 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOGGL: Transcribing Overlapping Speech with Staggered Labeling
Aug 12, 2024Transcribing the speech of multiple overlapping speakers typically requires separating the audio into multiple streams and recognizing each one independently. More recent work jointly separates and transcribes, but requires a separate decoding component for each speaker. We propose the TOGGL model to simultaneously transcribe the speech of multiple speakers. The TOGGL model uses special output tokens to attribute the speech to each speaker with only a single decoder. Our approach generalizes beyond two speakers, even when trained only on two-speaker data. We demonstrate superior performance compared to competing approaches on a conversational speech dataset. Our approach also improves performance on single-speaker audio.
Cross-Lingual Conversational Speech Summarization with Large Language Models
Aug 12, 2024Cross-lingual conversational speech summarization is an important problem, but suffers from a dearth of resources. While transcriptions exist for a number of languages, translated conversational speech is rare and datasets containing summaries are non-existent. We build upon the existing Fisher and Callhome Spanish-English Speech Translation corpus by supplementing the translations with summaries. The summaries are generated using GPT-4 from the reference translations and are treated as ground truth. The task is to generate similar summaries in the presence of transcription and translation errors. We build a baseline cascade-based system using open-source speech recognition and machine translation models. We test a range of LLMs for summarization and analyze the impact of transcription and translation errors. Adapting the Mistral-7B model for this task performs significantly better than off-the-shelf models and matches the performance of GPT-4.
Using i-vectors for subject-independent cross-session EEG transfer learning
Jan 16, 2024Cognitive load classification is the task of automatically determining an individual's utilization of working memory resources during performance of a task based on physiologic measures such as electroencephalography (EEG). In this paper, we follow a cross-disciplinary approach, where tools and methodologies from speech processing are used to tackle this problem. The corpus we use was released publicly in 2021 as part of the first passive brain-computer interface competition on cross-session workload estimation. We present our approach which used i-vector-based neural network classifiers to accomplish inter-subject cross-session EEG transfer learning, achieving 18% relative improvement over equivalent subject-dependent models. We also report experiments showing how our subject-independent models perform competitively on held-out subjects and improve with additional subject data, suggesting that subject-dependent training is not required for effective cognitive load determination.
Training Autoregressive Speech Recognition Models with Limited in-domain Supervision
Oct 27, 2022
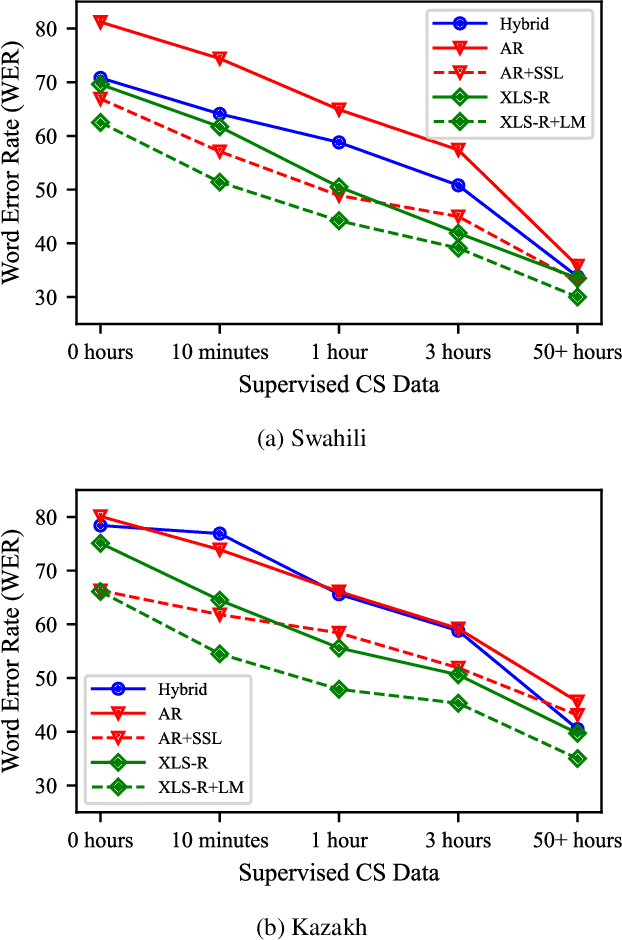

Advances in self-supervised learning have significantly reduced the amount of transcribed audio required for training. However, the majority of work in this area is focused on read speech. We explore limited supervision in the domain of conversational speech. While we assume the amount of in-domain data is limited, we augment the model with open source read speech data. The XLS-R model has been shown to perform well with limited adaptation data and serves as a strong baseline. We use untranscribed data for self-supervised learning and semi-supervised training in an autoregressive encoder-decoder model. We demonstrate that by using the XLS-R model for pseudotranscription, a much smaller autoregressive model can outperform a finetuned XLS-R model when transcribed in-domain data is limited, reducing WER by as much as 8% absolute.
Combining Unsupervised and Text Augmented Semi-Supervised Learning for Low Resourced Autoregressive Speech Recognition
Oct 29, 2021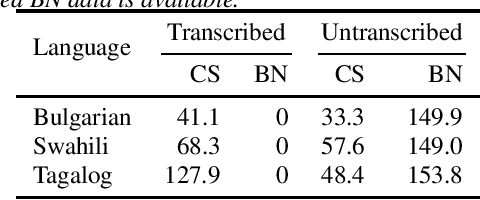
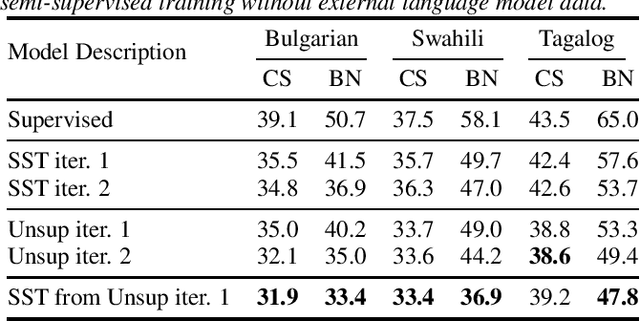
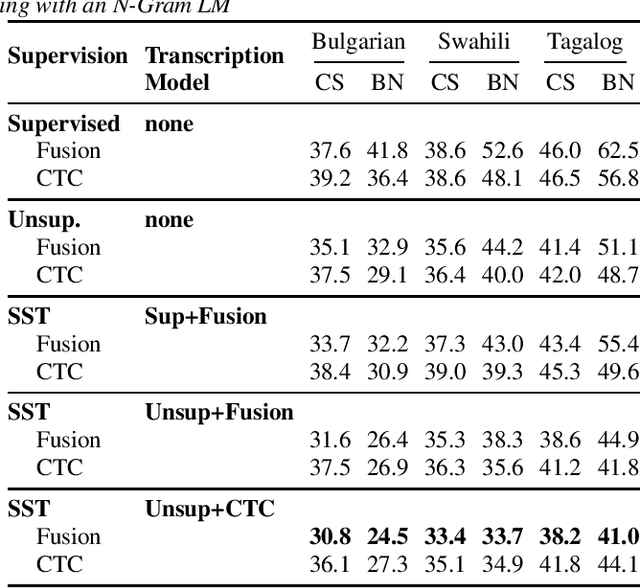
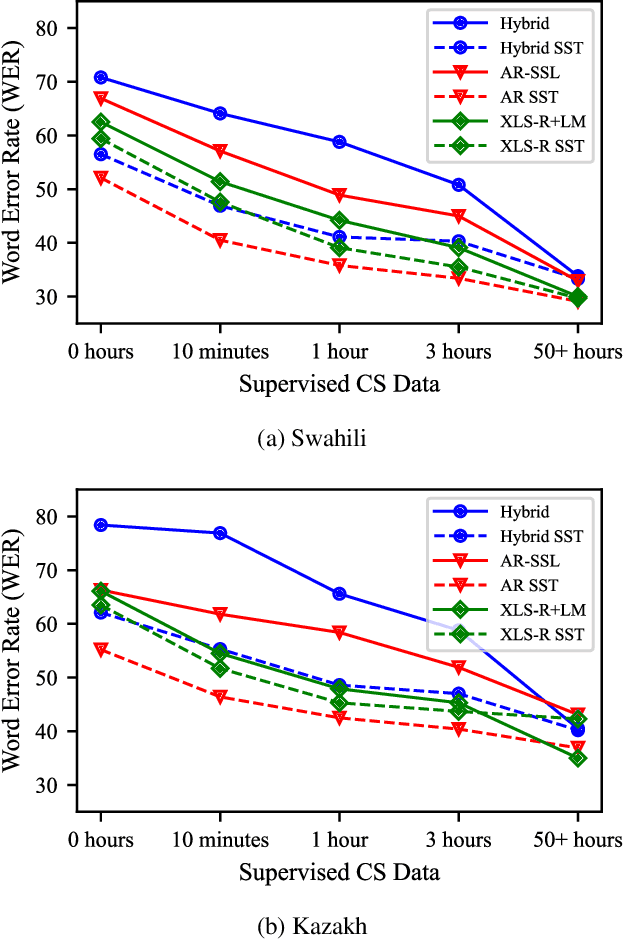
Recent advances in unsupervised representation learning have demonstrated the impact of pretraining on large amounts of read speech. We adapt these techniques for domain adaptation in low-resource -- both in terms of data and compute -- conversational and broadcast domains. Moving beyond CTC, we pretrain state-of-the-art Conformer models in an unsupervised manner. While the unsupervised approach outperforms traditional semi-supervised training, the techniques are complementary. Combining the techniques is a 5% absolute improvement in WER, averaged over all conditions, compared to semi-supervised training alone. Additional text data is incorporated through external language models. By using CTC-based decoding, we are better able to take advantage of the additional text data. When used as a transcription model, it allows the Conformer model to better incorporate the knowledge from the language model through semi-supervised training than shallow fusion. Final performance is an additional 2% better absolute when using CTC-based decoding for semi-supervised training compared to shallow fusion.
Overcoming Domain Mismatch in Low Resource Sequence-to-Sequence ASR Models using Hybrid Generated Pseudotranscripts
Jun 14, 2021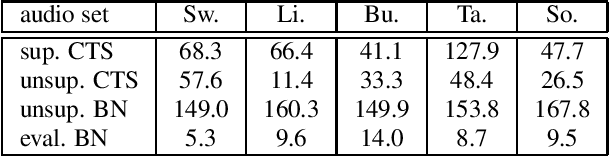
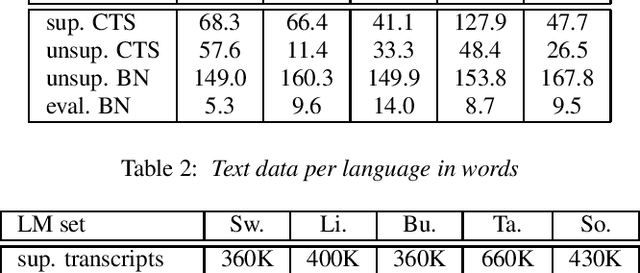
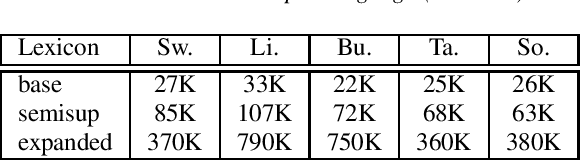
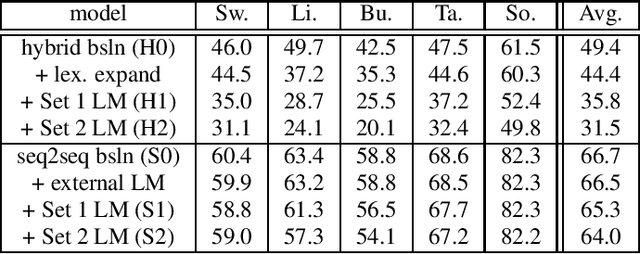
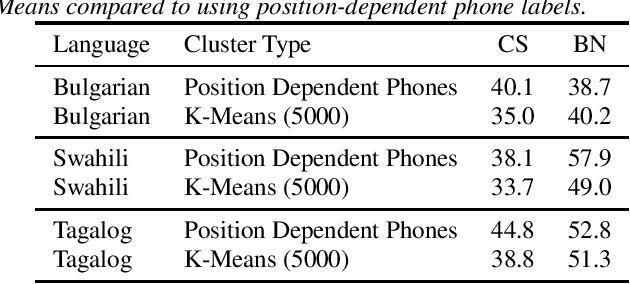
Sequence-to-sequence (seq2seq) models are competitive with hybrid models for automatic speech recognition (ASR) tasks when large amounts of training data are available. However, data sparsity and domain adaptation are more problematic for seq2seq models than their hybrid counterparts. We examine corpora of five languages from the IARPA MATERIAL program where the transcribed data is conversational telephone speech (CTS) and evaluation data is broadcast news (BN). We show that there is a sizable initial gap in such a data condition between hybrid and seq2seq models, and the hybrid model is able to further improve through the use of additional language model (LM) data. We use an additional set of untranscribed data primarily in the BN domain for semisupervised training. In semisupervised training, a seed model trained on transcribed data generates hypothesized transcripts for unlabeled domain-matched data for further training. By using a hybrid model with an expanded language model for pseudotranscription, we are able to improve our seq2seq model from an average word error rate (WER) of 66.7% across all five languages to 29.0% WER. While this puts the seq2seq model at a competitive operating point, hybrid models are still able to use additional LM data to maintain an advantage.
Using heterogeneity in semi-supervised transcription hypotheses to improve code-switched speech recognition
Jun 14, 2021
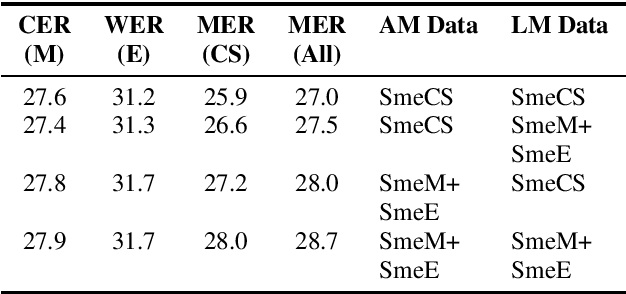
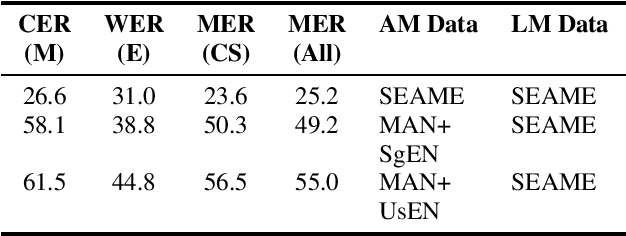
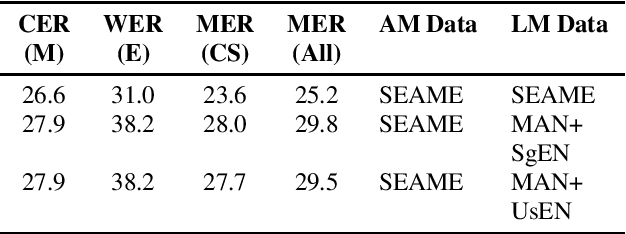
Modeling code-switched speech is an important problem in automatic speech recognition (ASR). Labeled code-switched data are rare, so monolingual data are often used to model code-switched speech. These monolingual data may be more closely matched to one of the languages in the code-switch pair. We show that such asymmetry can bias prediction toward the better-matched language and degrade overall model performance. To address this issue, we propose a semi-supervised approach for code-switched ASR. We consider the case of English-Mandarin code-switching, and the problem of using monolingual data to build bilingual "transcription models'' for annotation of unlabeled code-switched data. We first build multiple transcription models so that their individual predictions are variously biased toward either English or Mandarin. We then combine these biased transcriptions using confidence-based selection. This strategy generates a superior transcript for semi-supervised training, and obtains a 19% relative improvement compared to a semi-supervised system that relies on a transcription model built with only the best-matched monolingual data.
Learning from Noisy Labels with Noise Modeling Network
May 01, 2020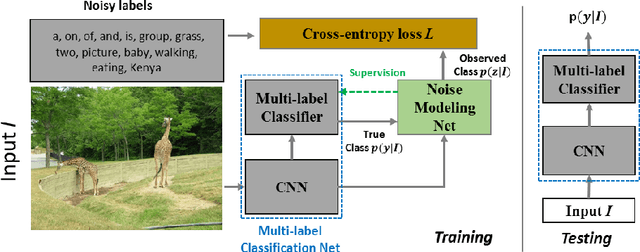
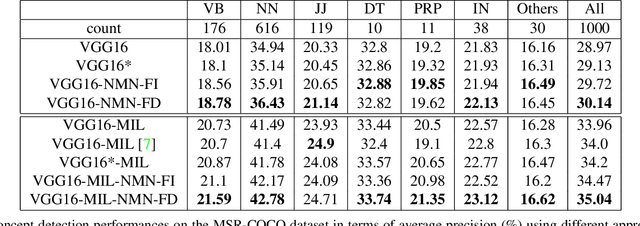
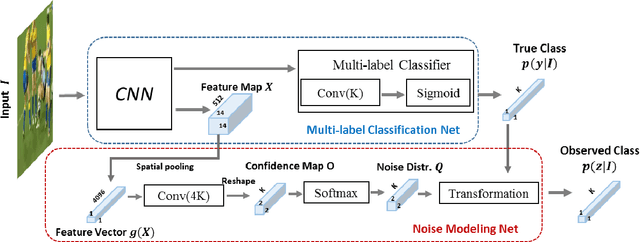
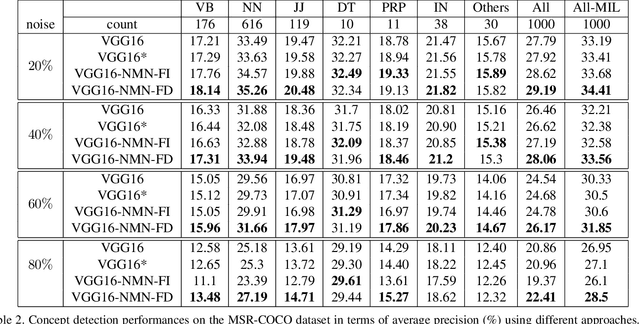
Multi-label image classification has generated significant interest in recent years and the performance of such systems often suffers from the not so infrequent occurrence of incorrect or missing labels in the training data. In this paper, we extend the state-of the-art of training classifiers to jointly deal with both forms of errorful data. We accomplish this by modeling noisy and missing labels in multi-label images with a new Noise Modeling Network (NMN) that follows our convolutional neural network (CNN), integrates with it, forming an end-to-end deep learning system, which can jointly learn the noise distribution and CNN parameters. The NMN learns the distribution of noise patterns directly from the noisy data without the need for any clean training data. The NMN can model label noise that depends only on the true label or is also dependent on the image features. We show that the integrated NMN/CNN learning system consistently improves the classification performance, for different levels of label noise, on the MSR-COCO dataset and MSR-VTT dataset. We also show that noise performance improvements are obtained when multiple instance learning methods are used.
Cross-lingual Information Retrieval with BERT
Apr 24, 2020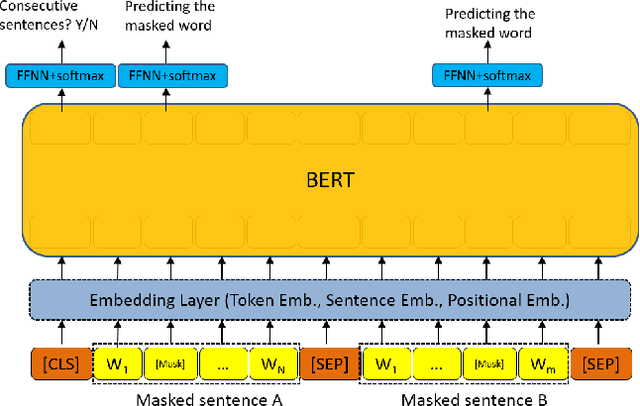

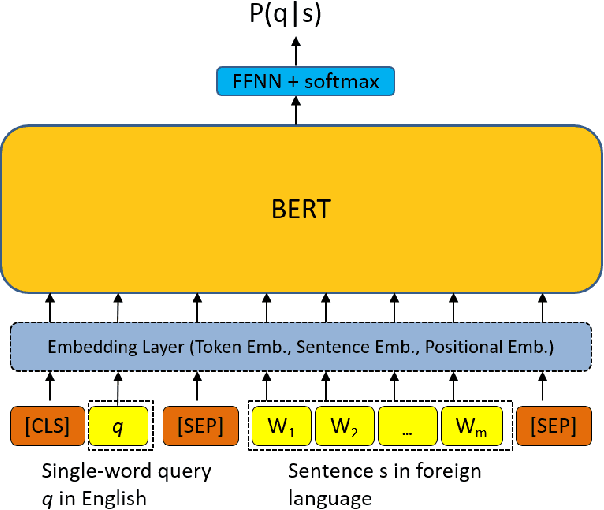
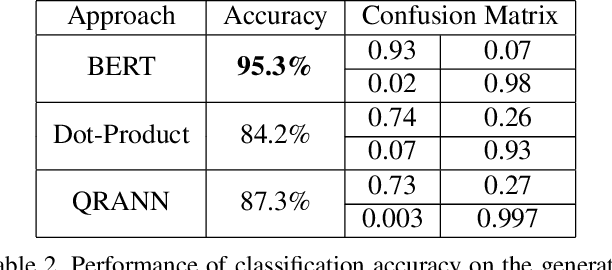
Multiple neural language models have been developed recently, e.g., BERT and XLNet, and achieved impressive results in various NLP tasks including sentence classification, question answering and document ranking. In this paper, we explore the use of the popular bidirectional language model, BERT, to model and learn the relevance between English queries and foreign-language documents in the task of cross-lingual information retrieval. A deep relevance matching model based on BERT is introduced and trained by finetuning a pretrained multilingual BERT model with weak supervision, using home-made CLIR training data derived from parallel corpora. Experimental results of the retrieval of Lithuanian documents against short English queries show that our model is effective and outperforms the competitive baseline approaches.
Towards a New Understanding of the Training of Neural Networks with Mislabeled Training Data
Sep 18, 2019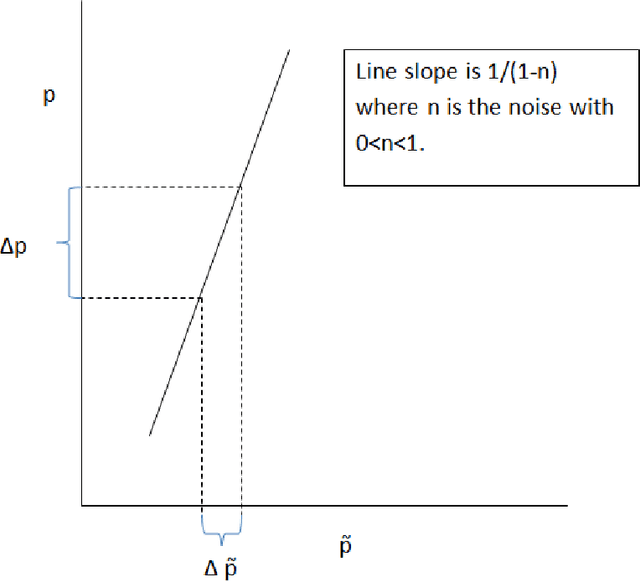
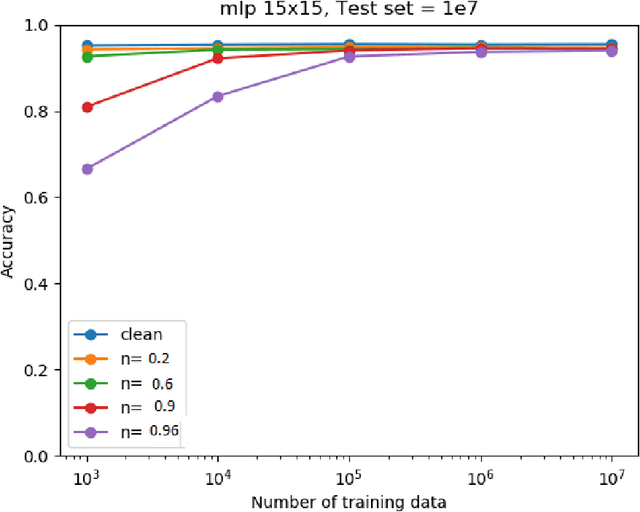
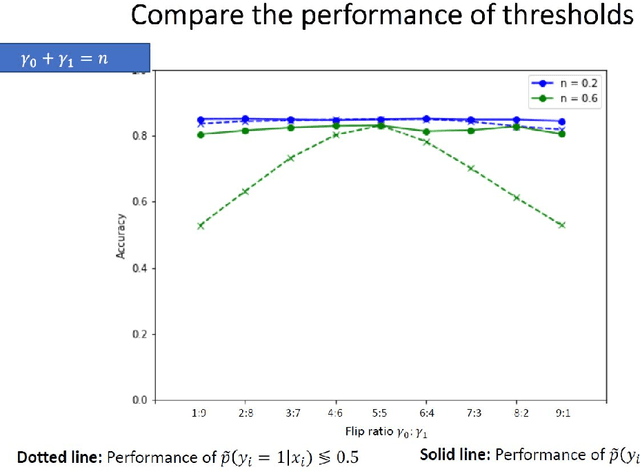
We investigate the problem of machine learning with mislabeled training data. We try to make the effects of mislabeled training better understood through analysis of the basic model and equations that characterize the problem. This includes results about the ability of the noisy model to make the same decisions as the clean model and the effects of noise on model performance. In addition to providing better insights we also are able to show that the Maximum Likelihood (ML) estimate of the parameters of the noisy model determine those of the clean model. This property is obtained through the use of the ML invariance property and leads to an approach to developing a classifier when training has been mislabeled: namely train the classifier on noisy data and adjust the decision threshold based on the noise levels and/or class priors. We show how our approach to mislabeled training works with multi-layered perceptrons (MLPs).