 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaMo: Unsupervised Learning of Generalizable Robot Motion from Compact State Representation
Oct 06, 2025A fundamental challenge in embodied intelligence is developing expressive and compact state representations for efficient world modeling and decision making. However, existing methods often fail to achieve this balance, yielding representations that are either overly redundant or lacking in task-critical information. We propose an unsupervised approach that learns a highly compressed two-token state representation using a lightweight encoder and a pre-trained Diffusion Transformer (DiT) decoder, capitalizing on its strong generative prior. Our representation is efficient, interpretable, and integrates seamlessly into existing VLA-based models, improving performance by 14.3% on LIBERO and 30% in real-world task success with minimal inference overhead. More importantly, we find that the difference between these tokens, obtained via latent interpolation, naturally serves as a highly effective latent action, which can be further decoded into executable robot actions. This emergent capability reveals that our representation captures structured dynamics without explicit supervision. We name our method StaMo for its ability to learn generalizable robotic Motion from compact State representation, which is encoded from static images, challenging the prevalent dependence to learning latent action on complex architectures and video data. The resulting latent actions also enhance policy co-training, outperforming prior methods by 10.4% with improved interpretability. Moreover, our approach scales effectively across diverse data sources, including real-world robot data, simulation, and human egocentric video.
ReSim: Reliable World Simulation for Autonomous Driving
Jun 11, 2025How can we reliably simulate future driving scenarios under a wide range of ego driving behaviors? Recent driving world models, developed exclusively on real-world driving data composed mainly of safe expert trajectories, struggle to follow hazardous or non-expert behaviors, which are rare in such data. This limitation restricts their applicability to tasks such as policy evaluation. In this work, we address this challenge by enriching real-world human demonstrations with diverse non-expert data collected from a driving simulator (e.g., CARLA), and building a controllable world model trained on this heterogeneous corpus. Starting with a video generator featuring a diffusion transformer architecture, we devise several strategies to effectively integrate conditioning signals and improve prediction controllability and fidelity. The resulting model, ReSim, enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. To close the gap between high-fidelity simulation and applications that require reward signals to judge different actions, we introduce a Video2Reward module that estimates a reward from ReSim's simulated future. Our ReSim paradigm achieves up to 44% higher visual fidelity, improves controllability for both expert and non-expert actions by over 50%, and boosts planning and policy selection performance on NAVSIM by 2% and 25%, respectively.
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
May 09, 2025A generalist robot should perform effectively across various environments. However, most existing approaches heavily rely on scaling action-annotated data to enhance their capabilities. Consequently, they are often limited to single physical specification and struggle to learn transferable knowledge across different embodiments and environments. To confront these limitations, we propose UniVLA, a new framework for learning cross-embodiment vision-language-action (VLA) policies. Our key innovation is to derive task-centric action representations from videos with a latent action model. This enables us to exploit extensive data across a wide spectrum of embodiments and perspectives. To mitigate the effect of task-irrelevant dynamics, we incorporate language instructions and establish a latent action model within the DINO feature space. Learned from internet-scale videos, the generalist policy can be deployed to various robots through efficient latent action decoding. We obtain state-of-the-art results across multiple manipulation and navigation benchmarks, as well as real-robot deployments. UniVLA achieves superior performance over OpenVLA with less than 1/20 of pretraining compute and 1/10 of downstream data. Continuous performance improvements are observed as heterogeneous data, even including human videos, are incorporated into the training pipeline. The results underscore UniVLA's potential to facilitate scalable and efficient robot policy learning.
AdaWorld: Learning Adaptable World Models with Latent Actions
Mar 24, 2025World models aim to learn action-controlled prediction models and have proven essential for the development of intelligent agents. However, most existing world models rely heavily on substantial action-labeled data and costly training, making it challenging to adapt to novel environments with heterogeneous actions through limited interactions. This limitation can hinder their applicability across broader domains. To overcome this challenge, we propose AdaWorld, an innovative world model learning approach that enables efficient adaptation. The key idea is to incorporate action information during the pretraining of world models. This is achieved by extracting latent actions from videos in a self-supervised manner, capturing the most critical transitions between frames. We then develop an autoregressive world model that conditions on these latent actions. This learning paradigm enables highly adaptable world models, facilitating efficient transfer and learning of new actions even with limited interactions and finetuning. Our comprehensive experiments across multiple environments demonstrate that AdaWorld achieves superior performance in both simulation quality and visual planning.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
May 27, 2024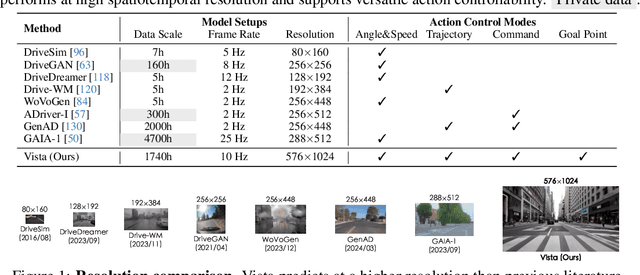


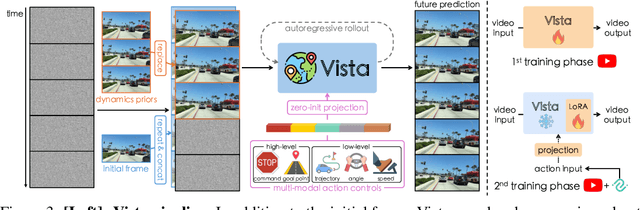
World models can foresee the outcomes of different actions, which is of paramount importance for autonomous driving. Nevertheless, existing driving world models still have limitations in generalization to unseen environments, prediction fidelity of critical details, and action controllability for flexible application. In this paper, we present Vista, a generalizable driving world model with high fidelity and versatile controllability. Based on a systematic diagnosis of existing methods, we introduce several key ingredients to address these limitations. To accurately predict real-world dynamics at high resolution, we propose two novel losses to promote the learning of moving instances and structural information. We also devise an effective latent replacement approach to inject historical frames as priors for coherent long-horizon rollouts. For action controllability, we incorporate a versatile set of controls from high-level intentions (command, goal point) to low-level maneuvers (trajectory, angle, and speed) through an efficient learning strategy. After large-scale training, the capabilities of Vista can seamlessly generalize to different scenarios. Extensive experiments on multiple datasets show that Vista outperforms the most advanced general-purpose video generator in over 70% of comparisons and surpasses the best-performing driving world model by 55% in FID and 27% in FVD. Moreover, for the first time, we utilize the capacity of Vista itself to establish a generalizable reward for real-world action evaluation without accessing the ground truth actions.
Content-aware Masked Image Modeling Transformer for Stereo Image Compression
Mar 20, 2024Existing learning-based stereo image codec adopt sophisticated transformation with simple entropy models derived from single image codecs to encode latent representations. However, those entropy models struggle to effectively capture the spatial-disparity characteristics inherent in stereo images, which leads to suboptimal rate-distortion results. In this paper, we propose a stereo image compression framework, named CAMSIC. CAMSIC independently transforms each image to latent representation and employs a powerful decoder-free Transformer entropy model to capture both spatial and disparity dependencies, by introducing a novel content-aware masked image modeling (MIM) technique. Our content-aware MIM facilitates efficient bidirectional interaction between prior information and estimated tokens, which naturally obviates the need for an extra Transformer decoder. Experiments show that our stereo image codec achieves state-of-the-art rate-distortion performance on two stereo image datasets Cityscapes and InStereo2K with fast encoding and decoding speed.
Generalized Predictive Model for Autonomous Driving
Mar 14, 2024

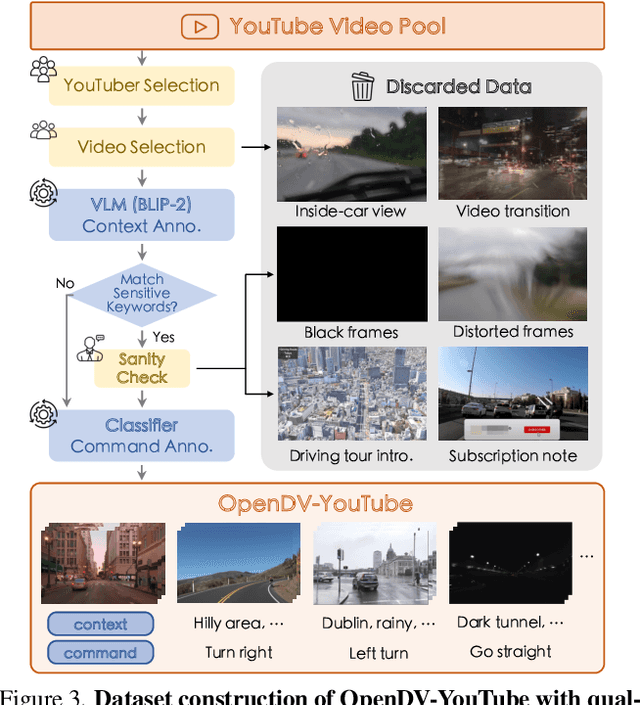

In this paper, we introduce the first large-scale video prediction model in the autonomous driving discipline. To eliminate the restriction of high-cost data collection and empower the generalization ability of our model, we acquire massive data from the web and pair it with diverse and high-quality text descriptions. The resultant dataset accumulates over 2000 hours of driving videos, spanning areas all over the world with diverse weather conditions and traffic scenarios. Inheriting the merits from recent latent diffusion models, our model, dubbed GenAD, handles the challenging dynamics in driving scenes with novel temporal reasoning blocks. We showcase that it can generalize to various unseen driving datasets in a zero-shot manner, surpassing general or driving-specific video prediction counterparts. Furthermore, GenAD can be adapted into an action-conditioned prediction model or a motion planner, holding great potential for real-world driving applications.
Generalized Relation Modeling for Transformer Tracking
Apr 21, 2023



Compared with previous two-stream trackers, the recent one-stream tracking pipeline, which allows earlier interaction between the template and search region, has achieved a remarkable performance gain. However, existing one-stream trackers always let the template interact with all parts inside the search region throughout all the encoder layers. This could potentially lead to target-background confusion when the extracted feature representations are not sufficiently discriminative. To alleviate this issue, we propose a generalized relation modeling method based on adaptive token division. The proposed method is a generalized formulation of attention-based relation modeling for Transformer tracking, which inherits the merits of both previous two-stream and one-stream pipelines whilst enabling more flexible relation modeling by selecting appropriate search tokens to interact with template tokens. An attention masking strategy and the Gumbel-Softmax technique are introduced to facilitate the parallel computation and end-to-end learning of the token division module. Extensive experiments show that our method is superior to the two-stream and one-stream pipelines and achieves state-of-the-art performance on six challenging benchmarks with a real-time running speed.
AiATrack: Attention in Attention for Transformer Visual Tracking
Jul 22, 2022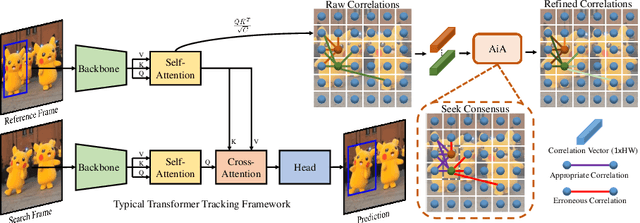
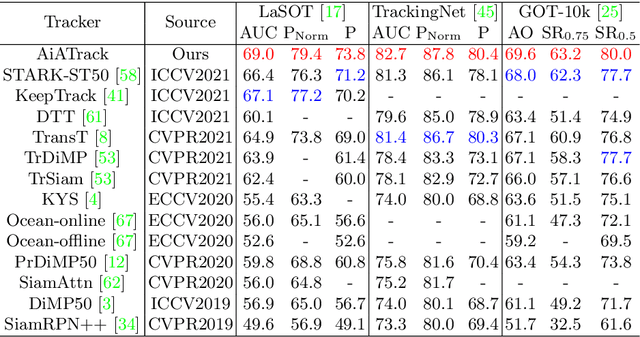
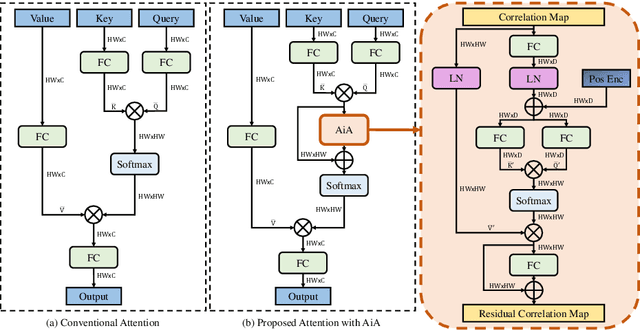
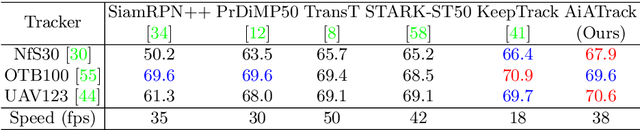
Transformer trackers have achieved impressive advancements recently, where the attention mechanism plays an important role. However, the independent correlation computation in the attention mechanism could result in noisy and ambiguous attention weights, which inhibits further performance improvement. To address this issue, we propose an attention in attention (AiA) module, which enhances appropriate correlations and suppresses erroneous ones by seeking consensus among all correlation vectors. Our AiA module can be readily applied to both self-attention blocks and cross-attention blocks to facilitate feature aggregation and information propagation for visual tracking. Moreover, we propose a streamlined Transformer tracking framework, dubbed AiATrack, by introducing efficient feature reuse and target-background embeddings to make full use of temporal references. Experiments show that our tracker achieves state-of-the-art performance on six tracking benchmarks while running at a real-time speed.