 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSotto Voce: Federated Speech Recognition with Differential Privacy Guarantees
Jul 16, 2022
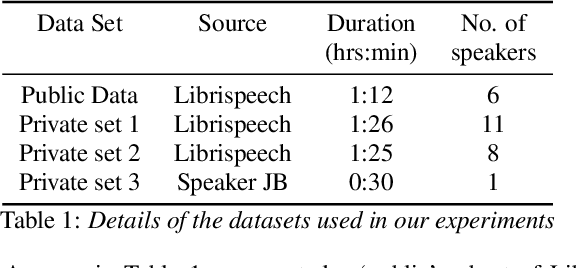
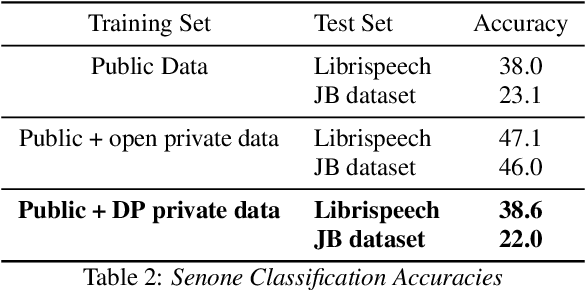
Speech data is expensive to collect, and incredibly sensitive to its sources. It is often the case that organizations independently collect small datasets for their own use, but often these are not performant for the demands of machine learning. Organizations could pool these datasets together and jointly build a strong ASR system; sharing data in the clear, however, comes with tremendous risk, in terms of intellectual property loss as well as loss of privacy of the individuals who exist in the dataset. In this paper, we offer a potential solution for learning an ML model across multiple organizations where we can provide mathematical guarantees limiting privacy loss. We use a Federated Learning approach built on a strong foundation of Differential Privacy techniques. We apply these to a senone classification prototype and demonstrate that the model improves with the addition of private data while still respecting privacy.
Speech Synthesis as Augmentation for Low-Resource ASR
Dec 23, 2020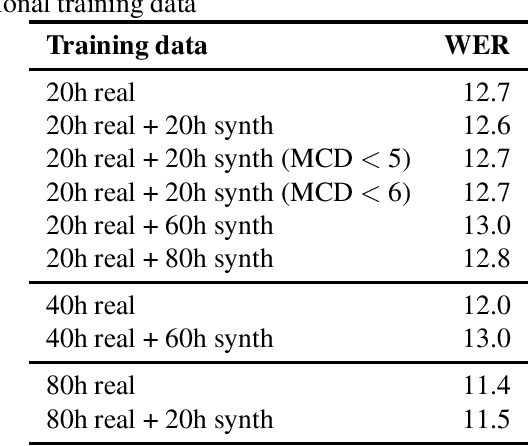

Speech synthesis might hold the key to low-resource speech recognition. Data augmentation techniques have become an essential part of modern speech recognition training. Yet, they are simple, naive, and rarely reflect real-world conditions. Meanwhile, speech synthesis techniques have been rapidly getting closer to the goal of achieving human-like speech. In this paper, we investigate the possibility of using synthesized speech as a form of data augmentation to lower the resources necessary to build a speech recognizer. We experiment with three different kinds of synthesizers: statistical parametric, neural, and adversarial. Our findings are interesting and point to new research directions for the future.