 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Conversion of Machine Learning Pipelines
Mar 26, 2026Transfer learning and knowledge distillation has recently gained a lot of attention in the deep learning community. One transfer approach, the student-teacher learning, has been shown to successfully create ``small'' student neural networks that mimic the performance of a much bigger and more complex ``teacher'' networks. In this paper, we investigate an extension to this approach and transfer from a non-neural-based machine learning pipeline as teacher to a neural network (NN) student, which would allow for joint optimization of the various pipeline components and a single unified inference engine for multiple ML tasks. In particular, we explore replacing the random forest classifier by transfer learning to a student NN. We experimented with various NN topologies on 100 OpenML tasks in which random forest has been one of the best solutions. Our results show that for the majority of the tasks, the student NN can indeed mimic the teacher if one can select the right NN hyper-parameters. We also investigated the use of random forest for selecting the right NN hyper-parameters.
Unsupervised Pattern Discovery from Thematic Speech Archives Based on Multilingual Bottleneck Features
Nov 03, 2020
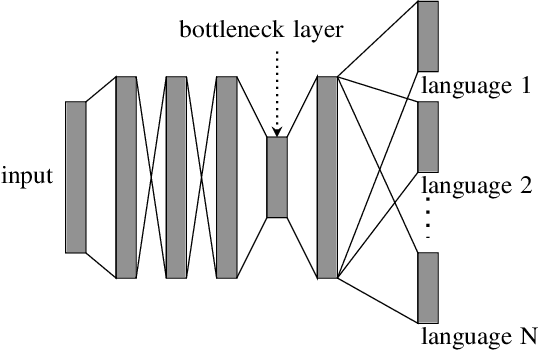
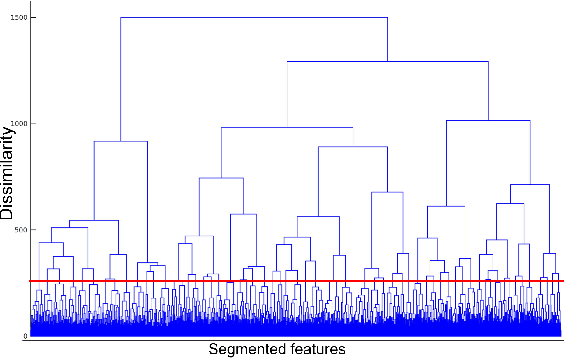
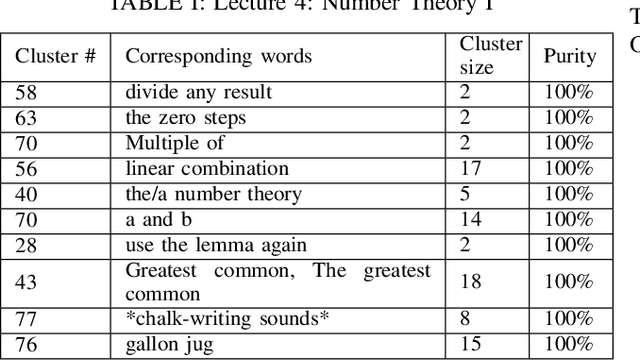
The present study tackles the problem of automatically discovering spoken keywords from untranscribed audio archives without requiring word-by-word speech transcription by automatic speech recognition (ASR) technology. The problem is of practical significance in many applications of speech analytics, including those concerning low-resource languages, and large amount of multilingual and multi-genre data. We propose a two-stage approach, which comprises unsupervised acoustic modeling and decoding, followed by pattern mining in acoustic unit sequences. The whole process starts by deriving and modeling a set of subword-level speech units with untranscribed data. With the unsupervisedly trained acoustic models, a given audio archive is represented by a pseudo transcription, from which spoken keywords can be discovered by string mining algorithms. For unsupervised acoustic modeling, a deep neural network trained by multilingual speech corpora is used to generate speech segmentation and compute bottleneck features for segment clustering. Experimental results show that the proposed system is able to effectively extract topic-related words and phrases from the lecture recordings on MIT OpenCourseWare.
Towards a New Understanding of the Training of Neural Networks with Mislabeled Training Data
Sep 18, 2019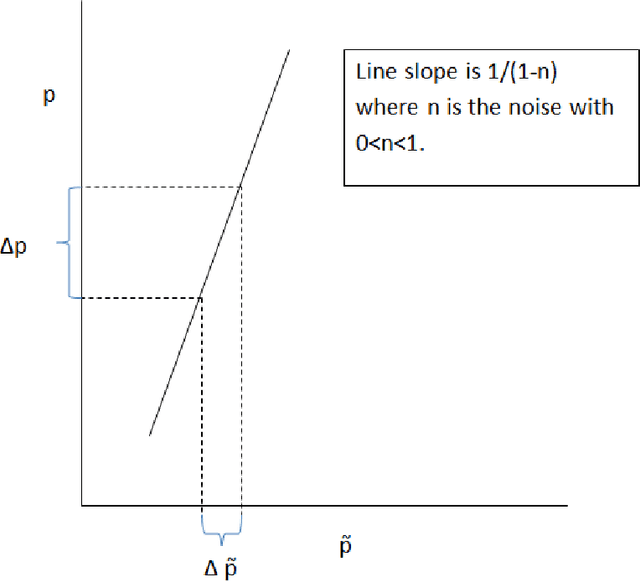
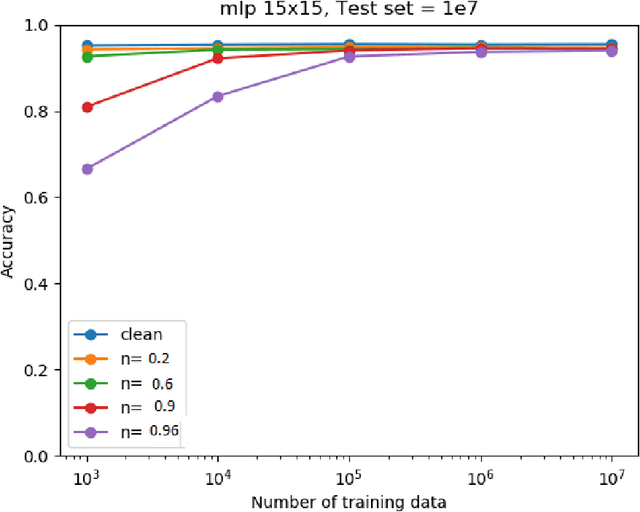
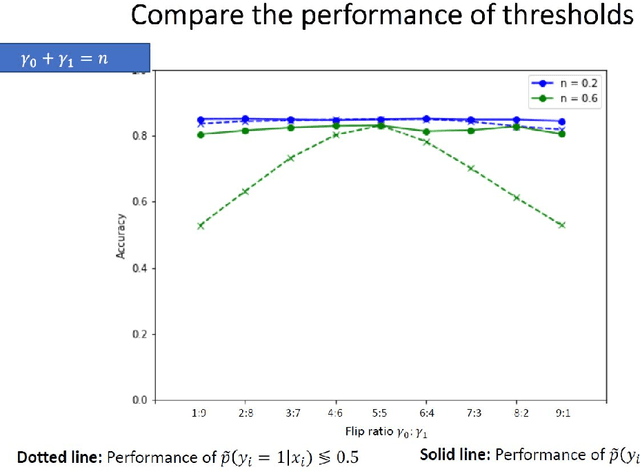
We investigate the problem of machine learning with mislabeled training data. We try to make the effects of mislabeled training better understood through analysis of the basic model and equations that characterize the problem. This includes results about the ability of the noisy model to make the same decisions as the clean model and the effects of noise on model performance. In addition to providing better insights we also are able to show that the Maximum Likelihood (ML) estimate of the parameters of the noisy model determine those of the clean model. This property is obtained through the use of the ML invariance property and leads to an approach to developing a classifier when training has been mislabeled: namely train the classifier on noisy data and adjust the decision threshold based on the noise levels and/or class priors. We show how our approach to mislabeled training works with multi-layered perceptrons (MLPs).