 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Demo is Worth a Thousand Trajectories: Action-View Augmentation for Visuomotor Policies
Jun 17, 2026Visuomotor policies for manipulation have demonstrated remarkable potential in modeling complex robotic behaviors, yet minor alterations in the robot's initial configuration and unseen obstacles easily lead to out-of-distribution observations. Without extensive data collection effort, these result in catastrophic execution failures. In this work, we introduce an effective data augmentation framework that generates visually realistic fisheye image sequences and corresponding physically feasible action trajectories from real-world eye-in-hand demonstrations, captured with a portable parallel gripper with a single fisheye camera. We introduce a novel Gaussian Splatting formulation, adapted to wide FoV fisheye cameras, to reconstruct and edit the 3D scene with unseen objects. We utilize trajectory optimization to generate smooth, collision-free, view-rendering-friendly action trajectories and render visual observations from corresponding novel views. Comprehensive experiments in simulation and the real world show that our augmentation framework improves the success rate for various manipulation tasks in both the same scene and the augmented scene with obstacles requiring collision avoidance.
* Project website: https://chuerpan.com/1001-demos.github.io/. Published at CoRL 2025
D$^3$-Subsidy: Online and Sequential Driver Subsidy Decision-Making for Large-Scale Ride-Hailing Market
May 21, 2026Ride-hailing platforms like DiDi Chuxing operate in highly dynamic environments where balancing driver supply and passenger demand is critical. Although driver-side subsidies serve as a primary lever to align these forces and improve key KPIs like completed rides (\texttt{Rides}) and gross merchandise value (\texttt{GMV}), optimizing them in production requires simultaneously meeting three constraints: (i) responsiveness to stochastic shocks, (ii) strict subsidy-rate caps, and (iii) low-latency execution at city scale. These requirements rule out expensive per-order optimization, calling for a forward-looking, constraint-aware city-level controller for online sequential decision making. To meet these requirements, we introduce D$^3$-Subsidy (Dynamic Driver-side Diffusion-based Subsidy), a hierarchical diffusion-based framework for deployable city-wide subsidy control. To bridge the train-inference gap, D$^3$-Subsidy employs a prefix-conditioned diffusion model that samples plausible future trajectories from immutable historical observations, ensuring the training protocol aligns with the fixed-history nature of online deployment. These generated plans are then decoded by a context-conditioned inverse module into low-dimensional city-level control signals. For scalable execution, we bridge the gap between city-level planning and fine-grained dispatch via a Lagrangian-dual-derived mapping, which embeds subsidy-rate caps directly into order-driver incentives without iterative optimization. Additionally, a multi-city pretraining strategy with parameter-efficient fine-tuning enables robust transfer across heterogeneous cities. Extensive offline evaluations demonstrate that D$^3$-Subsidy improves \texttt{Rides} and \texttt{GMV} while enhancing cap compliance, and a real-world A/B test confirms significant uplift while keeping budget-related violation metrics within operational thresholds.
PlexRL: Cluster-Level Orchestration of Serviceized LLM Execution for RLVR
May 20, 2026Reinforcement learning with verifiable rewards (RLVR) has recently unlocked strong reasoning capabilities in large language models (LLMs), triggering rapid exploration of new algorithms and data. However, RLVR training is notoriously inefficient: long-tailed rollouts, tool-induced stalls, and asymmetric resource requirements between rollout and training introduce substantial idle time that cannot be eliminated by job-local optimizations such as synchronous pipelining, asynchronous rollout, or colocated execution. We argue that this inefficiency is structural. While idle gaps are unavoidable within individual RLVR jobs, they are largely anti-correlated across jobs and therefore exploitable at the cluster level. Leveraging this observation, we present PlexRL, a cluster-level runtime for multiplexing unified LLM services across RLVR jobs. By centrally managing model placement, state transitions, and function-level scheduling under strict affinity constraints, PlexRL time-slices LLM execution across jobs to fill otherwise idle periods without expensive model migration. Our implementation and evaluations demonstrate that PlexRL significantly improves effective cluster capacity and reduces user GPU hour cost by maximum 37.58% while preserving algorithmic flexibility and introducing minimal per-job overhead.
NeuroRisk: Physics-Informed Neural Optimization for Risk-Aware Traffic Engineering
May 13, 2026In production Wide-Area Networks (WANs), correlated failures dominate availability losses, forcing operators to reserve large safety margins that leave substantial capacity underutilized. Achieving high utilization under strict availability targets therefore requires risk-aware Traffic Engineering (TE) over dozens to hundreds of probabilistic failure scenarios-yet solving this problem at operational timescales remains elusive. We demonstrate that existing risk-aware formulations can be unified under an embedded Sort-and-Select structure, exposing a fundamental trade-off between expressiveness and tractability: classical optimizers either restrict scenario selection for efficiency or incur prohibitive decomposition costs. While deep learning appears promising, prior Deep TE methods mainly target maximum link utilization and rely on scaling-based feasibility, which fundamentally breaks under explicit capacity constraints and scenario-dependent risk. We present NeuroRisk, a physics-informed deep unrolled optimizer that exploits the structure of Sort-and-Select. NeuroRisk enforces feasibility via gated edge-local reservations and represents scenario sets through permutation-invariant, gradient-aligned cues. Evaluations on production-style WANs show that NeuroRisk achieves small optimality gaps relative to the solver with orders of magnitude speedup $(10^2- 10^5 \times)$ on risk objectives, while outperforming neural baselines on nominal throughput.
Coherence-Minimized Sensing Matrix Design for MRI Reconstruction via Dual-Space Projection Optimization
May 03, 2026Compressed sensing magnetic resonance imaging (CS-MRI) heavily relies on the low mutual coherence between the measurement matrix and the sparsity basis. However, under highly accelerated Cartesian undersampling, the severe structural coherence between Fourier measurements and spatial bases, discrete cosine transform (DCT) for example, fundamentally violates this requirement, causing classical sparse recovery algorithms to stagnate. To mitigate this fundamental bottleneck, we propose a synergistic dual-space projection framework, denoted as $\mathbf{PAQ}$. Instead of merely designing heuristic sampling masks, our method directly reshapes the equivalent dictionary. Specifically, we introduce a diagonal-dominant random rotator $\mathbf{Q}$ in the feature space to probabilistically disrupt structural alignment, and an active orthogonalization projector $\mathbf{P}$ in the measurement space to deterministically whiten the residual correlations. We theoretically demonstrate that this dual-space mechanism bounds the mutual coherence with an exponentially decaying tail via sub-exponential distribution properties. Experimental validations on clinical MRI datasets under 20\% Cartesian sampling demonstrate that plugging the $\mathbf{PAQ}$ preconditioners into the standard ISTA solver significantly suppresses aliasing artifacts and yields consistent peak signal-to-noise ratio (PSNR) improvements.
daVinci-LLM:Towards the Science of Pretraining
Mar 28, 2026The foundational pretraining phase determines a model's capability ceiling, as post-training struggles to overcome capability foundations established during pretraining, yet it remains critically under-explored. This stems from a structural paradox: organizations with computational resources operate under commercial pressures that inhibit transparent disclosure, while academic institutions possess research freedom but lack pretraining-scale computational resources. daVinci-LLM occupies this unexplored intersection, combining industrial-scale resources with full research freedom to advance the science of pretraining. We adopt a fully-open paradigm that treats openness as scientific methodology, releasing complete data processing pipelines, full training processes, and systematic exploration results. Recognizing that the field lacks systematic methodology for data processing, we employ the Data Darwinism framework, a principled L0-L9 taxonomy from filtering to synthesis. We train a 3B-parameter model from random initialization across 8T tokens using a two-stage adaptive curriculum that progressively shifts from foundational capabilities to reasoning-intensive enhancement. Through 200+ controlled ablations, we establish that: processing depth systematically enhances capabilities, establishing it as a critical dimension alongside volume scaling; different domains exhibit distinct saturation dynamics, necessitating adaptive strategies from proportion adjustments to format shifts; compositional balance enables targeted intensification while preventing performance collapse; how evaluation protocol choices shape our understanding of pretraining progress. By releasing the complete exploration process, we enable the community to build upon our findings and systematic methodologies to form accumulative scientific knowledge in pretraining.
Multi-Mode Pneumatic Artificial Muscles Driven by Hybrid Positive-Negative Pressure
Mar 16, 2026Artificial muscles embody human aspirations for engineering lifelike robotic movements. This paper introduces an architecture for Inflatable Fluid-Driven Origami-Inspired Artificial Muscles (IN-FOAMs). A typical IN-FOAM consists of an inflatable skeleton enclosed within an outer skin, which can be driven using a combination of positive and negative pressures (e.g., compressed air and vacuum). IN-FOAMs are manufactured using low-cost heat-sealable sheet materials through heat-pressing and heat-sealing processes. Thus, they can be ultra-thin when not actuated, making them flexible, lightweight, and portable. The skeleton patterns are programmable, enabling a variety of motions, including contracting, bending, twisting, and rotating, based on specific skeleton designs. We conducted comprehensive experimental, theoretical, and numerical studies to investigate IN-FOAM's basic mechanical behavior and properties. The results show that IN-FOAM's output force and contraction can be tuned through multiple operation modes with the applied hybrid positive-negative pressure. Additionally, we propose multilayer skeleton structures to enhance the contraction ratio further, and we demonstrate a multi-channel skeleton approach that allows the integration of multiple motion modes into a single IN-FOAM. These findings indicate that IN-FOAMs hold great potential for future applications in flexible wearable devices and compact soft robotic systems.
* 20 pages, 17 figures. Published in IEEE Transactions on Robotics
Data Darwinism Part I: Unlocking the Value of Scientific Data for Pre-training
Feb 08, 2026Data quality determines foundation model performance, yet systematic processing frameworks are lacking. We introduce Data Darwinism, a ten-level taxonomy (L0-L9) that conceptualizes data-model co-evolution: advanced models produce superior data for next-generation systems. We validate this on scientific literature by constructing Darwin-Science, a 900B-token corpus (L0-L5). We identify a learnability gap in raw scientific text, which we bridge via L4 (Generative Refinement) and L5 (Cognitive Completion) using frontier LLMs to explicate reasoning and terminology. To ensure rigorous attribution, we pre-trained daVinci-origin-3B/7B models from scratch, excluding scientific content to create contamination-free baselines. After 600B tokens of continued pre-training, Darwin-Science outperforms baselines by +2.12 (3B) and +2.95 (7B) points across 20+ benchmarks, rising to +5.60 and +8.40 points on domain-aligned tasks. Systematic progression to L5 yields a +1.36 total gain, confirming that higher-level processing unlocks latent data value. We release the Darwin-Science corpus and daVinci-origin models to enable principled, co-evolutionary development.
SOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Jan 06, 2026Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.
ReSpec: Towards Optimizing Speculative Decoding in Reinforcement Learning Systems
Oct 30, 2025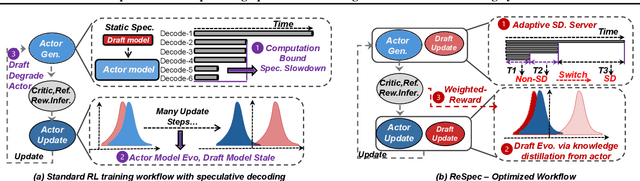

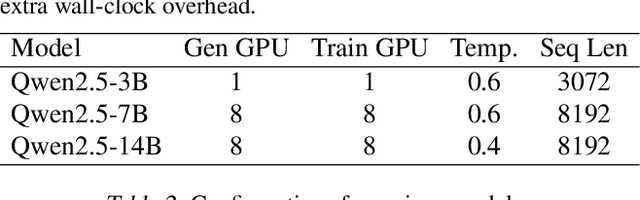

Adapting large language models (LLMs) via reinforcement learning (RL) is often bottlenecked by the generation stage, which can consume over 75\% of the training time. Speculative decoding (SD) accelerates autoregressive generation in serving systems, but its behavior under RL training remains largely unexplored. We identify three critical gaps that hinder the naive integration of SD into RL systems: diminishing speedups at large batch sizes, drafter staleness under continual actor updates, and drafter-induced policy degradation. To address these gaps, we present ReSpec, a system that adapts SD to RL through three complementary mechanisms: dynamically tuning SD configurations, evolving the drafter via knowledge distillation, and weighting updates by rollout rewards. On Qwen models (3B--14B), ReSpec achieves up to 4.5x speedup while preserving reward convergence and training stability, providing a practical solution for efficient RL-based LLM adaptation.