 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueryBuilder: Human-in-the-Loop Query Development for Information Retrieval
Sep 10, 2024Frequently, users of an Information Retrieval (IR) system start with an overarching information need (a.k.a., an analytic task) and proceed to define finer-grained queries covering various important aspects (i.e., sub-topics) of that analytic task. We present a novel, interactive system called $\textit{QueryBuilder}$, which allows a novice, English-speaking user to create queries with a small amount of effort, through efficient exploration of an English development corpus in order to rapidly develop cross-lingual information retrieval queries corresponding to the user's information needs. QueryBuilder performs near real-time retrieval of documents based on user-entered search terms; the user looks through the retrieved documents and marks sentences as relevant to the information needed. The marked sentences are used by the system as additional information in query formation and refinement: query terms (and, optionally, event features, which capture event $'triggers'$ (indicator terms) and agent/patient roles) are appropriately weighted, and a neural-based system, which better captures textual meaning, retrieves other relevant content. The process of retrieval and marking is repeated as many times as desired, giving rise to increasingly refined queries in each iteration. The final product is a fine-grained query used in Cross-Lingual Information Retrieval (CLIR). Our experiments using analytic tasks and requests from the IARPA BETTER IR datasets show that with a small amount of effort (at most 10 minutes per sub-topic), novice users can form $\textit{useful}$ fine-grained queries including in languages they don't understand. QueryBuilder also provides beneficial capabilities to the traditional corpus exploration and query formation process. A demonstration video is released at https://vimeo.com/734795835
Cross-lingual Information Retrieval with BERT
Apr 24, 2020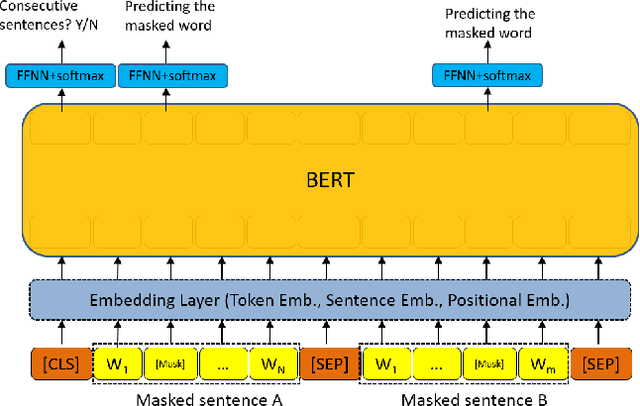

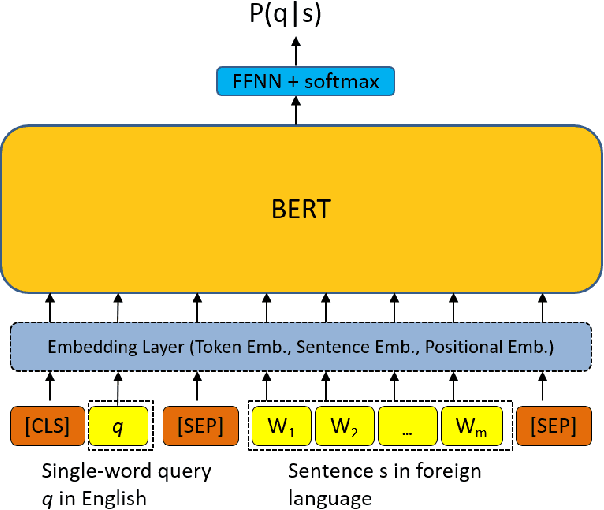
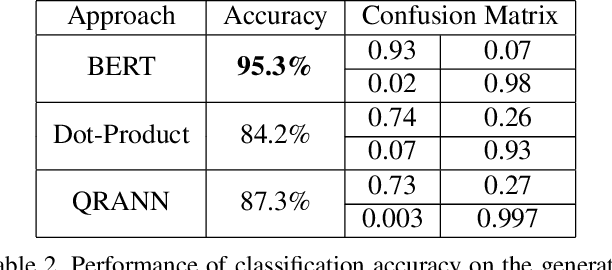
Multiple neural language models have been developed recently, e.g., BERT and XLNet, and achieved impressive results in various NLP tasks including sentence classification, question answering and document ranking. In this paper, we explore the use of the popular bidirectional language model, BERT, to model and learn the relevance between English queries and foreign-language documents in the task of cross-lingual information retrieval. A deep relevance matching model based on BERT is introduced and trained by finetuning a pretrained multilingual BERT model with weak supervision, using home-made CLIR training data derived from parallel corpora. Experimental results of the retrieval of Lithuanian documents against short English queries show that our model is effective and outperforms the competitive baseline approaches.
Estimating Confusions in the ASR Channel for Improved Topic-based Language Model Adaptation
Mar 21, 2013
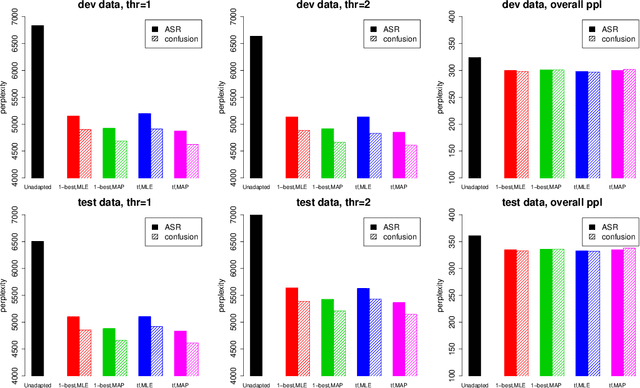
Human language is a combination of elemental languages/domains/styles that change across and sometimes within discourses. Language models, which play a crucial role in speech recognizers and machine translation systems, are particularly sensitive to such changes, unless some form of adaptation takes place. One approach to speech language model adaptation is self-training, in which a language model's parameters are tuned based on automatically transcribed audio. However, transcription errors can misguide self-training, particularly in challenging settings such as conversational speech. In this work, we propose a model that considers the confusions (errors) of the ASR channel. By modeling the likely confusions in the ASR output instead of using just the 1-best, we improve self-training efficacy by obtaining a more reliable reference transcription estimate. We demonstrate improved topic-based language modeling adaptation results over both 1-best and lattice self-training using our ASR channel confusion estimates on telephone conversations.