 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Conversational Speech Summarization with Large Language Models
Aug 12, 2024Cross-lingual conversational speech summarization is an important problem, but suffers from a dearth of resources. While transcriptions exist for a number of languages, translated conversational speech is rare and datasets containing summaries are non-existent. We build upon the existing Fisher and Callhome Spanish-English Speech Translation corpus by supplementing the translations with summaries. The summaries are generated using GPT-4 from the reference translations and are treated as ground truth. The task is to generate similar summaries in the presence of transcription and translation errors. We build a baseline cascade-based system using open-source speech recognition and machine translation models. We test a range of LLMs for summarization and analyze the impact of transcription and translation errors. Adapting the Mistral-7B model for this task performs significantly better than off-the-shelf models and matches the performance of GPT-4.
Using heterogeneity in semi-supervised transcription hypotheses to improve code-switched speech recognition
Jun 14, 2021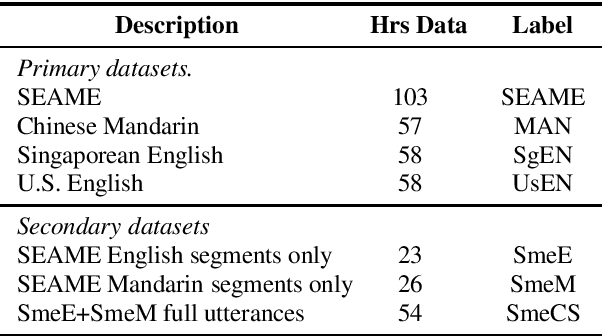
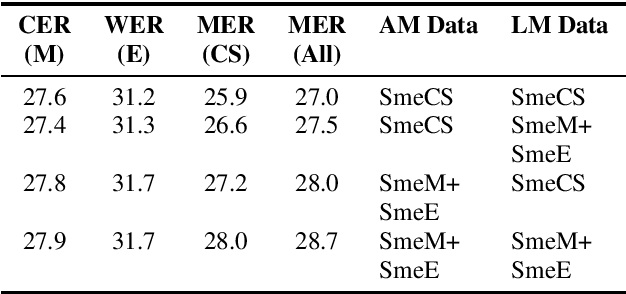
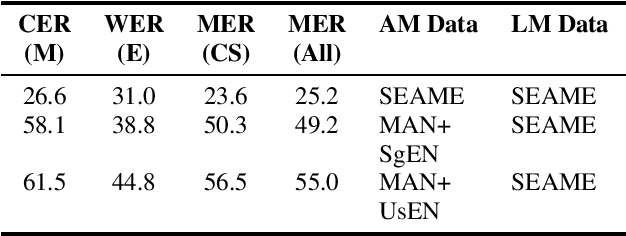
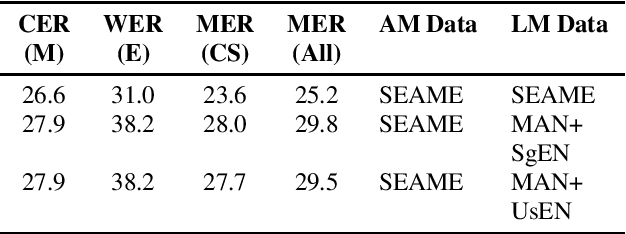
Modeling code-switched speech is an important problem in automatic speech recognition (ASR). Labeled code-switched data are rare, so monolingual data are often used to model code-switched speech. These monolingual data may be more closely matched to one of the languages in the code-switch pair. We show that such asymmetry can bias prediction toward the better-matched language and degrade overall model performance. To address this issue, we propose a semi-supervised approach for code-switched ASR. We consider the case of English-Mandarin code-switching, and the problem of using monolingual data to build bilingual "transcription models'' for annotation of unlabeled code-switched data. We first build multiple transcription models so that their individual predictions are variously biased toward either English or Mandarin. We then combine these biased transcriptions using confidence-based selection. This strategy generates a superior transcript for semi-supervised training, and obtains a 19% relative improvement compared to a semi-supervised system that relies on a transcription model built with only the best-matched monolingual data.
Speech Synthesis as Augmentation for Low-Resource ASR
Dec 23, 2020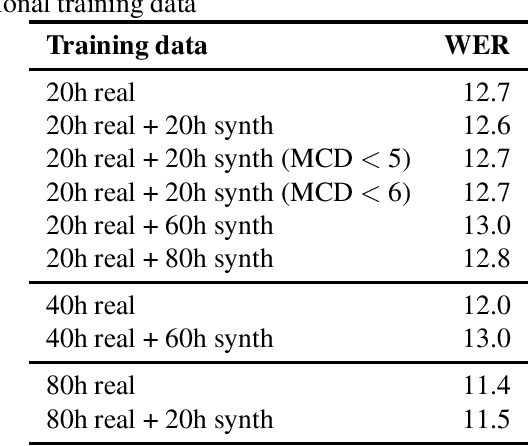

Speech synthesis might hold the key to low-resource speech recognition. Data augmentation techniques have become an essential part of modern speech recognition training. Yet, they are simple, naive, and rarely reflect real-world conditions. Meanwhile, speech synthesis techniques have been rapidly getting closer to the goal of achieving human-like speech. In this paper, we investigate the possibility of using synthesized speech as a form of data augmentation to lower the resources necessary to build a speech recognizer. We experiment with three different kinds of synthesizers: statistical parametric, neural, and adversarial. Our findings are interesting and point to new research directions for the future.