 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Conversational Speech Summarization with Large Language Models
Aug 12, 2024Cross-lingual conversational speech summarization is an important problem, but suffers from a dearth of resources. While transcriptions exist for a number of languages, translated conversational speech is rare and datasets containing summaries are non-existent. We build upon the existing Fisher and Callhome Spanish-English Speech Translation corpus by supplementing the translations with summaries. The summaries are generated using GPT-4 from the reference translations and are treated as ground truth. The task is to generate similar summaries in the presence of transcription and translation errors. We build a baseline cascade-based system using open-source speech recognition and machine translation models. We test a range of LLMs for summarization and analyze the impact of transcription and translation errors. Adapting the Mistral-7B model for this task performs significantly better than off-the-shelf models and matches the performance of GPT-4.
Training Autoregressive Speech Recognition Models with Limited in-domain Supervision
Oct 27, 2022
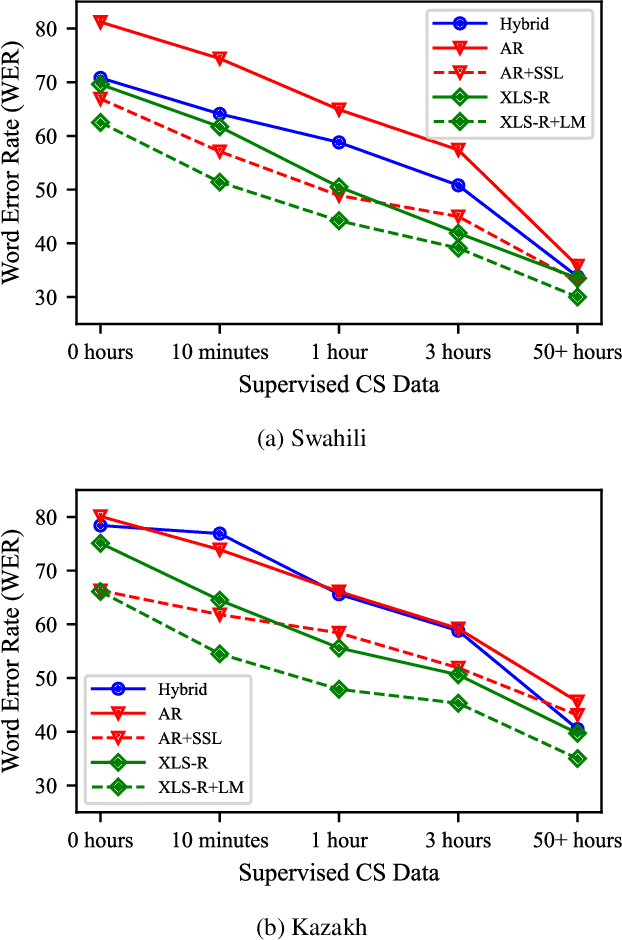

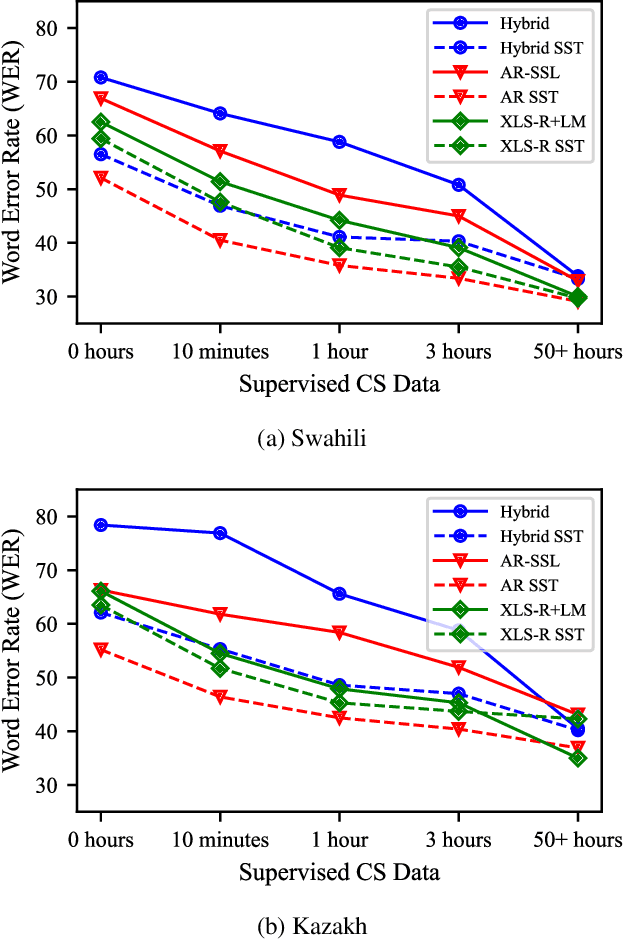
Advances in self-supervised learning have significantly reduced the amount of transcribed audio required for training. However, the majority of work in this area is focused on read speech. We explore limited supervision in the domain of conversational speech. While we assume the amount of in-domain data is limited, we augment the model with open source read speech data. The XLS-R model has been shown to perform well with limited adaptation data and serves as a strong baseline. We use untranscribed data for self-supervised learning and semi-supervised training in an autoregressive encoder-decoder model. We demonstrate that by using the XLS-R model for pseudotranscription, a much smaller autoregressive model can outperform a finetuned XLS-R model when transcribed in-domain data is limited, reducing WER by as much as 8% absolute.
Combining Unsupervised and Text Augmented Semi-Supervised Learning for Low Resourced Autoregressive Speech Recognition
Oct 29, 2021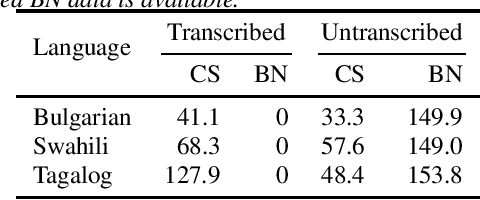
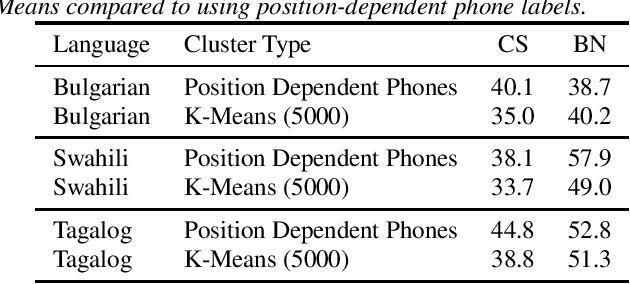
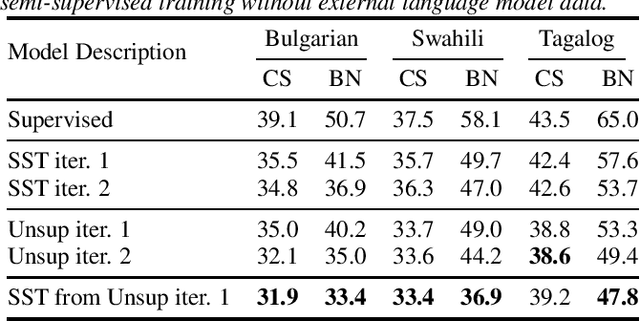
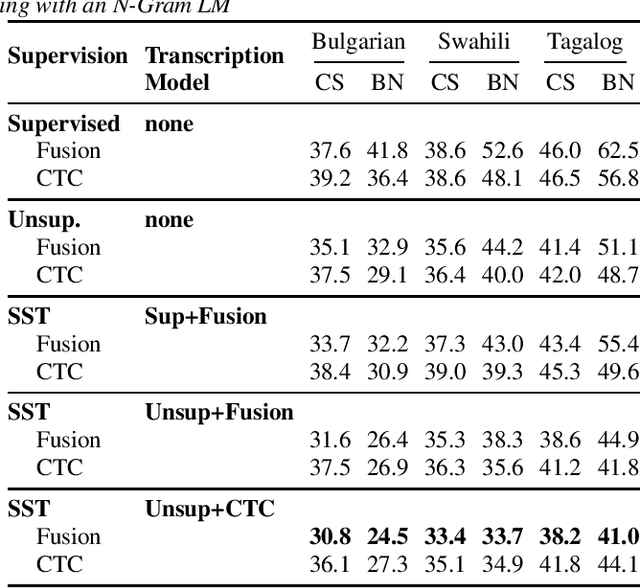
Recent advances in unsupervised representation learning have demonstrated the impact of pretraining on large amounts of read speech. We adapt these techniques for domain adaptation in low-resource -- both in terms of data and compute -- conversational and broadcast domains. Moving beyond CTC, we pretrain state-of-the-art Conformer models in an unsupervised manner. While the unsupervised approach outperforms traditional semi-supervised training, the techniques are complementary. Combining the techniques is a 5% absolute improvement in WER, averaged over all conditions, compared to semi-supervised training alone. Additional text data is incorporated through external language models. By using CTC-based decoding, we are better able to take advantage of the additional text data. When used as a transcription model, it allows the Conformer model to better incorporate the knowledge from the language model through semi-supervised training than shallow fusion. Final performance is an additional 2% better absolute when using CTC-based decoding for semi-supervised training compared to shallow fusion.
Overcoming Domain Mismatch in Low Resource Sequence-to-Sequence ASR Models using Hybrid Generated Pseudotranscripts
Jun 14, 2021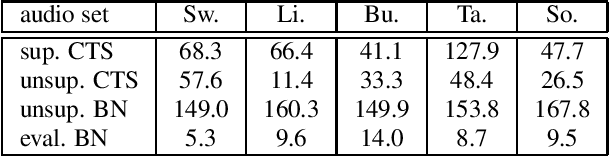
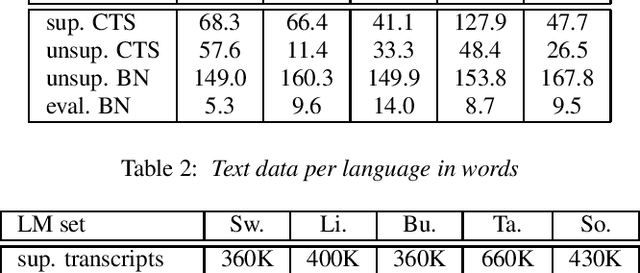
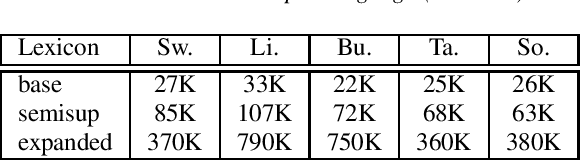
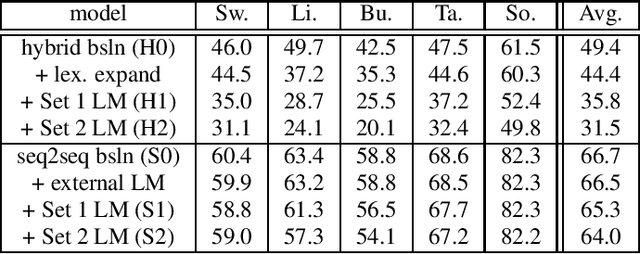
Sequence-to-sequence (seq2seq) models are competitive with hybrid models for automatic speech recognition (ASR) tasks when large amounts of training data are available. However, data sparsity and domain adaptation are more problematic for seq2seq models than their hybrid counterparts. We examine corpora of five languages from the IARPA MATERIAL program where the transcribed data is conversational telephone speech (CTS) and evaluation data is broadcast news (BN). We show that there is a sizable initial gap in such a data condition between hybrid and seq2seq models, and the hybrid model is able to further improve through the use of additional language model (LM) data. We use an additional set of untranscribed data primarily in the BN domain for semisupervised training. In semisupervised training, a seed model trained on transcribed data generates hypothesized transcripts for unlabeled domain-matched data for further training. By using a hybrid model with an expanded language model for pseudotranscription, we are able to improve our seq2seq model from an average word error rate (WER) of 66.7% across all five languages to 29.0% WER. While this puts the seq2seq model at a competitive operating point, hybrid models are still able to use additional LM data to maintain an advantage.