 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Table Retrieval and Understanding with Multimodal Large Language Models
Feb 07, 2026Tabular data is frequently captured in image form across a wide range of real-world scenarios such as financial reports, handwritten records, and document scans. These visual representations pose unique challenges for machine understanding, as they combine both structural and visual complexities. While recent advances in Multimodal Large Language Models (MLLMs) show promising results in table understanding, they typically assume the relevant table is readily available. However, a more practical scenario involves identifying and reasoning over relevant tables from large-scale collections to answer user queries. To address this gap, we propose TabRAG, a framework that enables MLLMs to answer queries over large collections of table images. Our approach first retrieves candidate tables using jointly trained visual-text foundation models, then leverages MLLMs to perform fine-grained reranking of these candidates, and finally employs MLLMs to reason over the selected tables for answer generation. Through extensive experiments on a newly constructed dataset comprising 88,161 training and 9,819 testing samples across 8 benchmarks with 48,504 unique tables, we demonstrate that our framework significantly outperforms existing methods by 7.0% in retrieval recall and 6.1% in answer accuracy, offering a practical solution for real-world table understanding tasks.
CrEst: Credibility Estimation for Contexts in LLMs via Weak Supervision
Jun 17, 2025The integration of contextual information has significantly enhanced the performance of large language models (LLMs) on knowledge-intensive tasks. However, existing methods often overlook a critical challenge: the credibility of context documents can vary widely, potentially leading to the propagation of unreliable information. In this paper, we introduce CrEst, a novel weakly supervised framework for assessing the credibility of context documents during LLM inference--without requiring manual annotations. Our approach is grounded in the insight that credible documents tend to exhibit higher semantic coherence with other credible documents, enabling automated credibility estimation through inter-document agreement. To incorporate credibility into LLM inference, we propose two integration strategies: a black-box approach for models without access to internal weights or activations, and a white-box method that directly modifies attention mechanisms. Extensive experiments across three model architectures and five datasets demonstrate that CrEst consistently outperforms strong baselines, achieving up to a 26.86% improvement in accuracy and a 3.49% increase in F1 score. Further analysis shows that CrEst maintains robust performance even under high-noise conditions.
Exploration of Plan-Guided Summarization for Narrative Texts: the Case of Small Language Models
Apr 12, 2025



Plan-guided summarization attempts to reduce hallucinations in small language models (SLMs) by grounding generated summaries to the source text, typically by targeting fine-grained details such as dates or named entities. In this work, we investigate whether plan-based approaches in SLMs improve summarization in long document, narrative tasks. Narrative texts' length and complexity often mean they are difficult to summarize faithfully. We analyze existing plan-guided solutions targeting fine-grained details, and also propose our own higher-level, narrative-based plan formulation. Our results show that neither approach significantly improves on a baseline without planning in either summary quality or faithfulness. Human evaluation reveals that while plan-guided approaches are often well grounded to their plan, plans are equally likely to contain hallucinations compared to summaries. As a result, the plan-guided summaries are just as unfaithful as those from models without planning. Our work serves as a cautionary tale to plan-guided approaches to summarization, especially for long, complex domains such as narrative texts.
Effectively Steer LLM To Follow Preference via Building Confident Directions
Mar 04, 2025Having an LLM that aligns with human preferences is essential for accommodating individual needs, such as maintaining writing style or generating specific topics of interest. The majority of current alignment methods rely on fine-tuning or prompting, which can be either costly or difficult to control. Model steering algorithms, which modify the model output by constructing specific steering directions, are typically easy to implement and optimization-free. However, their capabilities are typically limited to steering the model into one of the two directions (i.e., bidirectional steering), and there has been no theoretical understanding to guarantee their performance. In this work, we propose a theoretical framework to understand and quantify the model steering methods. Inspired by the framework, we propose a confident direction steering method (CONFST) that steers LLMs via modifying their activations at inference time. More specifically, CONFST builds a confident direction that is closely aligned with users' preferences, and this direction is then added to the activations of the LLMs to effectively steer the model output. Our approach offers three key advantages over popular bidirectional model steering methods: 1) It is more powerful, since multiple (i.e. more than two) users' preferences can be aligned simultaneously; 2) It is simple to implement, since there is no need to determine which layer to add the steering vector to; 3) No explicit user instruction is required. We validate our method on GPT-2 XL (1.5B), Mistral (7B) and Gemma-it (9B) models for tasks that require shifting the output of LLMs across various topics and styles, achieving superior performance over competing methods.
InsTALL: Context-aware Instructional Task Assistance with Multi-modal Large Language Models
Jan 21, 2025



The improved competence of generative models can help building multi-modal virtual assistants that leverage modalities beyond language. By observing humans performing multi-step tasks, one can build assistants that have situational awareness of actions and tasks being performed, enabling them to cater assistance based on this understanding. In this paper, we develop a Context-aware Instructional Task Assistant with Multi-modal Large Language Models (InsTALL) that leverages an online visual stream (e.g. a user's screen share or video recording) and responds in real-time to user queries related to the task at hand. To enable useful assistance, InsTALL 1) trains a multi-modal model on task videos and paired textual data, and 2) automatically extracts task graph from video data and leverages it at training and inference time. We show InsTALL achieves state-of-the-art performance across proposed sub-tasks considered for multimodal activity understanding -- task recognition (TR), action recognition (AR), next action prediction (AP), and plan prediction (PP) -- and outperforms existing baselines on two novel sub-tasks related to automatic error identification.
Open Domain Question Answering with Conflicting Contexts
Oct 16, 2024



Open domain question answering systems frequently rely on information retrieved from large collections of text (such as the Web) to answer questions. However, such collections of text often contain conflicting information, and indiscriminately depending on this information may result in untruthful and inaccurate answers. To understand the gravity of this problem, we collect a human-annotated dataset, Question Answering with Conflicting Contexts (QACC), and find that as much as 25% of unambiguous, open domain questions can lead to conflicting contexts when retrieved using Google Search. We evaluate and benchmark three powerful Large Language Models (LLMs) with our dataset QACC and demonstrate their limitations in effectively addressing questions with conflicting information. To explore how humans reason through conflicting contexts, we request our annotators to provide explanations for their selections of correct answers. We demonstrate that by finetuning LLMs to explain their answers, we can introduce richer information into their training that guide them through the process of reasoning with conflicting contexts.
QueryBuilder: Human-in-the-Loop Query Development for Information Retrieval
Sep 10, 2024Frequently, users of an Information Retrieval (IR) system start with an overarching information need (a.k.a., an analytic task) and proceed to define finer-grained queries covering various important aspects (i.e., sub-topics) of that analytic task. We present a novel, interactive system called $\textit{QueryBuilder}$, which allows a novice, English-speaking user to create queries with a small amount of effort, through efficient exploration of an English development corpus in order to rapidly develop cross-lingual information retrieval queries corresponding to the user's information needs. QueryBuilder performs near real-time retrieval of documents based on user-entered search terms; the user looks through the retrieved documents and marks sentences as relevant to the information needed. The marked sentences are used by the system as additional information in query formation and refinement: query terms (and, optionally, event features, which capture event $'triggers'$ (indicator terms) and agent/patient roles) are appropriately weighted, and a neural-based system, which better captures textual meaning, retrieves other relevant content. The process of retrieval and marking is repeated as many times as desired, giving rise to increasingly refined queries in each iteration. The final product is a fine-grained query used in Cross-Lingual Information Retrieval (CLIR). Our experiments using analytic tasks and requests from the IARPA BETTER IR datasets show that with a small amount of effort (at most 10 minutes per sub-topic), novice users can form $\textit{useful}$ fine-grained queries including in languages they don't understand. QueryBuilder also provides beneficial capabilities to the traditional corpus exploration and query formation process. A demonstration video is released at https://vimeo.com/734795835
Dancing in Chains: Reconciling Instruction Following and Faithfulness in Language Models
Jul 31, 2024Modern language models (LMs) need to follow human instructions while being faithful; yet, they often fail to achieve both. Here, we provide concrete evidence of a trade-off between instruction following (i.e., follow open-ended instructions) and faithfulness (i.e., ground responses in given context) when training LMs with these objectives. For instance, fine-tuning LLaMA-7B on instruction following datasets renders it less faithful. Conversely, instruction-tuned Vicuna-7B shows degraded performance at following instructions when further optimized on tasks that require contextual grounding. One common remedy is multi-task learning (MTL) with data mixing, yet it remains far from achieving a synergic outcome. We propose a simple yet effective method that relies on Rejection Sampling for Continued Self-instruction Tuning (ReSet), which significantly outperforms vanilla MTL. Surprisingly, we find that less is more, as training ReSet with high-quality, yet substantially smaller data (three-fold less) yields superior results. Our findings offer a better understanding of objective discrepancies in alignment training of LMs.
RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering
Jul 19, 2024Question answering based on retrieval augmented generation (RAG-QA) is an important research topic in NLP and has a wide range of real-world applications. However, most existing datasets for this task are either constructed using a single source corpus or consist of short extractive answers, which fall short of evaluating large language model (LLM) based RAG-QA systems on cross-domain generalization. To address these limitations, we create Long-form RobustQA (LFRQA), a new dataset comprising human-written long-form answers that integrate short extractive answers from multiple documents into a single, coherent narrative, covering 26K queries and large corpora across seven different domains. We further propose RAG-QA Arena by directly comparing model-generated answers against LFRQA's answers using LLMs as evaluators. We show via extensive experiments that RAG-QA Arena and human judgments on answer quality are highly correlated. Moreover, only 41.3% of the most competitive LLM's answers are preferred to LFRQA's answers, demonstrating RAG-QA Arena as a challenging evaluation platform for future research.
Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
Apr 24, 2024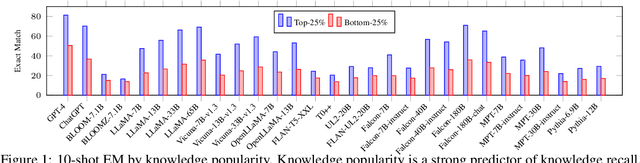



Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.