 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing heterogeneity in semi-supervised transcription hypotheses to improve code-switched speech recognition
Jun 14, 2021
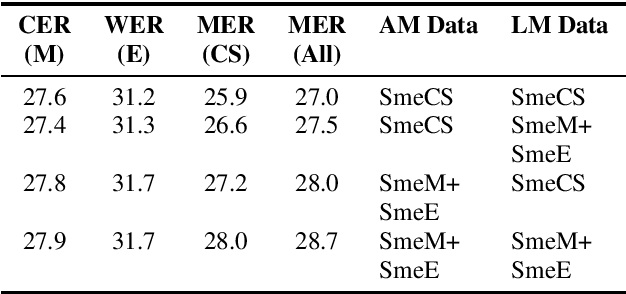
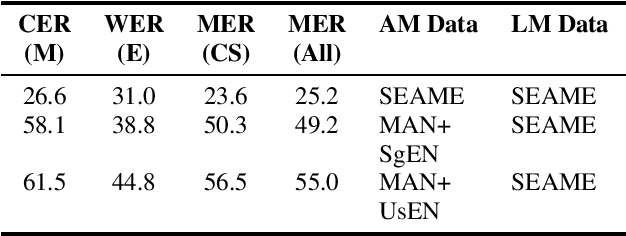
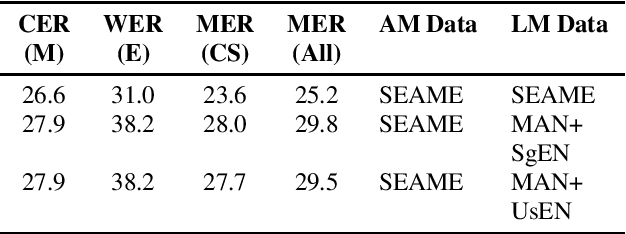
Modeling code-switched speech is an important problem in automatic speech recognition (ASR). Labeled code-switched data are rare, so monolingual data are often used to model code-switched speech. These monolingual data may be more closely matched to one of the languages in the code-switch pair. We show that such asymmetry can bias prediction toward the better-matched language and degrade overall model performance. To address this issue, we propose a semi-supervised approach for code-switched ASR. We consider the case of English-Mandarin code-switching, and the problem of using monolingual data to build bilingual "transcription models'' for annotation of unlabeled code-switched data. We first build multiple transcription models so that their individual predictions are variously biased toward either English or Mandarin. We then combine these biased transcriptions using confidence-based selection. This strategy generates a superior transcript for semi-supervised training, and obtains a 19% relative improvement compared to a semi-supervised system that relies on a transcription model built with only the best-matched monolingual data.