction sensitivity. These results highlight the value of targeted data synthesis for building retrieval systems that are both broadly capable and instruction-aware.
ConvCodeWorld: Benchmarking Conversational Code Generation in Reproducible Feedback Environments
Feb 27, 2025Large language models (LLMs) have proven invaluable for code generation, particularly in interactive settings. However, existing code generation benchmarks fail to capture the diverse feedback encountered in multi-turn interactions, limiting our ability to evaluate LLMs in these contexts. To address this gap, we present a set of novel benchmarks that explicitly model the quality of feedback provided to code generation LLMs. Our contributions are threefold: First, we introduce CONVCODEWORLD, a novel and reproducible environment for benchmarking interactive code generation. CONVCODEWORLD simulates 9 distinct interactive code generation scenarios while systematically combining three types of feedback: (a) compilation feedback; (b) execution feedback with varying test coverage; (c) verbal feedback generated by GPT-4o with different levels of expertise. Second, we introduce CONVCODEBENCH, a fast, static version of benchmark that uses pre-generated feedback logs, eliminating the need for costly dynamic verbal feedback generation while maintaining strong Spearman's rank correlations (0.82 to 0.99) with CONVCODEWORLD. Third, extensive evaluations of both closed-source and open-source LLMs including R1-Distill on CONVCODEWORLD reveal key insights: (a) LLM performance varies significantly based on the feedback provided; (b) Weaker LLMs, with sufficient feedback, can outperform single-turn results of state-of-the-art LLMs without feedback; (c) Training on a specific feedback combination can limit an LLM's ability to utilize unseen combinations; (d) LLMs solve problems in fewer turns (high MRR) may not solve as many problems overall (high Recall), and vice versa. All implementations and benchmarks will be made publicly available at https://huggingface.co/spaces/ConvCodeWorld/ConvCodeWorld
Arctic-SnowCoder: Demystifying High-Quality Data in Code Pretraining
Sep 03, 2024



Recent studies have been increasingly demonstrating that high-quality data is crucial for effective pretraining of language models. However, the precise definition of "high-quality" remains underexplored. Focusing on the code domain, we introduce Arctic-SnowCoder-1.3B, a data-efficient base code model pretrained on 555B tokens through three phases of progressively refined data: (1) general pretraining with 500B standard-quality code tokens, preprocessed through basic filtering, deduplication, and decontamination, (2) continued pretraining with 50B high-quality tokens, selected from phase one by a BERT-style quality annotator trained to distinguish good code from random data, using positive examples drawn from high-quality code files, along with instruction data from Magicoder and StarCoder2-Instruct, and (3) enhanced pretraining with 5B synthetic data created by Llama-3.1-70B using phase two data as seeds, adapting the Magicoder approach for pretraining. Despite being trained on a limited dataset, Arctic-SnowCoder achieves state-of-the-art performance on BigCodeBench, a coding benchmark focusing on practical and challenging programming tasks, compared to similarly sized models trained on no more than 1T tokens, outperforming Phi-1.5-1.3B by 36%. Across all evaluated benchmarks, Arctic-SnowCoder-1.3B beats StarCoderBase-3B pretrained on 1T tokens. Additionally, it matches the performance of leading small base code models trained on trillions of tokens. For example, Arctic-SnowCoder-1.3B surpasses StarCoder2-3B, pretrained on over 3.3T tokens, on HumanEval+, a benchmark that evaluates function-level code generation, and remains competitive on BigCodeBench. Our evaluation presents a comprehensive analysis justifying various design choices for Arctic-SnowCoder. Most importantly, we find that the key to high-quality data is its alignment with the distribution of downstream applications.
Practical User Feedback-driven Internal Search Using Online Learning to Rank
Jun 19, 2019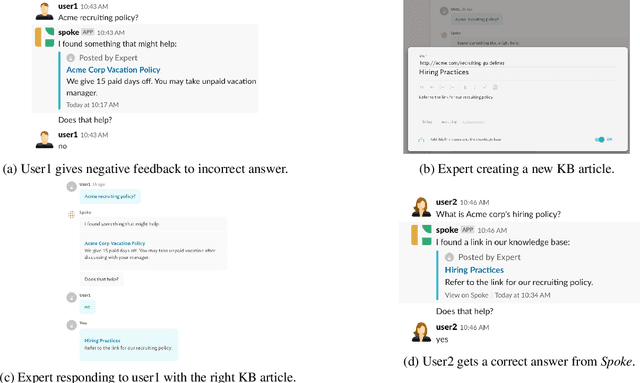

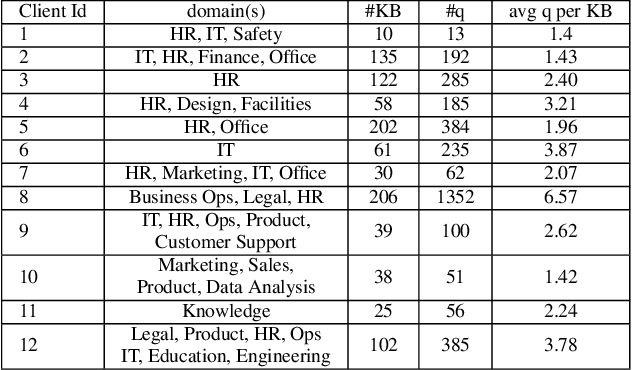
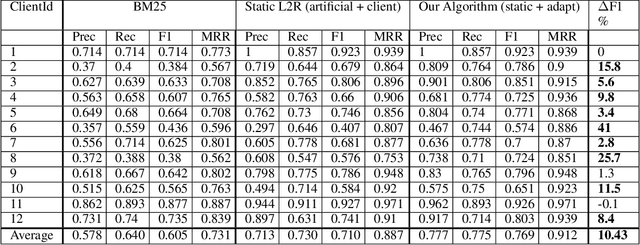
We present a system, Spoke, for creating and searching internal knowledge base (KB) articles for organizations. Spoke is available as a SaaS (Software-as-a-Service) product deployed across hundreds of organizations with a diverse set of domains. Spoke continually improves search quality using conversational user feedback which allows it to provide better search experience than standard information retrieval systems without encoding any explicit domain knowledge. We achieve this by using a real-time online learning-to-rank (L2R) algorithm that automatically customizes relevance scoring for each organization deploying Spoke by using a query similarity kernel. The focus of this paper is on incorporating practical considerations into our relevance scoring function and algorithm that make Spoke easy to deploy and suitable for handling events that naturally happen over the life-cycle of any KB deployment. We show that Spoke outperforms competitive baselines by up to 41% in offline F1 comparisons.
Efficient Decomposed Learning for Structured Prediction
Jun 18, 2012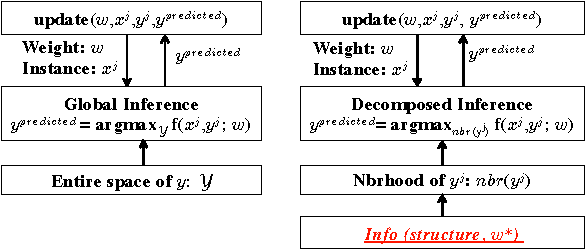
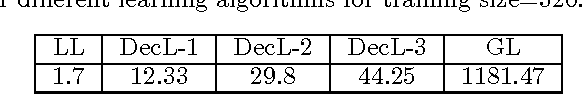
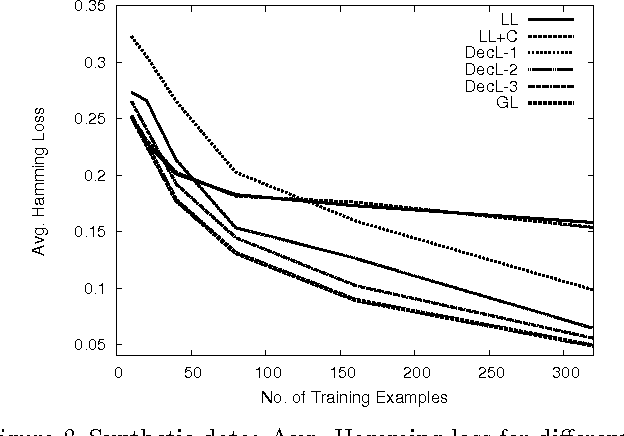

Structured prediction is the cornerstone of several machine learning applications. Unfortunately, in structured prediction settings with expressive inter-variable interactions, exact inference-based learning algorithms, e.g. Structural SVM, are often intractable. We present a new way, Decomposed Learning (DecL), which performs efficient learning by restricting the inference step to a limited part of the structured spaces. We provide characterizations based on the structure, target parameters, and gold labels, under which DecL is equivalent to exact learning. We then show that in real world settings, where our theoretical assumptions may not completely hold, DecL-based algorithms are significantly more efficient and as accurate as exact learning.