 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposed Prompting Does Not Fix Knowledge Gaps, But Helps Models Say "I Don't Know"
Feb 04, 2026Large language models often struggle to recognize their knowledge limits in closed-book question answering, leading to confident hallucinations. While decomposed prompting is typically used to improve accuracy, we investigate its impact on reliability. We evaluate three task-equivalent prompting regimes: Direct, Assistive, and Incremental, across different model scales and multi-hop QA benchmarks. We find that although accuracy gains from decomposition diminish in frontier models, disagreements between prompting regimes remain highly indicative of potential errors. Because factual knowledge is stable while hallucinations are stochastic, cross-regime agreement provides a precise signal of internal uncertainty. We leverage this signal to implement a training-free abstention policy that requires no retrieval or fine-tuning. Our results show that disagreement-based abstention outperforms standard uncertainty baselines as an error detector, improving both F1 and AUROC across settings. This demonstrates that decomposition-based prompting can serve as a practical diagnostic probe for model reliability in closed-book QA.
CORE-T: COherent REtrieval of Tables for Text-to-SQL
Jan 19, 2026Realistic text-to-SQL workflows often require joining multiple tables. As a result, accurately retrieving the relevant set of tables becomes a key bottleneck for end-to-end performance. We study an open-book setting where queries must be answered over large, heterogeneous table collections pooled from many sources, without clean scoping signals such as database identifiers. Here, dense retrieval (DR) achieves high recall but returns many distractors, while join-aware alternatives often rely on extra assumptions and/or incur high inference overhead. We propose CORE-T, a scalable, training-free framework that enriches tables with LLM-generated purpose metadata and pre-computes a lightweight table-compatibility cache. At inference time, DR returns top-K candidates; a single LLM call selects a coherent, joinable subset, and a simple additive adjustment step restores strongly compatible tables. Across Bird, Spider, and MMQA, CORE-T improves table-selection F1 by up to 22.7 points while retrieving up to 42% fewer tables, improving multi-table execution accuracy by up to 5.0 points on Bird and 6.9 points on MMQA, and using 4-5x fewer tokens than LLM-intensive baselines.
Budget-Aware Anytime Reasoning with LLM-Synthesized Preference Data
Jan 16, 2026We study the reasoning behavior of large language models (LLMs) under limited computation budgets. In such settings, producing useful partial solutions quickly is often more practical than exhaustive reasoning, which incurs high inference costs. Many real-world tasks, such as trip planning, require models to deliver the best possible output within a fixed reasoning budget. We introduce an anytime reasoning framework and the Anytime Index, a metric that quantifies how effectively solution quality improves as reasoning tokens increase. To further enhance efficiency, we propose an inference-time self-improvement method using LLM-synthesized preference data, where models learn from their own reasoning comparisons to produce better intermediate solutions. Experiments on NaturalPlan (Trip), AIME, and GPQA datasets show consistent gains across Grok-3, GPT-oss, GPT-4.1/4o, and LLaMA models, improving both reasoning quality and efficiency under budget constraints.
CONCUR: A Framework for Continual Constrained and Unconstrained Routing
Dec 10, 2025AI tasks differ in complexity and are best addressed with different computation strategies (e.g., combinations of models and decoding methods). Hence, an effective routing system that maps tasks to the appropriate strategies is crucial. Most prior methods build the routing framework by training a single model across all strategies, which demands full retraining whenever new strategies appear and leads to high overhead. Attempts at such continual routing, however, often face difficulties with generalization. Prior models also typically use a single input representation, limiting their ability to capture the full complexity of the routing problem and leading to sub-optimal routing decisions. To address these gaps, we propose CONCUR, a continual routing framework that supports both constrained and unconstrained routing (i.e., routing with or without a budget). Our modular design trains a separate predictor model for each strategy, enabling seamless incorporation of new strategies with low additional training cost. Our predictors also leverage multiple representations of both tasks and computation strategies to better capture overall problem complexity. Experiments on both in-distribution and out-of-distribution, knowledge- and reasoning-intensive tasks show that our method outperforms the best single strategy and strong existing routing techniques with higher end-to-end accuracy and lower inference cost in both continual and non-continual settings, while also reducing training cost in the continual setting.
Routesplain: Towards Faithful and Intervenable Routing for Software-related Tasks
Nov 12, 2025



LLMs now tackle a wide range of software-related tasks, yet we show that their performance varies markedly both across and within these tasks. Routing user queries to the appropriate LLMs can therefore help improve response quality while reducing cost. Prior work, however, has focused mainly on general-purpose LLM routing via black-box models. We introduce Routesplain, the first LLM router for software-related tasks, including multilingual code generation and repair, input/output prediction, and computer science QA. Unlike existing routing approaches, Routesplain first extracts human-interpretable concepts from each query (e.g., task, domain, reasoning complexity) and only routes based on these concepts, thereby providing intelligible, faithful rationales. We evaluate Routesplain on 16 state-of-the-art LLMs across eight software-related tasks; Routesplain outperforms individual models both in terms of accuracy and cost, and equals or surpasses all black-box baselines, with concept-level intervention highlighting avenues for further router improvements.
LAD-RAG: Layout-aware Dynamic RAG for Visually-Rich Document Understanding
Oct 08, 2025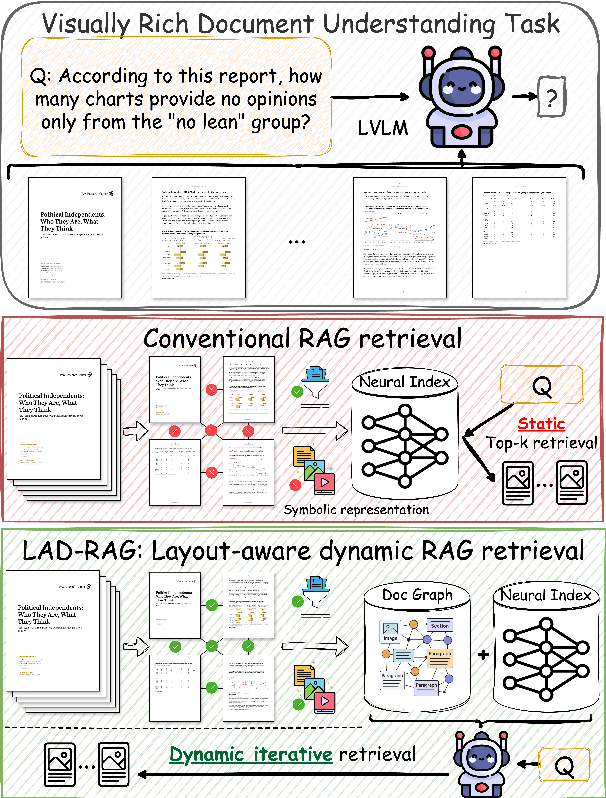
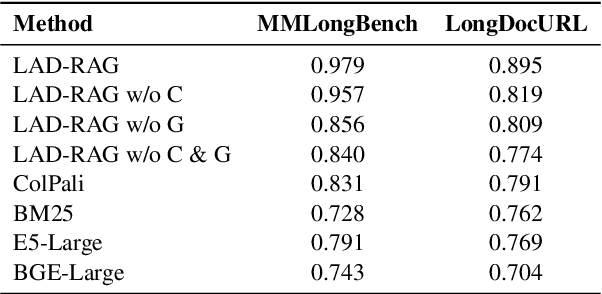
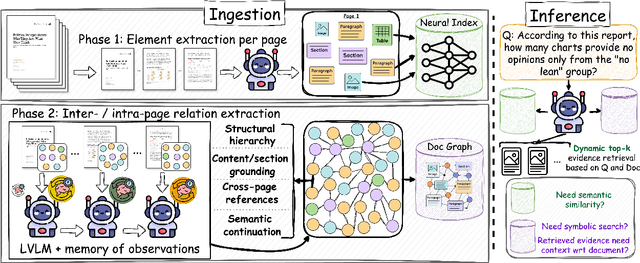
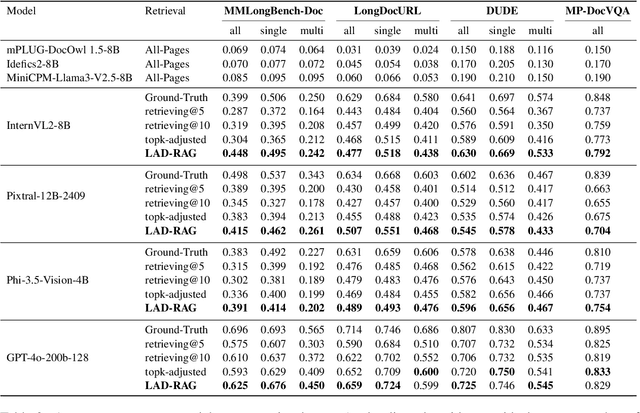
Question answering over visually rich documents (VRDs) requires reasoning not only over isolated content but also over documents' structural organization and cross-page dependencies. However, conventional retrieval-augmented generation (RAG) methods encode content in isolated chunks during ingestion, losing structural and cross-page dependencies, and retrieve a fixed number of pages at inference, regardless of the specific demands of the question or context. This often results in incomplete evidence retrieval and degraded answer quality for multi-page reasoning tasks. To address these limitations, we propose LAD-RAG, a novel Layout-Aware Dynamic RAG framework. During ingestion, LAD-RAG constructs a symbolic document graph that captures layout structure and cross-page dependencies, adding it alongside standard neural embeddings to yield a more holistic representation of the document. During inference, an LLM agent dynamically interacts with the neural and symbolic indices to adaptively retrieve the necessary evidence based on the query. Experiments on MMLongBench-Doc, LongDocURL, DUDE, and MP-DocVQA demonstrate that LAD-RAG improves retrieval, achieving over 90% perfect recall on average without any top-k tuning, and outperforming baseline retrievers by up to 20% in recall at comparable noise levels, yielding higher QA accuracy with minimal latency.
Tree-based Dialogue Reinforced Policy Optimization for Red-Teaming Attacks
Oct 02, 2025Despite recent rapid progress in AI safety, current large language models remain vulnerable to adversarial attacks in multi-turn interaction settings, where attackers strategically adapt their prompts across conversation turns and pose a more critical yet realistic challenge. Existing approaches that discover safety vulnerabilities either rely on manual red-teaming with human experts or employ automated methods using pre-defined templates and human-curated attack data, with most focusing on single-turn attacks. However, these methods did not explore the vast space of possible multi-turn attacks, failing to consider novel attack trajectories that emerge from complex dialogue dynamics and strategic conversation planning. This gap is particularly critical given recent findings that LLMs exhibit significantly higher vulnerability to multi-turn attacks compared to single-turn attacks. We propose DialTree-RPO, an on-policy reinforcement learning framework integrated with tree search that autonomously discovers diverse multi-turn attack strategies by treating the dialogue as a sequential decision-making problem, enabling systematic exploration without manually curated data. Through extensive experiments, our approach not only achieves more than 25.9% higher ASR across 10 target models compared to previous state-of-the-art approaches, but also effectively uncovers new attack strategies by learning optimal dialogue policies that maximize attack success across multiple turns.
Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs
Sep 26, 2025Can humans identify AI-generated (fake) videos and provide grounded reasons? While video generation models have advanced rapidly, a critical dimension -- whether humans can detect deepfake traces within a generated video, i.e., spatiotemporal grounded visual artifacts that reveal a video as machine generated -- has been largely overlooked. We introduce DeeptraceReward, the first fine-grained, spatially- and temporally- aware benchmark that annotates human-perceived fake traces for video generation reward. The dataset comprises 4.3K detailed annotations across 3.3K high-quality generated videos. Each annotation provides a natural-language explanation, pinpoints a bounding-box region containing the perceived trace, and marks precise onset and offset timestamps. We consolidate these annotations into 9 major categories of deepfake traces that lead humans to identify a video as AI-generated, and train multimodal language models (LMs) as reward models to mimic human judgments and localizations. On DeeptraceReward, our 7B reward model outperforms GPT-5 by 34.7% on average across fake clue identification, grounding, and explanation. Interestingly, we observe a consistent difficulty gradient: binary fake v.s. real classification is substantially easier than fine-grained deepfake trace detection; within the latter, performance degrades from natural language explanations (easiest), to spatial grounding, to temporal labeling (hardest). By foregrounding human-perceived deepfake traces, DeeptraceReward provides a rigorous testbed and training signal for socially aware and trustworthy video generation.
Evaluating NL2SQL via SQL2NL
Sep 04, 2025Robust evaluation in the presence of linguistic variation is key to understanding the generalization capabilities of Natural Language to SQL (NL2SQL) models, yet existing benchmarks rarely address this factor in a systematic or controlled manner. We propose a novel schema-aligned paraphrasing framework that leverages SQL-to-NL (SQL2NL) to automatically generate semantically equivalent, lexically diverse queries while maintaining alignment with the original schema and intent. This enables the first targeted evaluation of NL2SQL robustness to linguistic variation in isolation-distinct from prior work that primarily investigates ambiguity or schema perturbations. Our analysis reveals that state-of-the-art models are far more brittle than standard benchmarks suggest. For example, LLaMa3.3-70B exhibits a 10.23% drop in execution accuracy (from 77.11% to 66.9%) on paraphrased Spider queries, while LLaMa3.1-8B suffers an even larger drop of nearly 20% (from 62.9% to 42.5%). Smaller models (e.g., GPT-4o mini) are disproportionately affected. We also find that robustness degradation varies significantly with query complexity, dataset, and domain -- highlighting the need for evaluation frameworks that explicitly measure linguistic generalization to ensure reliable performance in real-world settings.
Reasoning is about giving reasons
Aug 20, 2025Convincing someone of the truth value of a premise requires understanding and articulating the core logical structure of the argument which proves or disproves the premise. Understanding the logical structure of an argument refers to understanding the underlying "reasons" which make up the proof or disproof of the premise - as a function of the "logical atoms" in the argument. While it has been shown that transformers can "chain" rules to derive simple arguments, the challenge of articulating the "reasons" remains. Not only do current approaches to chaining rules suffer in terms of their interpretability, they are also quite constrained in their ability to accommodate extensions to theoretically equivalent reasoning tasks - a model trained to chain rules cannot support abduction or identify contradictions. In this work we suggest addressing these shortcomings by identifying an intermediate representation (which we call the Representation of the Logical Structure (RLS) of the argument) that possesses an understanding of the logical structure of a natural language argument - the logical atoms in the argument and the rules incorporating them. Given the logical structure, reasoning is deterministic and easy to compute. Therefore, our approach supports all forms of reasoning that depend on the logical structure of the natural language argument, including arbitrary depths of reasoning, on-the-fly mistake rectification and interactive discussion with respect to an argument. We show that we can identify and extract the logical structure of natural language arguments in three popular reasoning datasets with high accuracies, thus supporting explanation generation and extending the reasoning capabilities significantly.