 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Classification and Calibration Performance in Decision-Making LLMs via Calibration Aware Reinforcement Learning
Jan 19, 2026Large language models (LLMs) are increasingly deployed in decision-making tasks, where not only accuracy but also reliable confidence estimates are essential. Well-calibrated confidence enables downstream systems to decide when to trust a model and when to defer to fallback mechanisms. In this work, we conduct a systematic study of calibration in two widely used fine-tuning paradigms: supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). We show that while RLVR improves task performance, it produces extremely overconfident models, whereas SFT yields substantially better calibration, even under distribution shift, though with smaller performance gains. Through targeted experiments, we diagnose RLVR's failure, showing that decision tokens act as extraction steps of the decision in reasoning traces and do not carry confidence information, which prevents reinforcement learning from surfacing calibrated alternatives. Based on this insight, we propose a calibration-aware reinforcement learning formulation that directly adjusts decision-token probabilities. Our method preserves RLVR's accuracy level while mitigating overconfidence, reducing ECE scores up to 9 points.
Journey Before Destination: On the importance of Visual Faithfulness in Slow Thinking
Dec 19, 2025Reasoning-augmented vision language models (VLMs) generate explicit chains of thought that promise greater capability and transparency but also introduce new failure modes: models may reach correct answers via visually unfaithful intermediate steps, or reason faithfully yet fail on the final prediction. Standard evaluations that only measure final-answer accuracy cannot distinguish these behaviors. We introduce the visual faithfulness of reasoning chains as a distinct evaluation dimension, focusing on whether the perception steps of a reasoning chain are grounded in the image. We propose a training- and reference-free framework that decomposes chains into perception versus reasoning steps and uses off-the-shelf VLM judges for step-level faithfulness, additionally verifying this approach through a human meta-evaluation. Building on this metric, we present a lightweight self-reflection procedure that detects and locally regenerates unfaithful perception steps without any training. Across multiple reasoning-trained VLMs and perception-heavy benchmarks, our method reduces Unfaithful Perception Rate while preserving final-answer accuracy, improving the reliability of multimodal reasoning.
Towards Long Context Hallucination Detection
Apr 28, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various tasks. However, they are prone to contextual hallucination, generating information that is either unsubstantiated or contradictory to the given context. Although many studies have investigated contextual hallucinations in LLMs, addressing them in long-context inputs remains an open problem. In this work, we take an initial step toward solving this problem by constructing a dataset specifically designed for long-context hallucination detection. Furthermore, we propose a novel architecture that enables pre-trained encoder models, such as BERT, to process long contexts and effectively detect contextual hallucinations through a decomposition and aggregation mechanism. Our experimental results show that the proposed architecture significantly outperforms previous models of similar size as well as LLM-based models across various metrics, while providing substantially faster inference.
DiverseAgentEntropy: Quantifying Black-Box LLM Uncertainty through Diverse Perspectives and Multi-Agent Interaction
Dec 12, 2024



Quantifying the uncertainty in the factual parametric knowledge of Large Language Models (LLMs), especially in a black-box setting, poses a significant challenge. Existing methods, which gauge a model's uncertainty through evaluating self-consistency in responses to the original query, do not always capture true uncertainty. Models might respond consistently to the origin query with a wrong answer, yet respond correctly to varied questions from different perspectives about the same query, and vice versa. In this paper, we propose a novel method, DiverseAgentEntropy, for evaluating a model's uncertainty using multi-agent interaction under the assumption that if a model is certain, it should consistently recall the answer to the original query across a diverse collection of questions about the same original query. We further implement an abstention policy to withhold responses when uncertainty is high. Our method offers a more accurate prediction of the model's reliability and further detects hallucinations, outperforming other self-consistency-based methods. Additionally, it demonstrates that existing models often fail to consistently retrieve the correct answer to the same query under diverse varied questions even when knowing the correct answer.
Inference time LLM alignment in single and multidomain preference spectrum
Oct 24, 2024
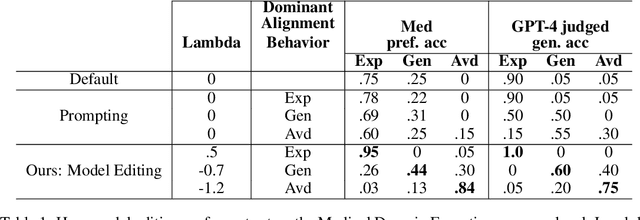
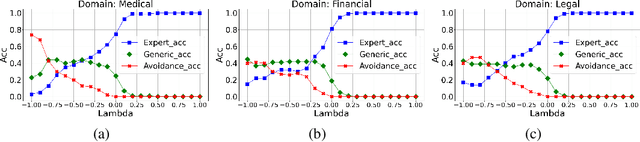
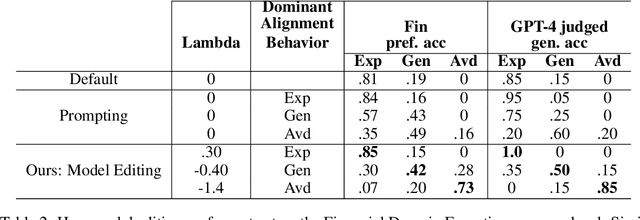
Aligning Large Language Models (LLM) to address subjectivity and nuanced preference levels requires adequate flexibility and control, which can be a resource-intensive and time-consuming procedure. Existing training-time alignment methods require full re-training when a change is needed and inference-time ones typically require access to the reward model at each inference step. To address these limitations, we introduce inference-time model alignment method that learns encoded representations of preference dimensions, called \textit{Alignment Vectors} (AV). These representations are computed by subtraction of the base model from the aligned model as in model editing enabling dynamically adjusting the model behavior during inference through simple linear operations. Even though the preference dimensions can span various granularity levels, here we focus on three gradual response levels across three specialized domains: medical, legal, and financial, exemplifying its practical potential. This new alignment paradigm introduces adjustable preference knobs during inference, allowing users to tailor their LLM outputs while reducing the inference cost by half compared to the prompt engineering approach. Additionally, we find that AVs are transferable across different fine-tuning stages of the same model, demonstrating their flexibility. AVs also facilitate multidomain, diverse preference alignment, making the process 12x faster than the retraining approach.
Open Domain Question Answering with Conflicting Contexts
Oct 16, 2024



Open domain question answering systems frequently rely on information retrieved from large collections of text (such as the Web) to answer questions. However, such collections of text often contain conflicting information, and indiscriminately depending on this information may result in untruthful and inaccurate answers. To understand the gravity of this problem, we collect a human-annotated dataset, Question Answering with Conflicting Contexts (QACC), and find that as much as 25% of unambiguous, open domain questions can lead to conflicting contexts when retrieved using Google Search. We evaluate and benchmark three powerful Large Language Models (LLMs) with our dataset QACC and demonstrate their limitations in effectively addressing questions with conflicting information. To explore how humans reason through conflicting contexts, we request our annotators to provide explanations for their selections of correct answers. We demonstrate that by finetuning LLMs to explain their answers, we can introduce richer information into their training that guide them through the process of reasoning with conflicting contexts.
RDP: Ranked Differential Privacy for Facial Feature Protection in Multiscale Sparsified Subspace
Aug 01, 2024



With the widespread sharing of personal face images in applications' public databases, face recognition systems faces real threat of being breached by potential adversaries who are able to access users' face images and use them to intrude the face recognition systems. In this paper, we propose a novel privacy protection method in the multiscale sparsified feature subspaces to protect sensitive facial features, by taking care of the influence or weight ranked feature coefficients on the privacy budget, named "Ranked Differential Privacy (RDP)". After the multiscale feature decomposition, the lightweight Laplacian noise is added to the dimension-reduced sparsified feature coefficients according to the geometric superposition method. Then, we rigorously prove that the RDP satisfies Differential Privacy. After that, the nonlinear Lagrange Multiplier (LM) method is formulated for the constraint optimization problem of maximizing the utility of the visualization quality protected face images with sanitizing noise, under a given facial features privacy budget. Then, two methods are proposed to solve the nonlinear LM problem and obtain the optimal noise scale parameters: 1) the analytical Normalization Approximation (NA) method with identical average noise scale parameter for real-time online applications; and 2) the LM optimization Gradient Descent (LMGD) numerical method to obtain the nonlinear solution through iterative updating for more accurate offline applications. Experimental results on two real-world datasets show that our proposed RDP outperforms other state-of-the-art methods: at a privacy budget of 0.2, the PSNR (Peak Signal-to-Noise Ratio) of the RDP is about ~10 dB higher than (10 times as high as) the highest PSNR of all compared methods.
General Purpose Verification for Chain of Thought Prompting
Apr 30, 2024



Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
Color-NeuraCrypt: Privacy-Preserving Color-Image Classification Using Extended Random Neural Networks
Jan 12, 2023



In recent years, with the development of cloud computing platforms, privacy-preserving methods for deep learning have become an urgent problem. NeuraCrypt is a private random neural network for privacy-preserving that allows data owners to encrypt the medical data before the data uploading, and data owners can train and then test their models in a cloud server with the encrypted data directly. However, we point out that the performance of NeuraCrypt is heavily degraded when using color images. In this paper, we propose a Color-NeuraCrypt to solve this problem. Experiment results show that our proposed Color-NeuraCrypt can achieve a better classification accuracy than the original one and other privacy-preserving methods.
Privacy-Preserving Image Classification Using ConvMixer with Adaptive Permutation Matrix
Aug 04, 2022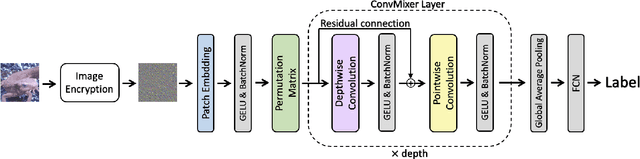

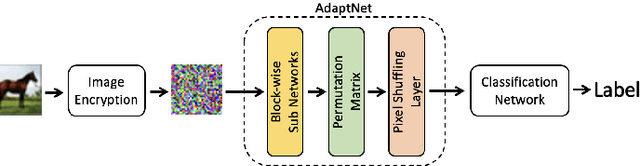
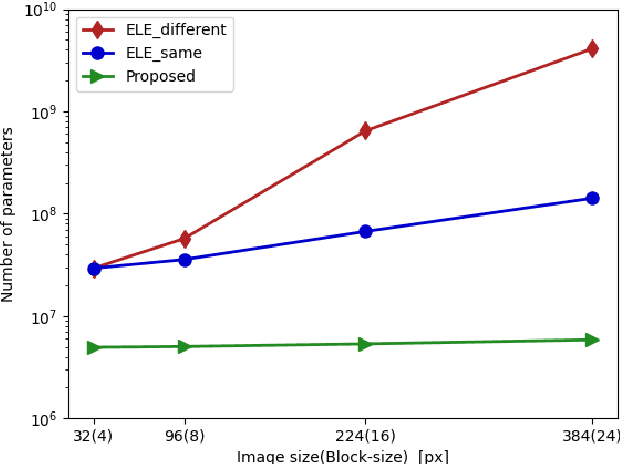
In this paper, we propose a privacy-preserving image classification method using encrypted images under the use of the ConvMixer structure. Block-wise scrambled images, which are robust enough against various attacks, have been used for privacy-preserving image classification tasks, but the combined use of a classification network and an adaptation network is needed to reduce the influence of image encryption. However, images with a large size cannot be applied to the conventional method with an adaptation network because the adaptation network has so many parameters. Accordingly, we propose a novel method, which allows us not only to apply block-wise scrambled images to ConvMixer for both training and testing without the adaptation network, but also to provide a higher classification accuracy than conventional methods.