 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoLucy: Deep Memory Backtracking for Long Video Understanding
Oct 14, 2025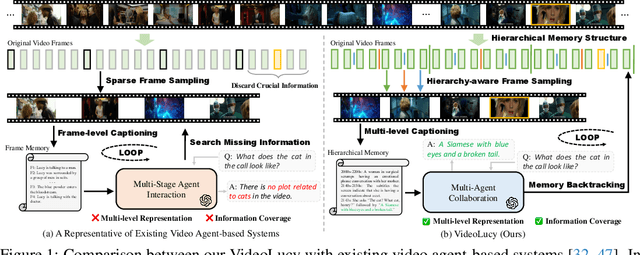
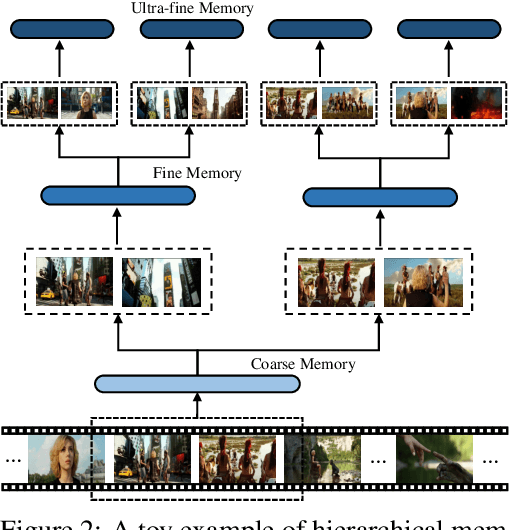

Recent studies have shown that agent-based systems leveraging large language models (LLMs) for key information retrieval and integration have emerged as a promising approach for long video understanding. However, these systems face two major challenges. First, they typically perform modeling and reasoning on individual frames, struggling to capture the temporal context of consecutive frames. Second, to reduce the cost of dense frame-level captioning, they adopt sparse frame sampling, which risks discarding crucial information. To overcome these limitations, we propose VideoLucy, a deep memory backtracking framework for long video understanding. Inspired by the human recollection process from coarse to fine, VideoLucy employs a hierarchical memory structure with progressive granularity. This structure explicitly defines the detail level and temporal scope of memory at different hierarchical depths. Through an agent-based iterative backtracking mechanism, VideoLucy systematically mines video-wide, question-relevant deep memories until sufficient information is gathered to provide a confident answer. This design enables effective temporal understanding of consecutive frames while preserving critical details. In addition, we introduce EgoMem, a new benchmark for long video understanding. EgoMem is designed to comprehensively evaluate a model's ability to understand complex events that unfold over time and capture fine-grained details in extremely long videos. Extensive experiments demonstrate the superiority of VideoLucy. Built on open-source models, VideoLucy significantly outperforms state-of-the-art methods on multiple long video understanding benchmarks, achieving performance even surpassing the latest proprietary models such as GPT-4o. Our code and dataset will be made publicly at https://videolucy.github.io
Ego-R1: Chain-of-Tool-Thought for Ultra-Long Egocentric Video Reasoning
Jun 16, 2025We introduce Ego-R1, a novel framework for reasoning over ultra-long (i.e., in days and weeks) egocentric videos, which leverages a structured Chain-of-Tool-Thought (CoTT) process, orchestrated by an Ego-R1 Agent trained via reinforcement learning (RL). Inspired by human problem-solving strategies, CoTT decomposes complex reasoning into modular steps, with the RL agent invoking specific tools, one per step, to iteratively and collaboratively answer sub-questions tackling such tasks as temporal retrieval and multi-modal understanding. We design a two-stage training paradigm involving supervised finetuning (SFT) of a pretrained language model using CoTT data and RL to enable our agent to dynamically propose step-by-step tools for long-range reasoning. To facilitate training, we construct a dataset called Ego-R1 Data, which consists of Ego-CoTT-25K for SFT and Ego-QA-4.4K for RL. Furthermore, our Ego-R1 agent is evaluated on a newly curated week-long video QA benchmark, Ego-R1 Bench, which contains human-verified QA pairs from hybrid sources. Extensive results demonstrate that the dynamic, tool-augmented chain-of-thought reasoning by our Ego-R1 Agent can effectively tackle the unique challenges of understanding ultra-long egocentric videos, significantly extending the time coverage from few hours to a week.
Learning 4D Panoptic Scene Graph Generation from Rich 2D Visual Scene
Mar 19, 2025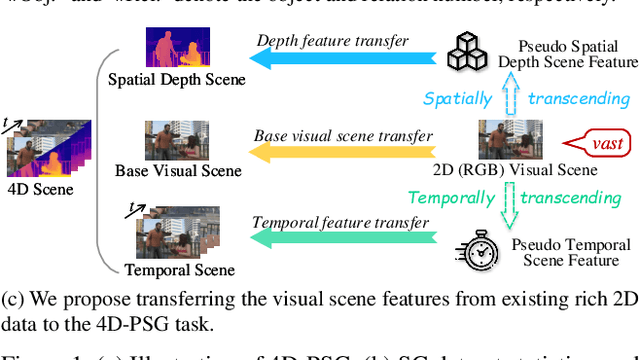

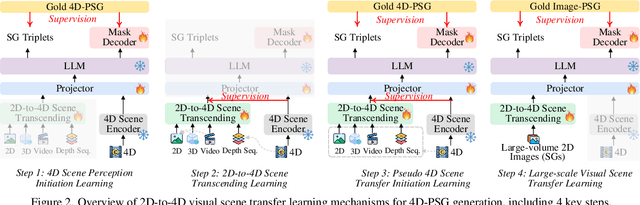

The latest emerged 4D Panoptic Scene Graph (4D-PSG) provides an advanced-ever representation for comprehensively modeling the dynamic 4D visual real world. Unfortunately, current pioneering 4D-PSG research can primarily suffer from data scarcity issues severely, as well as the resulting out-of-vocabulary problems; also, the pipeline nature of the benchmark generation method can lead to suboptimal performance. To address these challenges, this paper investigates a novel framework for 4D-PSG generation that leverages rich 2D visual scene annotations to enhance 4D scene learning. First, we introduce a 4D Large Language Model (4D-LLM) integrated with a 3D mask decoder for end-to-end generation of 4D-PSG. A chained SG inference mechanism is further designed to exploit LLMs' open-vocabulary capabilities to infer accurate and comprehensive object and relation labels iteratively. Most importantly, we propose a 2D-to-4D visual scene transfer learning framework, where a spatial-temporal scene transcending strategy effectively transfers dimension-invariant features from abundant 2D SG annotations to 4D scenes, effectively compensating for data scarcity in 4D-PSG. Extensive experiments on the benchmark data demonstrate that we strikingly outperform baseline models by a large margin, highlighting the effectiveness of our method.
EgoLife: Towards Egocentric Life Assistant
Mar 05, 2025We introduce EgoLife, a project to develop an egocentric life assistant that accompanies and enhances personal efficiency through AI-powered wearable glasses. To lay the foundation for this assistant, we conducted a comprehensive data collection study where six participants lived together for one week, continuously recording their daily activities - including discussions, shopping, cooking, socializing, and entertainment - using AI glasses for multimodal egocentric video capture, along with synchronized third-person-view video references. This effort resulted in the EgoLife Dataset, a comprehensive 300-hour egocentric, interpersonal, multiview, and multimodal daily life dataset with intensive annotation. Leveraging this dataset, we introduce EgoLifeQA, a suite of long-context, life-oriented question-answering tasks designed to provide meaningful assistance in daily life by addressing practical questions such as recalling past relevant events, monitoring health habits, and offering personalized recommendations. To address the key technical challenges of (1) developing robust visual-audio models for egocentric data, (2) enabling identity recognition, and (3) facilitating long-context question answering over extensive temporal information, we introduce EgoButler, an integrated system comprising EgoGPT and EgoRAG. EgoGPT is an omni-modal model trained on egocentric datasets, achieving state-of-the-art performance on egocentric video understanding. EgoRAG is a retrieval-based component that supports answering ultra-long-context questions. Our experimental studies verify their working mechanisms and reveal critical factors and bottlenecks, guiding future improvements. By releasing our datasets, models, and benchmarks, we aim to stimulate further research in egocentric AI assistants.
Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models
Nov 21, 2024



Large Language Models (LLMs) demonstrate enhanced capabilities and reliability by reasoning more, evolving from Chain-of-Thought prompting to product-level solutions like OpenAI o1. Despite various efforts to improve LLM reasoning, high-quality long-chain reasoning data and optimized training pipelines still remain inadequately explored in vision-language tasks. In this paper, we present Insight-V, an early effort to 1) scalably produce long and robust reasoning data for complex multi-modal tasks, and 2) an effective training pipeline to enhance the reasoning capabilities of multi-modal large language models (MLLMs). Specifically, to create long and structured reasoning data without human labor, we design a two-step pipeline with a progressive strategy to generate sufficiently long and diverse reasoning paths and a multi-granularity assessment method to ensure data quality. We observe that directly supervising MLLMs with such long and complex reasoning data will not yield ideal reasoning ability. To tackle this problem, we design a multi-agent system consisting of a reasoning agent dedicated to performing long-chain reasoning and a summary agent trained to judge and summarize reasoning results. We further incorporate an iterative DPO algorithm to enhance the reasoning agent's generation stability and quality. Based on the popular LLaVA-NeXT model and our stronger base MLLM, we demonstrate significant performance gains across challenging multi-modal benchmarks requiring visual reasoning. Benefiting from our multi-agent system, Insight-V can also easily maintain or improve performance on perception-focused multi-modal tasks.
Generalized Out-of-Distribution Detection and Beyond in Vision Language Model Era: A Survey
Jul 31, 2024



Detecting out-of-distribution (OOD) samples is crucial for ensuring the safety of machine learning systems and has shaped the field of OOD detection. Meanwhile, several other problems are closely related to OOD detection, including anomaly detection (AD), novelty detection (ND), open set recognition (OSR), and outlier detection (OD). To unify these problems, a generalized OOD detection framework was proposed, taxonomically categorizing these five problems. However, Vision Language Models (VLMs) such as CLIP have significantly changed the paradigm and blurred the boundaries between these fields, again confusing researchers. In this survey, we first present a generalized OOD detection v2, encapsulating the evolution of AD, ND, OSR, OOD detection, and OD in the VLM era. Our framework reveals that, with some field inactivity and integration, the demanding challenges have become OOD detection and AD. In addition, we also highlight the significant shift in the definition, problem settings, and benchmarks; we thus feature a comprehensive review of the methodology for OOD detection, including the discussion over other related tasks to clarify their relationship to OOD detection. Finally, we explore the advancements in the emerging Large Vision Language Model (LVLM) era, such as GPT-4V. We conclude this survey with open challenges and future directions.
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Jul 17, 2024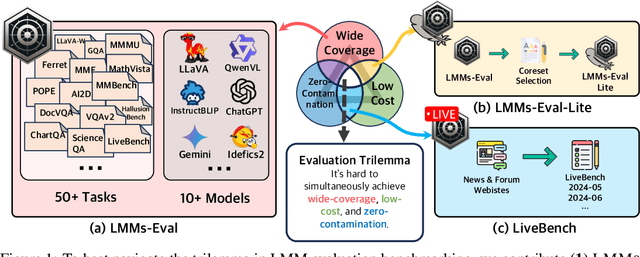
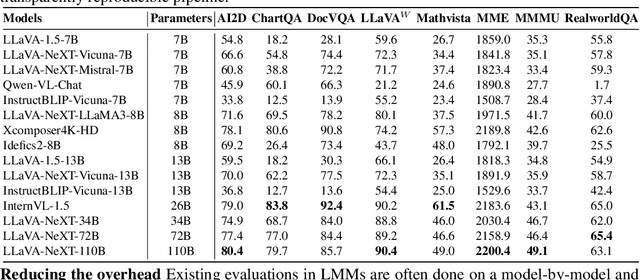
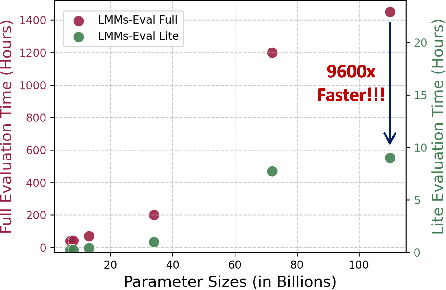
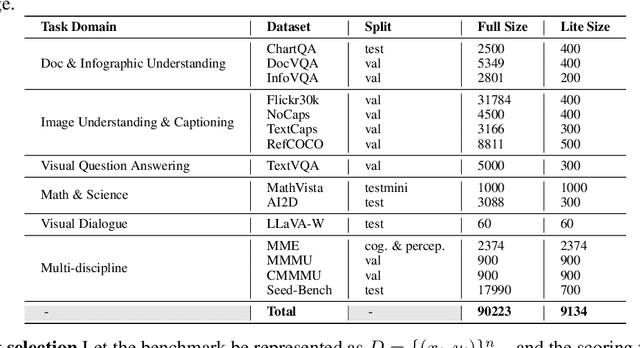
The advances of large foundation models necessitate wide-coverage, low-cost, and zero-contamination benchmarks. Despite continuous exploration of language model evaluations, comprehensive studies on the evaluation of Large Multi-modal Models (LMMs) remain limited. In this work, we introduce LMMS-EVAL, a unified and standardized multimodal benchmark framework with over 50 tasks and more than 10 models to promote transparent and reproducible evaluations. Although LMMS-EVAL offers comprehensive coverage, we find it still falls short in achieving low cost and zero contamination. To approach this evaluation trilemma, we further introduce LMMS-EVAL LITE, a pruned evaluation toolkit that emphasizes both coverage and efficiency. Additionally, we present Multimodal LIVEBENCH that utilizes continuously updating news and online forums to assess models' generalization abilities in the wild, featuring a low-cost and zero-contamination evaluation approach. In summary, our work highlights the importance of considering the evaluation trilemma and provides practical solutions to navigate the trade-offs in evaluating large multi-modal models, paving the way for more effective and reliable benchmarking of LMMs. We opensource our codebase and maintain leaderboard of LIVEBENCH at https://github.com/EvolvingLMMs-Lab/lmms-eval and https://huggingface.co/spaces/lmms-lab/LiveBench.
Long Context Transfer from Language to Vision
Jun 24, 2024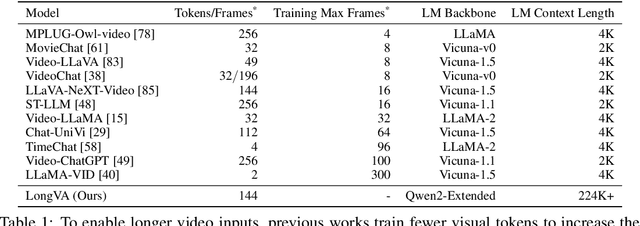
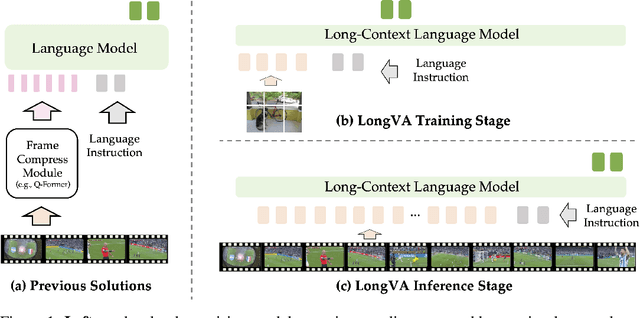


Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
4D Panoptic Scene Graph Generation
May 16, 2024


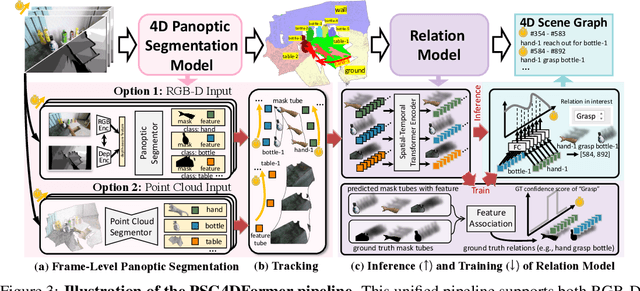
We are living in a three-dimensional space while moving forward through a fourth dimension: time. To allow artificial intelligence to develop a comprehensive understanding of such a 4D environment, we introduce 4D Panoptic Scene Graph (PSG-4D), a new representation that bridges the raw visual data perceived in a dynamic 4D world and high-level visual understanding. Specifically, PSG-4D abstracts rich 4D sensory data into nodes, which represent entities with precise location and status information, and edges, which capture the temporal relations. To facilitate research in this new area, we build a richly annotated PSG-4D dataset consisting of 3K RGB-D videos with a total of 1M frames, each of which is labeled with 4D panoptic segmentation masks as well as fine-grained, dynamic scene graphs. To solve PSG-4D, we propose PSG4DFormer, a Transformer-based model that can predict panoptic segmentation masks, track masks along the time axis, and generate the corresponding scene graphs via a relation component. Extensive experiments on the new dataset show that our method can serve as a strong baseline for future research on PSG-4D. In the end, we provide a real-world application example to demonstrate how we can achieve dynamic scene understanding by integrating a large language model into our PSG-4D system.
WorldQA: Multimodal World Knowledge in Videos through Long-Chain Reasoning
May 06, 2024



Multimodal information, together with our knowledge, help us to understand the complex and dynamic world. Large language models (LLM) and large multimodal models (LMM), however, still struggle to emulate this capability. In this paper, we present WorldQA, a video understanding dataset designed to push the boundaries of multimodal world models with three appealing properties: (1) Multimodal Inputs: The dataset comprises 1007 question-answer pairs and 303 videos, necessitating the analysis of both auditory and visual data for successful interpretation. (2) World Knowledge: We identify five essential types of world knowledge for question formulation. This approach challenges models to extend their capabilities beyond mere perception. (3) Long-Chain Reasoning: Our dataset introduces an average reasoning step of 4.45, notably surpassing other videoQA datasets. Furthermore, we introduce WorldRetriever, an agent designed to synthesize expert knowledge into a coherent reasoning chain, thereby facilitating accurate responses to WorldQA queries. Extensive evaluations of 13 prominent LLMs and LMMs reveal that WorldRetriever, although being the most effective model, achieved only 70% of humanlevel performance in multiple-choice questions. This finding highlights the necessity for further advancement in the reasoning and comprehension abilities of models. Our experiments also yield several key insights. For instance, while humans tend to perform better with increased frames, current LMMs, including WorldRetriever, show diminished performance under similar conditions. We hope that WorldQA,our methodology, and these insights could contribute to the future development of multimodal world models.