 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-R1: Chain-of-Tool-Thought for Ultra-Long Egocentric Video Reasoning
Jun 16, 2025We introduce Ego-R1, a novel framework for reasoning over ultra-long (i.e., in days and weeks) egocentric videos, which leverages a structured Chain-of-Tool-Thought (CoTT) process, orchestrated by an Ego-R1 Agent trained via reinforcement learning (RL). Inspired by human problem-solving strategies, CoTT decomposes complex reasoning into modular steps, with the RL agent invoking specific tools, one per step, to iteratively and collaboratively answer sub-questions tackling such tasks as temporal retrieval and multi-modal understanding. We design a two-stage training paradigm involving supervised finetuning (SFT) of a pretrained language model using CoTT data and RL to enable our agent to dynamically propose step-by-step tools for long-range reasoning. To facilitate training, we construct a dataset called Ego-R1 Data, which consists of Ego-CoTT-25K for SFT and Ego-QA-4.4K for RL. Furthermore, our Ego-R1 agent is evaluated on a newly curated week-long video QA benchmark, Ego-R1 Bench, which contains human-verified QA pairs from hybrid sources. Extensive results demonstrate that the dynamic, tool-augmented chain-of-thought reasoning by our Ego-R1 Agent can effectively tackle the unique challenges of understanding ultra-long egocentric videos, significantly extending the time coverage from few hours to a week.
GUI-Reflection: Empowering Multimodal GUI Models with Self-Reflection Behavior
Jun 09, 2025



Multimodal Large Language Models (MLLMs) have shown great potential in revolutionizing Graphical User Interface (GUI) automation. However, existing GUI models mostly rely on learning from nearly error-free offline trajectories, thus lacking reflection and error recovery capabilities. To bridge this gap, we propose GUI-Reflection, a novel framework that explicitly integrates self-reflection and error correction capabilities into end-to-end multimodal GUI models throughout dedicated training stages: GUI-specific pre-training, offline supervised fine-tuning (SFT), and online reflection tuning. GUI-reflection enables self-reflection behavior emergence with fully automated data generation and learning processes without requiring any human annotation. Specifically, 1) we first propose scalable data pipelines to automatically construct reflection and error correction data from existing successful trajectories. While existing GUI models mainly focus on grounding and UI understanding ability, we propose the GUI-Reflection Task Suite to learn and evaluate reflection-oriented abilities explicitly. 2) Furthermore, we built a diverse and efficient environment for online training and data collection of GUI models on mobile devices. 3) We also present an iterative online reflection tuning algorithm leveraging the proposed environment, enabling the model to continuously enhance its reflection and error correction abilities. Our framework equips GUI agents with self-reflection and correction capabilities, paving the way for more robust, adaptable, and intelligent GUI automation, with all data, models, environments, and tools to be released publicly.
Streamline Without Sacrifice -- Squeeze out Computation Redundancy in LMM
May 21, 2025Large multimodal models excel in multimodal tasks but face significant computational challenges due to excessive computation on visual tokens. Unlike token reduction methods that focus on token-level redundancy, we identify and study the computation-level redundancy on vision tokens to ensure no information loss. Our key insight is that vision tokens from the pretrained vision encoder do not necessarily require all the heavy operations (e.g., self-attention, FFNs) in decoder-only LMMs and could be processed more lightly with proper designs. We designed a series of experiments to discover and progressively squeeze out the vision-related computation redundancy. Based on our findings, we propose ProxyV, a novel approach that utilizes proxy vision tokens to alleviate the computational burden on original vision tokens. ProxyV enhances efficiency without compromising performance and can even yield notable performance gains in scenarios with more moderate efficiency improvements. Furthermore, the flexibility of ProxyV is demonstrated through its combination with token reduction methods to boost efficiency further. The code will be made public at this https://github.com/penghao-wu/ProxyV URL.
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Jan 23, 2025



Humans acquire knowledge through three cognitive stages: perceiving information, comprehending knowledge, and adapting knowledge to solve novel problems. Videos serve as an effective medium for this learning process, facilitating a progression through these cognitive stages. However, existing video benchmarks fail to systematically evaluate the knowledge acquisition capabilities in Large Multimodal Models (LMMs). To address this gap, we introduce Video-MMMU, a multi-modal, multi-disciplinary benchmark designed to assess LMMs' ability to acquire and utilize knowledge from videos. Video-MMMU features a curated collection of 300 expert-level videos and 900 human-annotated questions across six disciplines, evaluating knowledge acquisition through stage-aligned question-answer pairs: Perception, Comprehension, and Adaptation. A proposed knowledge gain metric, {\Delta}knowledge, quantifies improvement in performance after video viewing. Evaluation of LMMs reveals a steep decline in performance as cognitive demands increase and highlights a significant gap between human and model knowledge acquisition, underscoring the need for methods to enhance LMMs' capability to learn and adapt from videos.
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Jun 24, 2024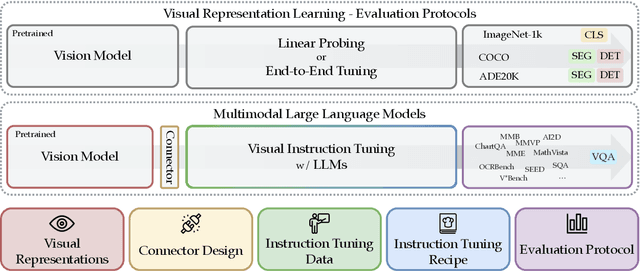


We introduce Cambrian-1, a family of multimodal LLMs (MLLMs) designed with a vision-centric approach. While stronger language models can enhance multimodal capabilities, the design choices for vision components are often insufficiently explored and disconnected from visual representation learning research. This gap hinders accurate sensory grounding in real-world scenarios. Our study uses LLMs and visual instruction tuning as an interface to evaluate various visual representations, offering new insights into different models and architectures -- self-supervised, strongly supervised, or combinations thereof -- based on experiments with over 20 vision encoders. We critically examine existing MLLM benchmarks, addressing the difficulties involved in consolidating and interpreting results from various tasks, and introduce a new vision-centric benchmark, CV-Bench. To further improve visual grounding, we propose the Spatial Vision Aggregator (SVA), a dynamic and spatially-aware connector that integrates high-resolution vision features with LLMs while reducing the number of tokens. Additionally, we discuss the curation of high-quality visual instruction-tuning data from publicly available sources, emphasizing the importance of data source balancing and distribution ratio. Collectively, Cambrian-1 not only achieves state-of-the-art performance but also serves as a comprehensive, open cookbook for instruction-tuned MLLMs. We provide model weights, code, supporting tools, datasets, and detailed instruction-tuning and evaluation recipes. We hope our release will inspire and accelerate advancements in multimodal systems and visual representation learning.
Generalized Predictive Model for Autonomous Driving
Mar 14, 2024

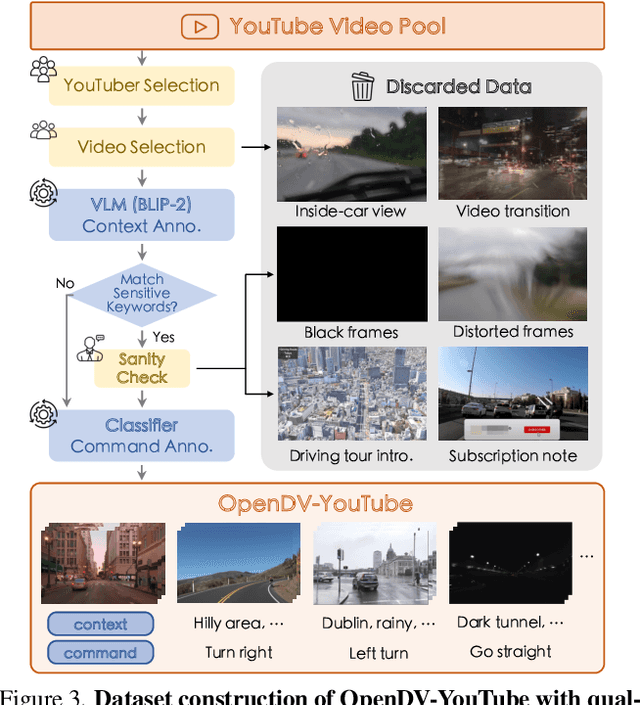

In this paper, we introduce the first large-scale video prediction model in the autonomous driving discipline. To eliminate the restriction of high-cost data collection and empower the generalization ability of our model, we acquire massive data from the web and pair it with diverse and high-quality text descriptions. The resultant dataset accumulates over 2000 hours of driving videos, spanning areas all over the world with diverse weather conditions and traffic scenarios. Inheriting the merits from recent latent diffusion models, our model, dubbed GenAD, handles the challenging dynamics in driving scenes with novel temporal reasoning blocks. We showcase that it can generalize to various unseen driving datasets in a zero-shot manner, surpassing general or driving-specific video prediction counterparts. Furthermore, GenAD can be adapted into an action-conditioned prediction model or a motion planner, holding great potential for real-world driving applications.
V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs
Dec 26, 2023



When we look around and perform complex tasks, how we see and selectively process what we see is crucial. However, the lack of this visual search mechanism in current multimodal LLMs (MLLMs) hinders their ability to focus on important visual details, especially when handling high-resolution and visually crowded images. To address this, we introduce V*, an LLM-guided visual search mechanism that employs the world knowledge in LLMs for efficient visual querying. When combined with an MLLM, this mechanism enhances collaborative reasoning, contextual understanding, and precise targeting of specific visual elements. This integration results in a new MLLM meta-architecture, named Show, sEArch, and TelL (SEAL). We further create V*Bench, a benchmark specifically designed to evaluate MLLMs in their ability to process high-resolution images and focus on visual details. Our study highlights the necessity of incorporating visual search capabilities into multimodal systems. The code is available https://github.com/penghao-wu/vstar.
End-to-end Autonomous Driving: Challenges and Frontiers
Jun 29, 2023



The autonomous driving community has witnessed a rapid growth in approaches that embrace an end-to-end algorithm framework, utilizing raw sensor input to generate vehicle motion plans, instead of concentrating on individual tasks such as detection and motion prediction. End-to-end systems, in comparison to modular pipelines, benefit from joint feature optimization for perception and planning. This field has flourished due to the availability of large-scale datasets, closed-loop evaluation, and the increasing need for autonomous driving algorithms to perform effectively in challenging scenarios. In this survey, we provide a comprehensive analysis of more than 250 papers, covering the motivation, roadmap, methodology, challenges, and future trends in end-to-end autonomous driving. We delve into several critical challenges, including multi-modality, interpretability, causal confusion, robustness, and world models, amongst others. Additionally, we discuss current advancements in foundation models and visual pre-training, as well as how to incorporate these techniques within the end-to-end driving framework. To facilitate future research, we maintain an active repository that contains up-to-date links to relevant literature and open-source projects at https://github.com/OpenDriveLab/End-to-end-Autonomous-Driving.
Think Twice before Driving: Towards Scalable Decoders for End-to-End Autonomous Driving
May 10, 2023End-to-end autonomous driving has made impressive progress in recent years. Existing methods usually adopt the decoupled encoder-decoder paradigm, where the encoder extracts hidden features from raw sensor data, and the decoder outputs the ego-vehicle's future trajectories or actions. Under such a paradigm, the encoder does not have access to the intended behavior of the ego agent, leaving the burden of finding out safety-critical regions from the massive receptive field and inferring about future situations to the decoder. Even worse, the decoder is usually composed of several simple multi-layer perceptrons (MLP) or GRUs while the encoder is delicately designed (e.g., a combination of heavy ResNets or Transformer). Such an imbalanced resource-task division hampers the learning process. In this work, we aim to alleviate the aforementioned problem by two principles: (1) fully utilizing the capacity of the encoder; (2) increasing the capacity of the decoder. Concretely, we first predict a coarse-grained future position and action based on the encoder features. Then, conditioned on the position and action, the future scene is imagined to check the ramification if we drive accordingly. We also retrieve the encoder features around the predicted coordinate to obtain fine-grained information about the safety-critical region. Finally, based on the predicted future and the retrieved salient feature, we refine the coarse-grained position and action by predicting its offset from ground-truth. The above refinement module could be stacked in a cascaded fashion, which extends the capacity of the decoder with spatial-temporal prior knowledge about the conditioned future. We conduct experiments on the CARLA simulator and achieve state-of-the-art performance in closed-loop benchmarks. Extensive ablation studies demonstrate the effectiveness of each proposed module.
Policy Pre-training for End-to-end Autonomous Driving via Self-supervised Geometric Modeling
Jan 03, 2023



Witnessing the impressive achievements of pre-training techniques on large-scale data in the field of computer vision and natural language processing, we wonder whether this idea could be adapted in a grab-and-go spirit, and mitigate the sample inefficiency problem for visuomotor driving. Given the highly dynamic and variant nature of the input, the visuomotor driving task inherently lacks view and translation invariance, and the visual input contains massive irrelevant information for decision making, resulting in predominant pre-training approaches from general vision less suitable for the autonomous driving task. To this end, we propose PPGeo (Policy Pre-training via Geometric modeling), an intuitive and straightforward fully self-supervised framework curated for the policy pretraining in visuomotor driving. We aim at learning policy representations as a powerful abstraction by modeling 3D geometric scenes on large-scale unlabeled and uncalibrated YouTube driving videos. The proposed PPGeo is performed in two stages to support effective self-supervised training. In the first stage, the geometric modeling framework generates pose and depth predictions simultaneously, with two consecutive frames as input. In the second stage, the visual encoder learns driving policy representation by predicting the future ego-motion and optimizing with the photometric error based on current visual observation only. As such, the pre-trained visual encoder is equipped with rich driving policy related representations and thereby competent for multiple visuomotor driving tasks. Extensive experiments covering a wide span of challenging scenarios have demonstrated the superiority of our proposed approach, where improvements range from 2% to even over 100% with very limited data. Code and models will be available at https://github.com/OpenDriveLab/PPGeo.