 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
NLKI: A lightweight Natural Language Knowledge Integration Framework for Improving Small VLMs in Commonsense VQA Tasks
Aug 28, 2025Commonsense visual-question answering often hinges on knowledge that is missing from the image or the question. Small vision-language models (sVLMs) such as ViLT, VisualBERT and FLAVA therefore lag behind their larger generative counterparts. To study the effect of careful commonsense knowledge integration on sVLMs, we present an end-to-end framework (NLKI) that (i) retrieves natural language facts, (ii) prompts an LLM to craft natural language explanations, and (iii) feeds both signals to sVLMs respectively across two commonsense VQA datasets (CRIC, AOKVQA) and a visual-entailment dataset (e-SNLI-VE). Facts retrieved using a fine-tuned ColBERTv2 and an object information-enriched prompt yield explanations that largely cut down hallucinations, while lifting the end-to-end answer accuracy by up to 7% (across 3 datasets), making FLAVA and other models in NLKI match or exceed medium-sized VLMs such as Qwen-2 VL-2B and SmolVLM-2.5B. As these benchmarks contain 10-25% label noise, additional finetuning using noise-robust losses (such as symmetric cross entropy and generalised cross entropy) adds another 2.5% in CRIC, and 5.5% in AOKVQA. Our findings expose when LLM-based commonsense knowledge beats retrieval from commonsense knowledge bases, how noise-aware training stabilises small models in the context of external knowledge augmentation, and why parameter-efficient commonsense reasoning is now within reach for 250M models.
The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles
Feb 03, 2025![Figure 1 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F7-Table1-1.png&w=640&q=75)
![Figure 2 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F11-Table2-1.png&w=640&q=75)
![Figure 4 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F3-Figure3-1.png&w=640&q=75)
The releases of OpenAI's o1 and o3 mark a significant paradigm shift in Large Language Models towards advanced reasoning capabilities. Notably, o3 outperformed humans in novel problem-solving and skill acquisition on the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI). However, this benchmark is limited to symbolic patterns, whereas humans often perceive and reason about multimodal scenarios involving both vision and language data. Thus, there is an urgent need to investigate advanced reasoning capabilities in multimodal tasks. To this end, we track the evolution of the GPT-[n] and o-[n] series models on challenging multimodal puzzles, requiring fine-grained visual perception with abstract or algorithmic reasoning. The superior performance of o1 comes at nearly 750 times the computational cost of GPT-4o, raising concerns about its efficiency. Our results reveal a clear upward trend in reasoning capabilities across model iterations, with notable performance jumps across GPT-series models and subsequently to o1. Nonetheless, we observe that the o1 model still struggles with simple multimodal puzzles requiring abstract reasoning. Furthermore, its performance in algorithmic puzzles remains poor. We plan to continuously track new models in the series and update our results in this paper accordingly. All resources used in this evaluation are openly available https://github.com/declare-lab/LLM-PuzzleTest.
Emma-X: An Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning
Dec 17, 2024Traditional reinforcement learning-based robotic control methods are often task-specific and fail to generalize across diverse environments or unseen objects and instructions. Visual Language Models (VLMs) demonstrate strong scene understanding and planning capabilities but lack the ability to generate actionable policies tailored to specific robotic embodiments. To address this, Visual-Language-Action (VLA) models have emerged, yet they face challenges in long-horizon spatial reasoning and grounded task planning. In this work, we propose the Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning, Emma-X. Emma-X leverages our constructed hierarchical embodiment dataset based on BridgeV2, containing 60,000 robot manipulation trajectories auto-annotated with grounded task reasoning and spatial guidance. Additionally, we introduce a trajectory segmentation strategy based on gripper states and motion trajectories, which can help mitigate hallucination in grounding subtask reasoning generation. Experimental results demonstrate that Emma-X achieves superior performance over competitive baselines, particularly in real-world robotic tasks requiring spatial reasoning.
MixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures
Oct 17, 2024



Perceiving and generating diverse modalities are crucial for AI models to effectively learn from and engage with real-world signals, necessitating reliable evaluations for their development. We identify two major issues in current evaluations: (1) inconsistent standards, shaped by different communities with varying protocols and maturity levels; and (2) significant query, grading, and generalization biases. To address these, we introduce MixEval-X, the first any-to-any real-world benchmark designed to optimize and standardize evaluations across input and output modalities. We propose multi-modal benchmark mixture and adaptation-rectification pipelines to reconstruct real-world task distributions, ensuring evaluations generalize effectively to real-world use cases. Extensive meta-evaluations show our approach effectively aligns benchmark samples with real-world task distributions and the model rankings correlate strongly with that of crowd-sourced real-world evaluations (up to 0.98). We provide comprehensive leaderboards to rerank existing models and organizations and offer insights to enhance understanding of multi-modal evaluations and inform future research.
Not All Votes Count! Programs as Verifiers Improve Self-Consistency of Language Models for Math Reasoning
Oct 16, 2024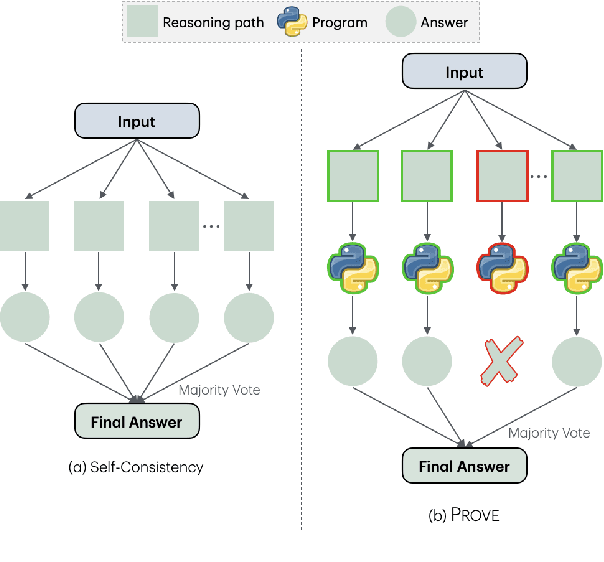
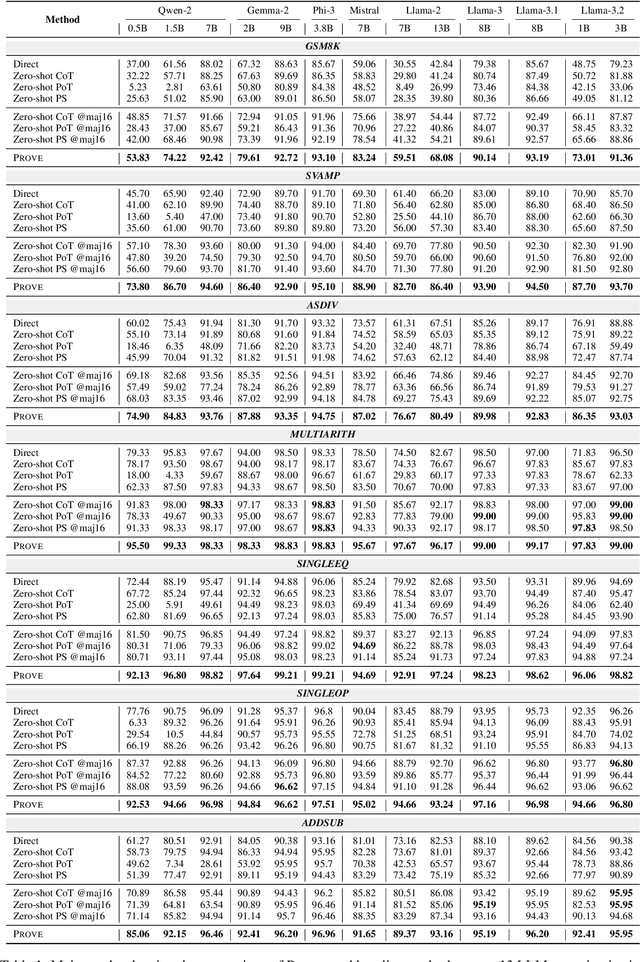
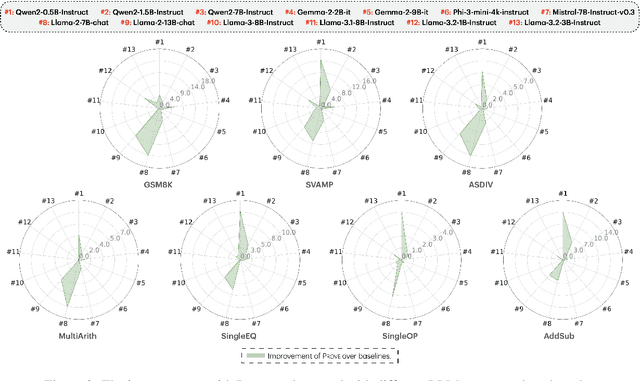
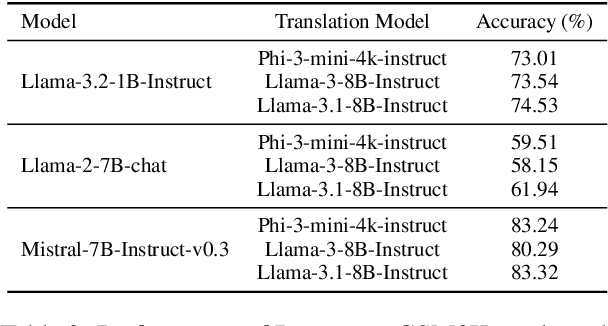
Large language models (LLMs) have shown increasing proficiency in solving mathematical reasoning problems. However, many current open-source LLMs often still make calculation and semantic understanding errors in their intermediate reasoning steps. In this work, we propose PROVE, a simple yet effective framework that uses program-based verification as a heuristic to filter out potentially incorrect reasoning paths before aggregating the final answers. Instead of relying on vanilla majority voting, our approach rejects solutions whose corresponding program outputs are inconsistent with the generated solution, aggregating only those validated by Python programs. We conducted extensive experiments on 13 open-source LLMs from various model families and sizes, ranging from 0.5B to 13B parameters, across seven math benchmarks. We demonstrate that PROVE consistently outperforms vanilla majority voting as a heuristic for solving mathematical reasoning tasks across all datasets and model sizes. Notably, PROVE increases accuracy on the GSM8K benchmark from 48.85% to 53.83% for Qwen2-0.5B-Instruct, from 65.66% to 73.01% for Llama-3.2-1B-Instruct, from 73.39% to 79.61% for Gemma-2-2b-it, and from 41.32% to 59.51% for Llama-2-7B-chat. Our codes are available at https://github.com/declare-lab/prove.
Improving Text-To-Audio Models with Synthetic Captions
Jun 18, 2024



It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged \textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an \textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named \texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new \textit{state-of-the-art}.
Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Apr 16, 2024



Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns
Mar 20, 2024
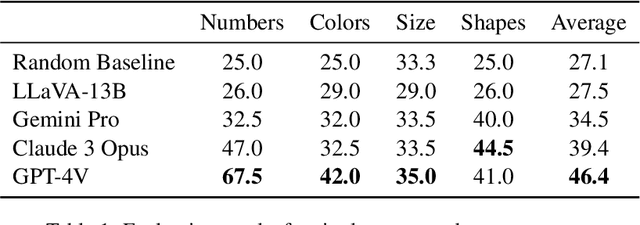
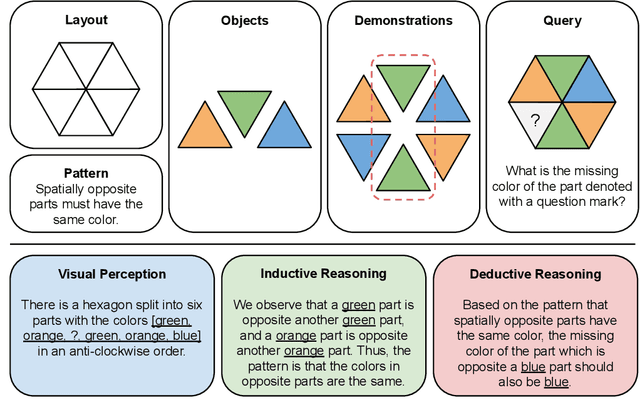
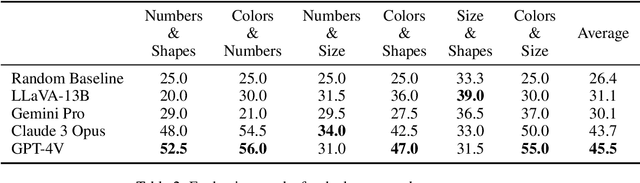
Large multimodal models extend the impressive capabilities of large language models by integrating multimodal understanding abilities. However, it is not clear how they can emulate the general intelligence and reasoning ability of humans. As recognizing patterns and abstracting concepts are key to general intelligence, we introduce PuzzleVQA, a collection of puzzles based on abstract patterns. With this dataset, we evaluate large multimodal models with abstract patterns based on fundamental concepts, including colors, numbers, sizes, and shapes. Through our experiments on state-of-the-art large multimodal models, we find that they are not able to generalize well to simple abstract patterns. Notably, even GPT-4V cannot solve more than half of the puzzles. To diagnose the reasoning challenges in large multimodal models, we progressively guide the models with our ground truth reasoning explanations for visual perception, inductive reasoning, and deductive reasoning. Our systematic analysis finds that the main bottlenecks of GPT-4V are weaker visual perception and inductive reasoning abilities. Through this work, we hope to shed light on the limitations of large multimodal models and how they can better emulate human cognitive processes in the future (Our data and code will be released publicly at https://github.com/declare-lab/LLM-PuzzleTest).
Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning
Mar 13, 2024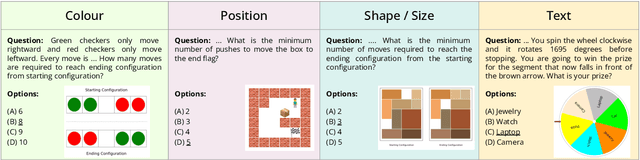
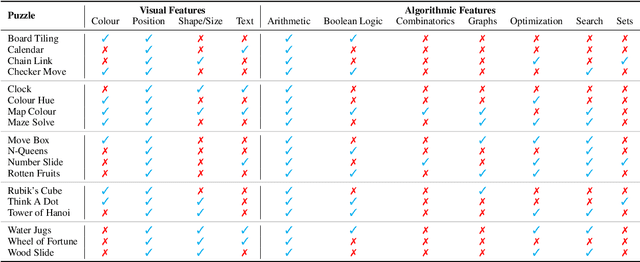
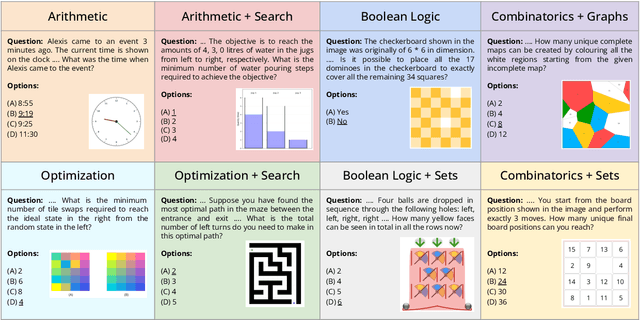
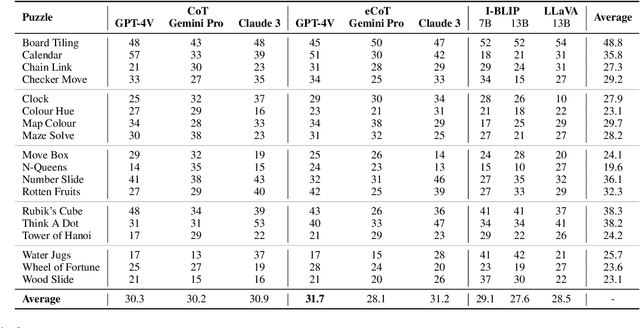
This paper introduces the novel task of multimodal puzzle solving, framed within the context of visual question-answering. We present a new dataset, AlgoPuzzleVQA designed to challenge and evaluate the capabilities of multimodal language models in solving algorithmic puzzles that necessitate both visual understanding, language understanding, and complex algorithmic reasoning. We create the puzzles to encompass a diverse array of mathematical and algorithmic topics such as boolean logic, combinatorics, graph theory, optimization, search, etc., aiming to evaluate the gap between visual data interpretation and algorithmic problem-solving skills. The dataset is generated automatically from code authored by humans. All our puzzles have exact solutions that can be found from the algorithm without tedious human calculations. It ensures that our dataset can be scaled up arbitrarily in terms of reasoning complexity and dataset size. Our investigation reveals that large language models (LLMs) such as GPT4V and Gemini exhibit limited performance in puzzle-solving tasks. We find that their performance is near random in a multi-choice question-answering setup for a significant number of puzzles. The findings emphasize the challenges of integrating visual, language, and algorithmic knowledge for solving complex reasoning problems.