 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Jan 23, 2025



Humans acquire knowledge through three cognitive stages: perceiving information, comprehending knowledge, and adapting knowledge to solve novel problems. Videos serve as an effective medium for this learning process, facilitating a progression through these cognitive stages. However, existing video benchmarks fail to systematically evaluate the knowledge acquisition capabilities in Large Multimodal Models (LMMs). To address this gap, we introduce Video-MMMU, a multi-modal, multi-disciplinary benchmark designed to assess LMMs' ability to acquire and utilize knowledge from videos. Video-MMMU features a curated collection of 300 expert-level videos and 900 human-annotated questions across six disciplines, evaluating knowledge acquisition through stage-aligned question-answer pairs: Perception, Comprehension, and Adaptation. A proposed knowledge gain metric, {\Delta}knowledge, quantifies improvement in performance after video viewing. Evaluation of LMMs reveals a steep decline in performance as cognitive demands increase and highlights a significant gap between human and model knowledge acquisition, underscoring the need for methods to enhance LMMs' capability to learn and adapt from videos.
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Jul 17, 2024
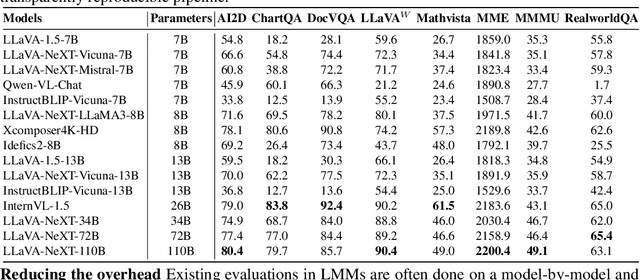
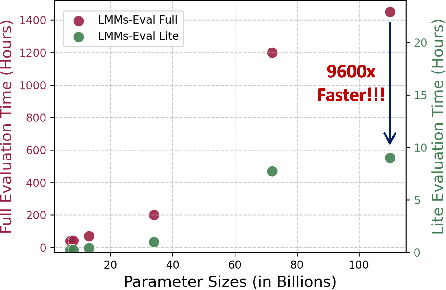
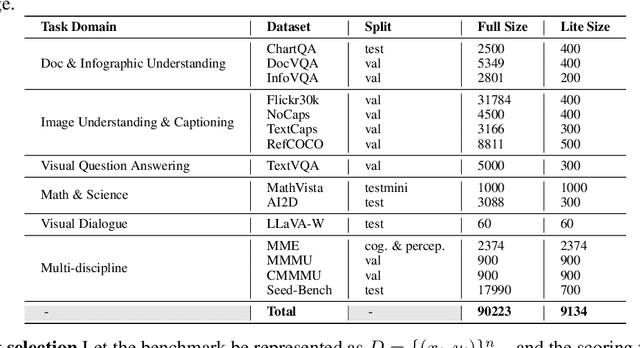
The advances of large foundation models necessitate wide-coverage, low-cost, and zero-contamination benchmarks. Despite continuous exploration of language model evaluations, comprehensive studies on the evaluation of Large Multi-modal Models (LMMs) remain limited. In this work, we introduce LMMS-EVAL, a unified and standardized multimodal benchmark framework with over 50 tasks and more than 10 models to promote transparent and reproducible evaluations. Although LMMS-EVAL offers comprehensive coverage, we find it still falls short in achieving low cost and zero contamination. To approach this evaluation trilemma, we further introduce LMMS-EVAL LITE, a pruned evaluation toolkit that emphasizes both coverage and efficiency. Additionally, we present Multimodal LIVEBENCH that utilizes continuously updating news and online forums to assess models' generalization abilities in the wild, featuring a low-cost and zero-contamination evaluation approach. In summary, our work highlights the importance of considering the evaluation trilemma and provides practical solutions to navigate the trade-offs in evaluating large multi-modal models, paving the way for more effective and reliable benchmarking of LMMs. We opensource our codebase and maintain leaderboard of LIVEBENCH at https://github.com/EvolvingLMMs-Lab/lmms-eval and https://huggingface.co/spaces/lmms-lab/LiveBench.
Ladder-of-Thought: Using Knowledge as Steps to Elevate Stance Detection
Sep 07, 2023Stance detection aims to identify the attitude expressed in a document towards a given target. Techniques such as Chain-of-Thought (CoT) prompting have advanced this task, enhancing a model's reasoning capabilities through the derivation of intermediate rationales. However, CoT relies primarily on a model's pre-trained internal knowledge during reasoning, thereby neglecting the valuable external information that is previously unknown to the model. This omission, especially within the unsupervised reasoning process, can affect the model's overall performance. Moreover, while CoT enhances Large Language Models (LLMs), smaller LMs, though efficient operationally, face challenges in delivering nuanced reasoning. In response to these identified gaps, we introduce the Ladder-of-Thought (LoT) for the stance detection task. Constructed through a dual-phase Progressive Optimization Framework, LoT directs the small LMs to assimilate high-quality external knowledge, refining the intermediate rationales produced. These bolstered rationales subsequently serve as the foundation for more precise predictions - akin to how a ladder facilitates reaching elevated goals. LoT achieves a balance between efficiency and performance. Our empirical evaluations underscore LoT's efficacy, marking a 16% improvement over GPT-3.5 and a 10% enhancement compared to GPT-3.5 with CoT on stance detection task.