 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Multi-agent Pathfinding
May 14, 2025The task of the multi-agent pathfinding (MAPF) problem is to navigate a team of agents from their start point to the goal points. However, this setup is unsuitable in the assembly line scenario, which is periodic with a long working hour. To address this issue, the study formalizes the streaming MAPF (S-MAPF) problem, which assumes that the agents in the same agent stream have a periodic start time and share the same action sequence. The proposed solution, Agent Stream Conflict-Based Search (ASCBS), is designed to tackle this problem by incorporating a cyclic vertex/edge constraint to handle conflicts. Additionally, this work explores the potential usage of the disjoint splitting strategy within ASCBS. Experimental results indicate that ASCBS surpasses traditional MAPF solvers in terms of runtime for scenarios with prolonged working hours.
GVPO: Group Variance Policy Optimization for Large Language Model Post-Training
Apr 28, 2025Post-training plays a crucial role in refining and aligning large language models to meet specific tasks and human preferences. While recent advancements in post-training techniques, such as Group Relative Policy Optimization (GRPO), leverage increased sampling with relative reward scoring to achieve superior performance, these methods often suffer from training instability that limits their practical adoption. To address this challenge, we present Group Variance Policy Optimization (GVPO). GVPO incorporates the analytical solution to KL-constrained reward maximization directly into its gradient weights, ensuring alignment with the optimal policy. The method provides intuitive physical interpretations: its gradient mirrors the mean squared error between the central distance of implicit rewards and that of actual rewards. GVPO offers two key advantages: (1) it guarantees a unique optimal solution, exactly the KL-constrained reward maximization objective, (2) it supports flexible sampling distributions that avoids on-policy and importance sampling limitations. By unifying theoretical guarantees with practical adaptability, GVPO establishes a new paradigm for reliable and versatile LLM post-training.
Large Multi-modal Models Can Interpret Features in Large Multi-modal Models
Nov 22, 2024



Recent advances in Large Multimodal Models (LMMs) lead to significant breakthroughs in both academia and industry. One question that arises is how we, as humans, can understand their internal neural representations. This paper takes an initial step towards addressing this question by presenting a versatile framework to identify and interpret the semantics within LMMs. Specifically, 1) we first apply a Sparse Autoencoder(SAE) to disentangle the representations into human understandable features. 2) We then present an automatic interpretation framework to interpreted the open-semantic features learned in SAE by the LMMs themselves. We employ this framework to analyze the LLaVA-NeXT-8B model using the LLaVA-OV-72B model, demonstrating that these features can effectively steer the model's behavior. Our results contribute to a deeper understanding of why LMMs excel in specific tasks, including EQ tests, and illuminate the nature of their mistakes along with potential strategies for their rectification. These findings offer new insights into the internal mechanisms of LMMs and suggest parallels with the cognitive processes of the human brain.
MixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures
Oct 17, 2024



Perceiving and generating diverse modalities are crucial for AI models to effectively learn from and engage with real-world signals, necessitating reliable evaluations for their development. We identify two major issues in current evaluations: (1) inconsistent standards, shaped by different communities with varying protocols and maturity levels; and (2) significant query, grading, and generalization biases. To address these, we introduce MixEval-X, the first any-to-any real-world benchmark designed to optimize and standardize evaluations across input and output modalities. We propose multi-modal benchmark mixture and adaptation-rectification pipelines to reconstruct real-world task distributions, ensuring evaluations generalize effectively to real-world use cases. Extensive meta-evaluations show our approach effectively aligns benchmark samples with real-world task distributions and the model rankings correlate strongly with that of crowd-sourced real-world evaluations (up to 0.98). We provide comprehensive leaderboards to rerank existing models and organizations and offer insights to enhance understanding of multi-modal evaluations and inform future research.
LLaVA-OneVision: Easy Visual Task Transfer
Aug 06, 2024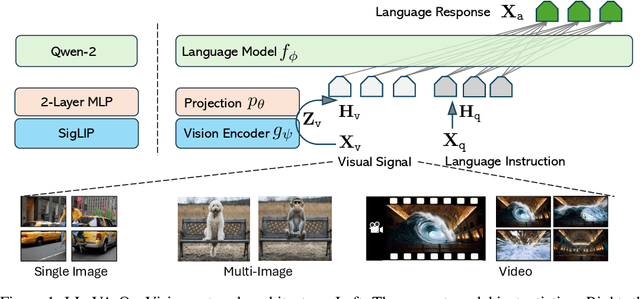



We present LLaVA-OneVision, a family of open large multimodal models (LMMs) developed by consolidating our insights into data, models, and visual representations in the LLaVA-NeXT blog series. Our experimental results demonstrate that LLaVA-OneVision is the first single model that can simultaneously push the performance boundaries of open LMMs in three important computer vision scenarios: single-image, multi-image, and video scenarios. Importantly, the design of LLaVA-OneVision allows strong transfer learning across different modalities/scenarios, yielding new emerging capabilities. In particular, strong video understanding and cross-scenario capabilities are demonstrated through task transfer from images to videos.
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Jul 17, 2024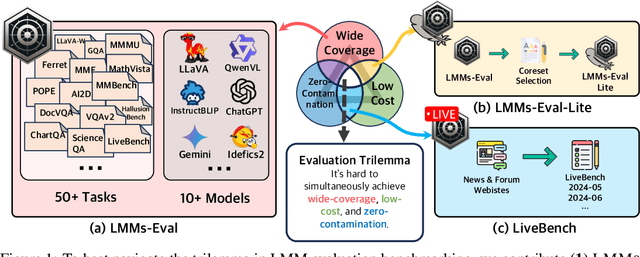
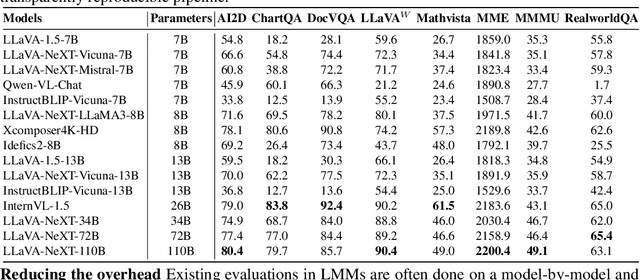
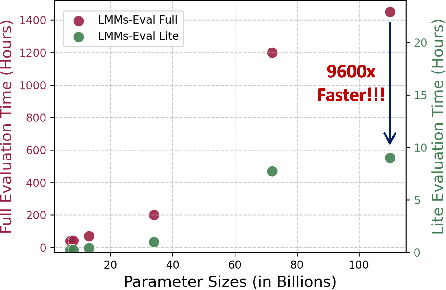
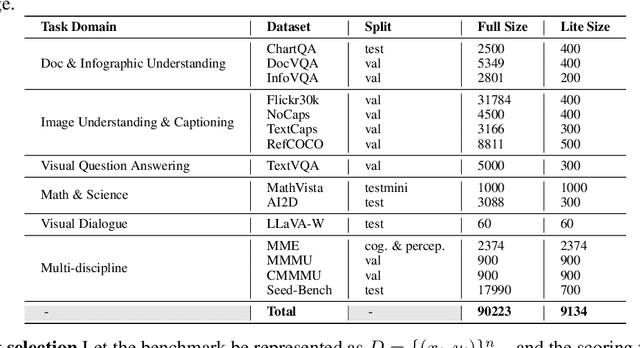
The advances of large foundation models necessitate wide-coverage, low-cost, and zero-contamination benchmarks. Despite continuous exploration of language model evaluations, comprehensive studies on the evaluation of Large Multi-modal Models (LMMs) remain limited. In this work, we introduce LMMS-EVAL, a unified and standardized multimodal benchmark framework with over 50 tasks and more than 10 models to promote transparent and reproducible evaluations. Although LMMS-EVAL offers comprehensive coverage, we find it still falls short in achieving low cost and zero contamination. To approach this evaluation trilemma, we further introduce LMMS-EVAL LITE, a pruned evaluation toolkit that emphasizes both coverage and efficiency. Additionally, we present Multimodal LIVEBENCH that utilizes continuously updating news and online forums to assess models' generalization abilities in the wild, featuring a low-cost and zero-contamination evaluation approach. In summary, our work highlights the importance of considering the evaluation trilemma and provides practical solutions to navigate the trade-offs in evaluating large multi-modal models, paving the way for more effective and reliable benchmarking of LMMs. We opensource our codebase and maintain leaderboard of LIVEBENCH at https://github.com/EvolvingLMMs-Lab/lmms-eval and https://huggingface.co/spaces/lmms-lab/LiveBench.
Long Context Transfer from Language to Vision
Jun 24, 2024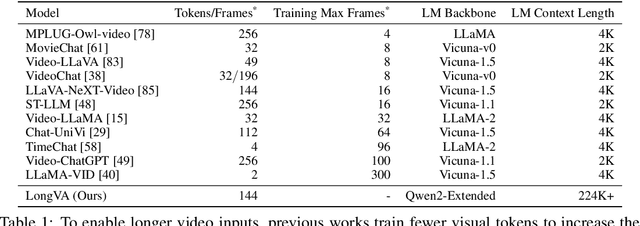
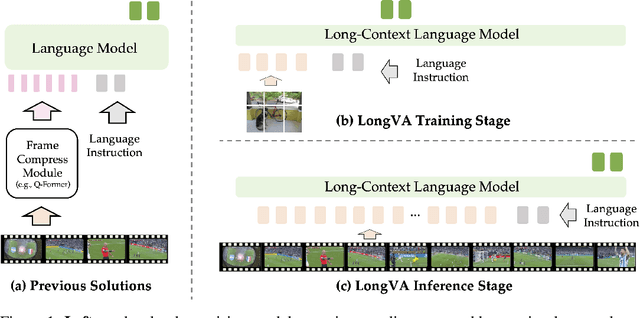


Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
WorldQA: Multimodal World Knowledge in Videos through Long-Chain Reasoning
May 06, 2024



Multimodal information, together with our knowledge, help us to understand the complex and dynamic world. Large language models (LLM) and large multimodal models (LMM), however, still struggle to emulate this capability. In this paper, we present WorldQA, a video understanding dataset designed to push the boundaries of multimodal world models with three appealing properties: (1) Multimodal Inputs: The dataset comprises 1007 question-answer pairs and 303 videos, necessitating the analysis of both auditory and visual data for successful interpretation. (2) World Knowledge: We identify five essential types of world knowledge for question formulation. This approach challenges models to extend their capabilities beyond mere perception. (3) Long-Chain Reasoning: Our dataset introduces an average reasoning step of 4.45, notably surpassing other videoQA datasets. Furthermore, we introduce WorldRetriever, an agent designed to synthesize expert knowledge into a coherent reasoning chain, thereby facilitating accurate responses to WorldQA queries. Extensive evaluations of 13 prominent LLMs and LMMs reveal that WorldRetriever, although being the most effective model, achieved only 70% of humanlevel performance in multiple-choice questions. This finding highlights the necessity for further advancement in the reasoning and comprehension abilities of models. Our experiments also yield several key insights. For instance, while humans tend to perform better with increased frames, current LMMs, including WorldRetriever, show diminished performance under similar conditions. We hope that WorldQA,our methodology, and these insights could contribute to the future development of multimodal world models.
The Impact of Generative Artificial Intelligence
Nov 13, 2023



The rise of generative artificial intelligence (AI) has sparked concerns about its potential influence on unemployment and market depression. This study addresses this concern by examining the impact of generative AI on product markets. To overcome the challenge of causal inference, given the inherent limitations of conducting controlled experiments, this paper identifies an unanticipated and sudden leak of a highly proficient image-generative AI as a novel instance of a "natural experiment". This AI leak spread rapidly, significantly reducing the cost of generating anime-style images compared to other styles, creating an opportunity for comparative assessment. We collect real-world data from an artwork outsourcing platform. Surprisingly, our results show that while generative AI lowers average prices, it substantially boosts order volume and overall revenue. This counterintuitive finding suggests that generative AI confers benefits upon artists rather than detriments. The study further offers theoretical economic explanations to elucidate this unexpected phenomenon. By furnishing empirical evidence, this paper dispels the notion that generative AI might engender depression, instead underscoring its potential to foster market prosperity. These findings carry significant implications for practitioners, policymakers, and the broader AI community.