 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFading the Digital Ink: A Universal Black-Box Attack Framework for 3DGS Watermarking Systems
Aug 10, 2025With the rise of 3D Gaussian Splatting (3DGS), a variety of digital watermarking techniques, embedding either 1D bitstreams or 2D images, are used for copyright protection. However, the robustness of these watermarking techniques against potential attacks remains underexplored. This paper introduces the first universal black-box attack framework, the Group-based Multi-objective Evolutionary Attack (GMEA), designed to challenge these watermarking systems. We formulate the attack as a large-scale multi-objective optimization problem, balancing watermark removal with visual quality. In a black-box setting, we introduce an indirect objective function that blinds the watermark detector by minimizing the standard deviation of features extracted by a convolutional network, thus rendering the feature maps uninformative. To manage the vast search space of 3DGS models, we employ a group-based optimization strategy to partition the model into multiple, independent sub-optimization problems. Experiments demonstrate that our framework effectively removes both 1D and 2D watermarks from mainstream 3DGS watermarking methods while maintaining high visual fidelity. This work reveals critical vulnerabilities in existing 3DGS copyright protection schemes and calls for the development of more robust watermarking systems.
Adversarial Data Collection: Human-Collaborative Perturbations for Efficient and Robust Robotic Imitation Learning
Mar 14, 2025



The pursuit of data efficiency, where quality outweighs quantity, has emerged as a cornerstone in robotic manipulation, especially given the high costs associated with real-world data collection. We propose that maximizing the informational density of individual demonstrations can dramatically reduce reliance on large-scale datasets while improving task performance. To this end, we introduce Adversarial Data Collection, a Human-in-the-Loop (HiL) framework that redefines robotic data acquisition through real-time, bidirectional human-environment interactions. Unlike conventional pipelines that passively record static demonstrations, ADC adopts a collaborative perturbation paradigm: during a single episode, an adversarial operator dynamically alters object states, environmental conditions, and linguistic commands, while the tele-operator adaptively adjusts actions to overcome these evolving challenges. This process compresses diverse failure-recovery behaviors, compositional task variations, and environmental perturbations into minimal demonstrations. Our experiments demonstrate that ADC-trained models achieve superior compositional generalization to unseen task instructions, enhanced robustness to perceptual perturbations, and emergent error recovery capabilities. Strikingly, models trained with merely 20% of the demonstration volume collected through ADC significantly outperform traditional approaches using full datasets. These advances bridge the gap between data-centric learning paradigms and practical robotic deployment, demonstrating that strategic data acquisition, not merely post-hoc processing, is critical for scalable, real-world robot learning. Additionally, we are curating a large-scale ADC-Robotics dataset comprising real-world manipulation tasks with adversarial perturbations. This benchmark will be open-sourced to facilitate advancements in robotic imitation learning.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
Phys4DGen: A Physics-Driven Framework for Controllable and Efficient 4D Content Generation from a Single Image
Nov 25, 2024
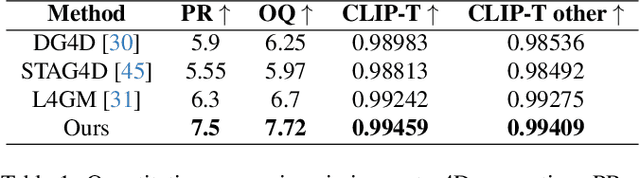
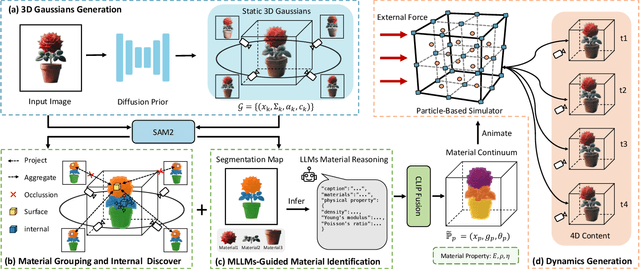
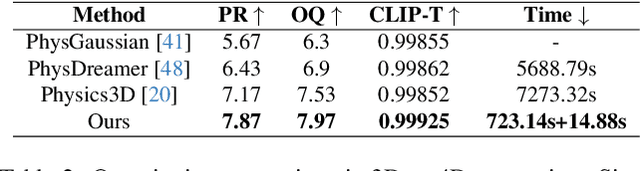
The task of 4D content generation involves creating dynamic 3D models that evolve over time in response to specific input conditions, such as images. Existing methods rely heavily on pre-trained video diffusion models to guide 4D content dynamics, but these approaches often fail to capture essential physical principles, as video diffusion models lack a robust understanding of real-world physics. Moreover, these models face challenges in providing fine-grained control over dynamics and exhibit high computational costs. In this work, we propose Phys4DGen, a novel, high-efficiency framework that generates physics-compliant 4D content from a single image with enhanced control capabilities. Our approach uniquely integrates physical simulations into the 4D generation pipeline, ensuring adherence to fundamental physical laws. Inspired by the human ability to infer physical properties visually, we introduce a Physical Perception Module (PPM) that discerns the material properties and structural components of the 3D object from the input image, facilitating accurate downstream simulations. Phys4DGen significantly accelerates the 4D generation process by eliminating iterative optimization steps in the dynamics modeling phase. It allows users to intuitively control the movement speed and direction of generated 4D content by adjusting external forces, achieving finely tunable, physically plausible animations. Extensive evaluations show that Phys4DGen outperforms existing methods in both inference speed and physical realism, producing high-quality, controllable 4D content.
BatGPT-Chem: A Foundation Large Model For Retrosynthesis Prediction
Aug 19, 2024
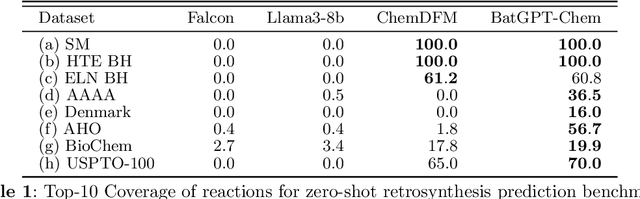
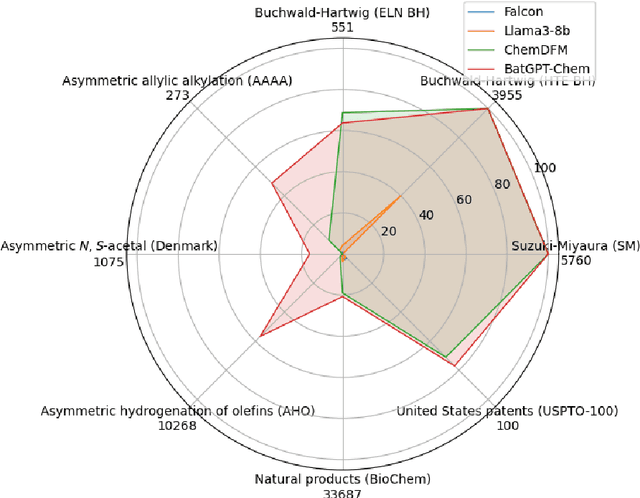
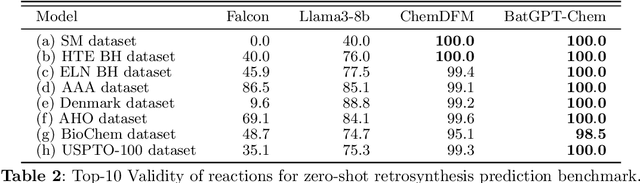
Retrosynthesis analysis is pivotal yet challenging in drug discovery and organic chemistry. Despite the proliferation of computational tools over the past decade, AI-based systems often fall short in generalizing across diverse reaction types and exploring alternative synthetic pathways. This paper presents BatGPT-Chem, a large language model with 15 billion parameters, tailored for enhanced retrosynthesis prediction. Integrating chemical tasks via a unified framework of natural language and SMILES notation, this approach synthesizes extensive instructional data from an expansive chemical database. Employing both autoregressive and bidirectional training techniques across over one hundred million instances, BatGPT-Chem captures a broad spectrum of chemical knowledge, enabling precise prediction of reaction conditions and exhibiting strong zero-shot capabilities. Superior to existing AI methods, our model demonstrates significant advancements in generating effective strategies for complex molecules, as validated by stringent benchmark tests. BatGPT-Chem not only boosts the efficiency and creativity of retrosynthetic analysis but also establishes a new standard for computational tools in synthetic design. This development empowers chemists to adeptly address the synthesis of novel compounds, potentially expediting the innovation cycle in drug manufacturing and materials science. We release our trial platform at \url{https://www.batgpt.net/dapp/chem}.
FMDNN: A Fuzzy-guided Multi-granular Deep Neural Network for Histopathological Image Classification
Jul 22, 2024



Histopathological image classification constitutes a pivotal task in computer-aided diagnostics. The precise identification and categorization of histopathological images are of paramount significance for early disease detection and treatment. In the diagnostic process of pathologists, a multi-tiered approach is typically employed to assess abnormalities in cell regions at different magnifications. However, feature extraction is often performed at a single granularity, overlooking the multi-granular characteristics of cells. To address this issue, we propose the Fuzzy-guided Multi-granularity Deep Neural Network (FMDNN). Inspired by the multi-granular diagnostic approach of pathologists, we perform feature extraction on cell structures at coarse, medium, and fine granularity, enabling the model to fully harness the information in histopathological images. We incorporate the theory of fuzzy logic to address the challenge of redundant key information arising during multi-granular feature extraction. Cell features are described from different perspectives using multiple fuzzy membership functions, which are fused to create universal fuzzy features. A fuzzy-guided cross-attention module guides universal fuzzy features toward multi-granular features. We propagate these features through an encoder to all patch tokens, aiming to achieve enhanced classification accuracy and robustness. In experiments on multiple public datasets, our model exhibits a significant improvement in accuracy over commonly used classification methods for histopathological image classification and shows commendable interpretability.
* This paper has been accepted by IEEE Transactions on Fuzzy Systems for publication. Permission from IEEE must be obtained for all other uses, in any current or future media. The final version is available at [doi: 10.1109/TFUZZ.2024.3410929]
Seeking Common but Distinguishing Difference, A Joint Aspect-based Sentiment Analysis Model
Nov 18, 2021


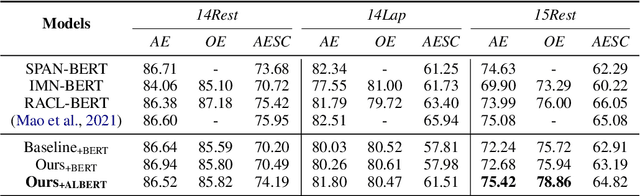
Aspect-based sentiment analysis (ABSA) task consists of three typical subtasks: aspect term extraction, opinion term extraction, and sentiment polarity classification. These three subtasks are usually performed jointly to save resources and reduce the error propagation in the pipeline. However, most of the existing joint models only focus on the benefits of encoder sharing between subtasks but ignore the difference. Therefore, we propose a joint ABSA model, which not only enjoys the benefits of encoder sharing but also focuses on the difference to improve the effectiveness of the model. In detail, we introduce a dual-encoder design, in which a pair encoder especially focuses on candidate aspect-opinion pair classification, and the original encoder keeps attention on sequence labeling. Empirical results show that our proposed model shows robustness and significantly outperforms the previous state-of-the-art on four benchmark datasets.
Heterogeneous Ground and Air Platforms, Homogeneous Sensing: Team CSIRO Data61's Approach to the DARPA Subterranean Challenge
Apr 19, 2021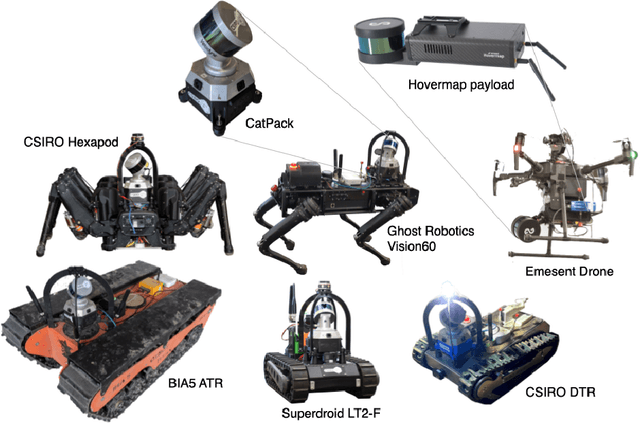
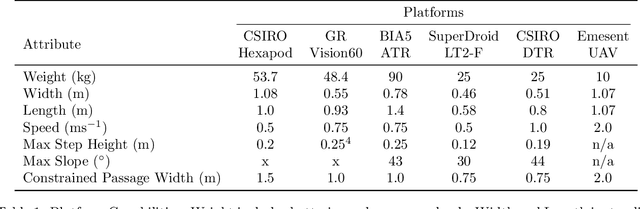
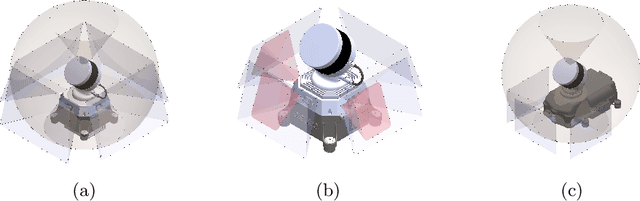
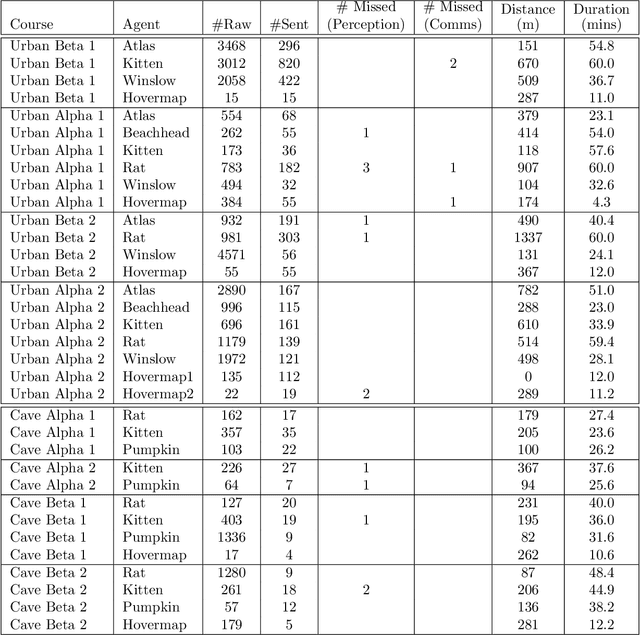
Heterogeneous teams of robots, leveraging a balance between autonomy and human interaction, bring powerful capabilities to the problem of exploring dangerous, unstructured subterranean environments. Here we describe the solution developed by Team CSIRO Data61, consisting of CSIRO, Emesent and Georgia Tech, during the DARPA Subterranean Challenge. These presented systems were fielded in the Tunnel Circuit in August 2019, the Urban Circuit in February 2020, and in our own Cave event, conducted in September 2020. A unique capability of the fielded team is the homogeneous sensing of the platforms utilised, which is leveraged to obtain a decentralised multi-agent SLAM solution on each platform (both ground agents and UAVs) using peer-to-peer communications. This enabled a shift in focus from constructing a pervasive communications network to relying on multi-agent autonomy, motivated by experiences in early circuit events. These experiences also showed the surprising capability of rugged tracked platforms for challenging terrain, which in turn led to the heterogeneous team structure based on a BIA5 OzBot Titan ground robot and an Emesent Hovermap UAV, supplemented by smaller tracked or legged ground robots. The ground agents use a common CatPack perception module, which allowed reuse of the perception and autonomy stack across all ground agents with minimal adaptation.
Exploring Imitation Learning for Autonomous Driving with Feedback Synthesizer and Differentiable Rasterization
Mar 02, 2021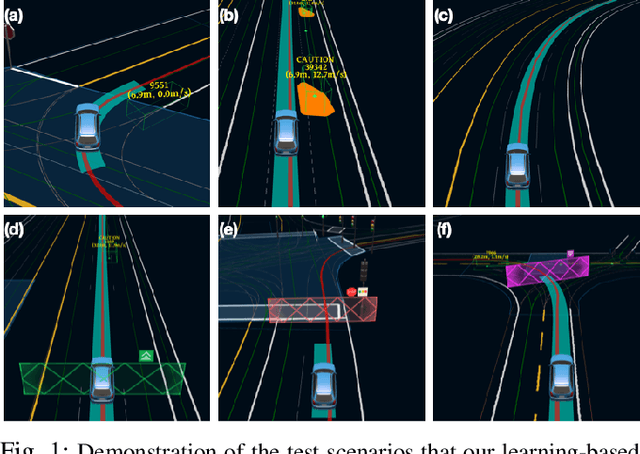
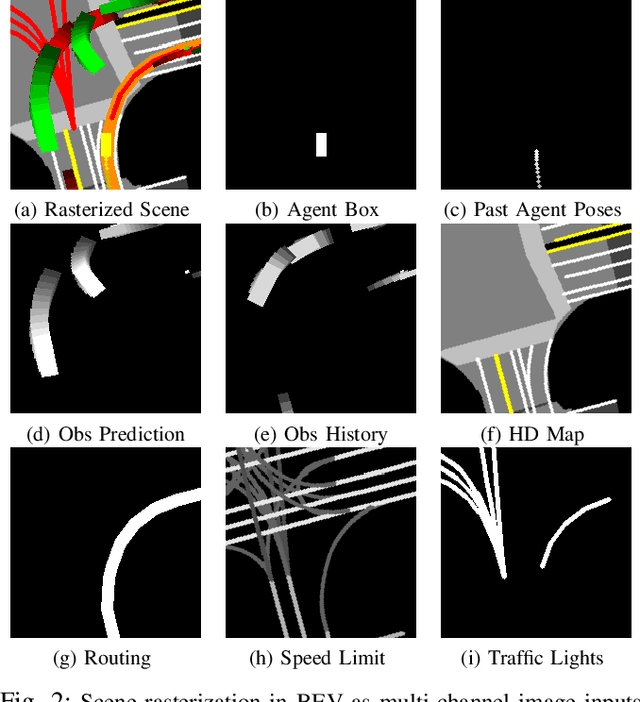
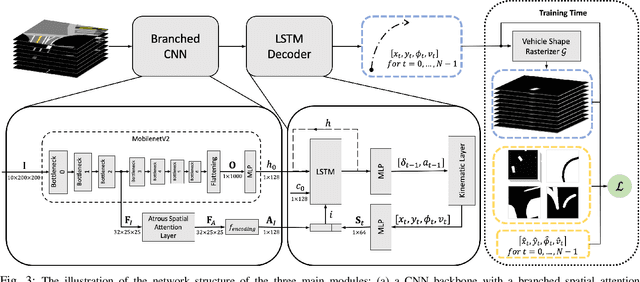

We present a learning-based planner that aims to robustly drive a vehicle by mimicking human drivers' driving behavior. We leverage a mid-to-mid approach that allows us to manipulate the input to our imitation learning network freely. With that in mind, we propose a novel feedback synthesizer for data augmentation. It allows our agent to gain more driving experience in various previously unseen environments that are likely to encounter, thus improving overall performance. This is in contrast to prior works that rely purely on random synthesizers. Furthermore, rather than completely commit to imitating, we introduce task losses that penalize undesirable behaviors, such as collision, off-road, and so on. Unlike prior works, this is done by introducing a differentiable vehicle rasterizer that directly converts the waypoints output by the network into images. This effectively avoids the usage of heavyweight ConvLSTM networks, therefore, yields a faster model inference time. About the network architecture, we exploit an attention mechanism that allows the network to reason critical objects in the scene and produce better interpretable attention heatmaps. To further enhance the safety and robustness of the network, we add an optional optimization-based post-processing planner improving the driving comfort. We comprehensively validate our method's effectiveness in different scenarios that are specifically created for evaluating self-driving vehicles. Results demonstrate that our learning-based planner achieves high intelligence and can handle complex situations. Detailed ablation and visualization analysis are included to further demonstrate each of our proposed modules' effectiveness in our method.
A Learning-Based Tune-Free Control Framework for Large Scale Autonomous Driving System Deployment
Nov 09, 2020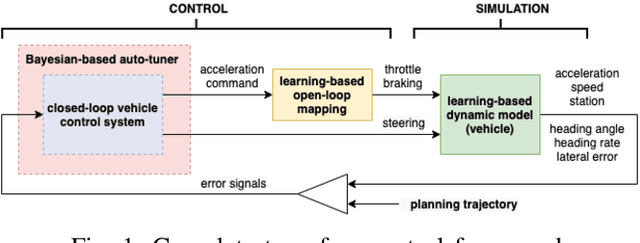
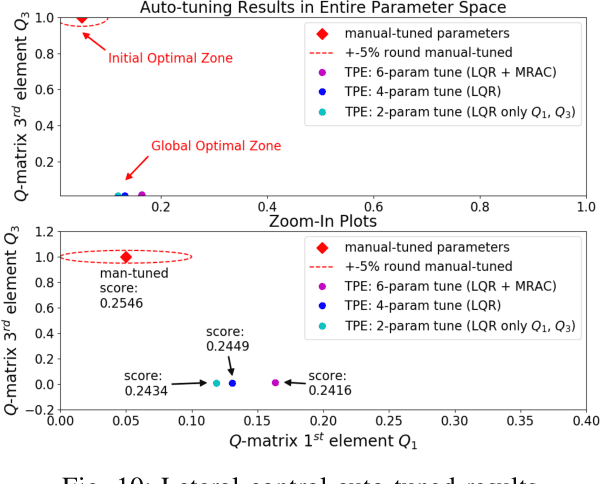
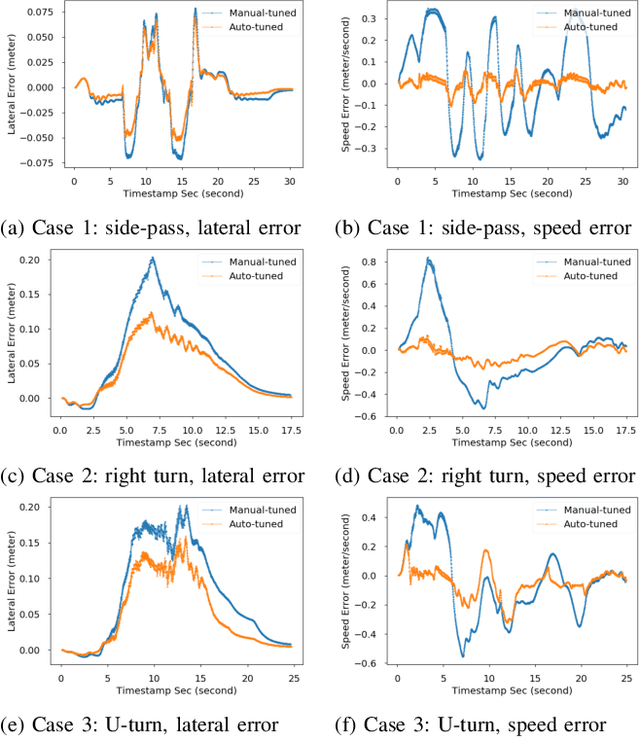
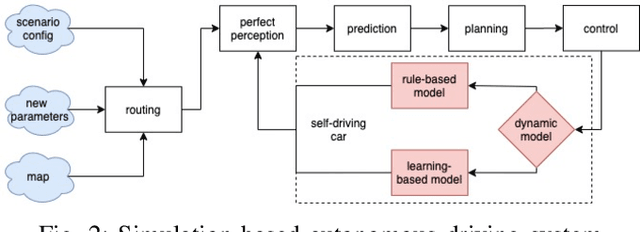
This paper presents the design of a tune-free (human-out-of-the-loop parameter tuning) control framework, aiming at accelerating large scale autonomous driving system deployed on various vehicles and driving environments. The framework consists of three machine-learning-based procedures, which jointly automate the control parameter tuning for autonomous driving, including: a learning-based dynamic modeling procedure, to enable the control-in-the-loop simulation with highly accurate vehicle dynamics for parameter tuning; a learning-based open-loop mapping procedure, to solve the feedforward control parameters tuning; and more significantly, a Bayesian-optimization-based closed-loop parameter tuning procedure, to automatically tune feedback control (PID, LQR, MRAC, MPC, etc.) parameters in simulation environment. The paper shows an improvement in control performance with a significant increase in parameter tuning efficiency, in both simulation and road tests. This framework has been validated on different vehicles in US and China.