 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
Apr 28, 2025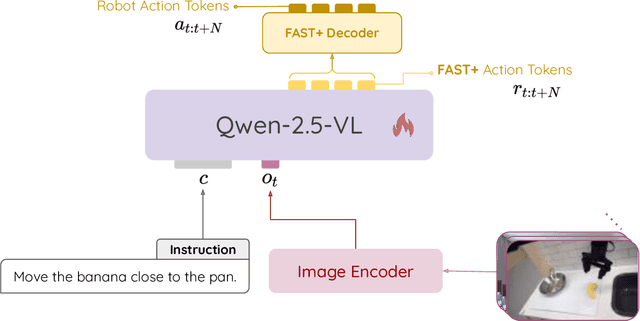
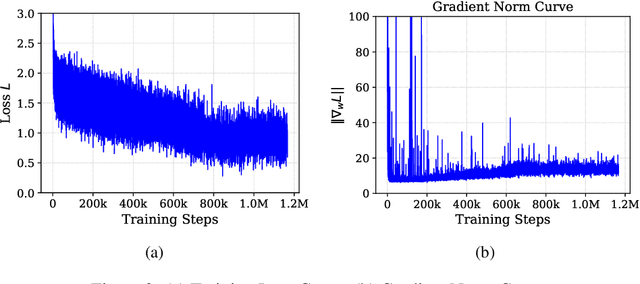


Existing Visual-Language-Action (VLA) models have shown promising performance in zero-shot scenarios, demonstrating impressive task execution and reasoning capabilities. However, a significant challenge arises from the limitations of visual encoding, which can result in failures during tasks such as object grasping. Moreover, these models typically suffer from high computational overhead due to their large sizes, often exceeding 7B parameters. While these models excel in reasoning and task planning, the substantial computational overhead they incur makes them impractical for real-time robotic environments, where speed and efficiency are paramount. To address the limitations of existing VLA models, we propose NORA, a 3B-parameter model designed to reduce computational overhead while maintaining strong task performance. NORA adopts the Qwen-2.5-VL-3B multimodal model as its backbone, leveraging its superior visual-semantic understanding to enhance visual reasoning and action grounding. Additionally, our \model{} is trained on 970k real-world robot demonstrations and equipped with the FAST+ tokenizer for efficient action sequence generation. Experimental results demonstrate that NORA outperforms existing large-scale VLA models, achieving better task performance with significantly reduced computational overhead, making it a more practical solution for real-time robotic autonomy.
Emma-X: An Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning
Dec 17, 2024Traditional reinforcement learning-based robotic control methods are often task-specific and fail to generalize across diverse environments or unseen objects and instructions. Visual Language Models (VLMs) demonstrate strong scene understanding and planning capabilities but lack the ability to generate actionable policies tailored to specific robotic embodiments. To address this, Visual-Language-Action (VLA) models have emerged, yet they face challenges in long-horizon spatial reasoning and grounded task planning. In this work, we propose the Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning, Emma-X. Emma-X leverages our constructed hierarchical embodiment dataset based on BridgeV2, containing 60,000 robot manipulation trajectories auto-annotated with grounded task reasoning and spatial guidance. Additionally, we introduce a trajectory segmentation strategy based on gripper states and motion trajectories, which can help mitigate hallucination in grounding subtask reasoning generation. Experimental results demonstrate that Emma-X achieves superior performance over competitive baselines, particularly in real-world robotic tasks requiring spatial reasoning.
Stuck in the Quicksand of Numeracy, Far from AGI Summit: Evaluating LLMs' Mathematical Competency through Ontology-guided Perturbations
Jan 17, 2024Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness, in mathematical reasoning tasks, remains an open question. In response, we develop (i) an ontology of perturbations of maths questions, (ii) a semi-automatic method of perturbation, and (iii) a dataset of perturbed maths questions to probe the limits of LLM capabilities in mathematical reasoning tasks. These controlled perturbations span across multiple fine dimensions of the structural and representational aspects of maths questions. Using GPT-4, we generated the MORE dataset by perturbing randomly selected five seed questions from GSM8K. This process was guided by our ontology and involved a thorough automatic and manual filtering process, yielding a set of 216 maths problems. We conducted comprehensive evaluation of both closed-source and open-source LLMs on MORE. The results show a significant performance drop across all the models against the perturbed questions. This strongly suggests that current LLMs lack robust mathematical skills and deep reasoning abilities. This research not only identifies multiple gaps in the capabilities of current models, but also highlights multiple potential directions for future development. Our dataset will be made publicly available at https://huggingface.co/datasets/declare-lab/GSM8k_MORE.
INSTRUCTEVAL: Towards Holistic Evaluation of Instruction-Tuned Large Language Models
Jun 15, 2023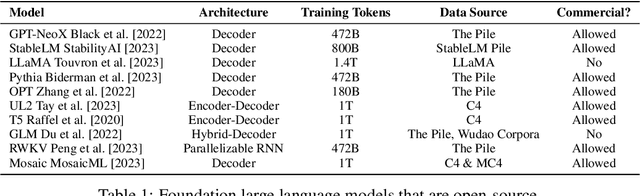
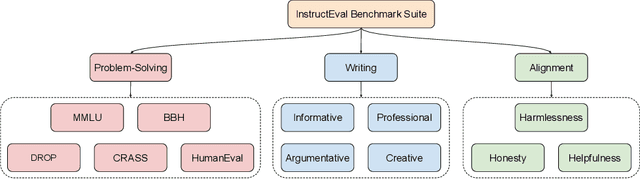
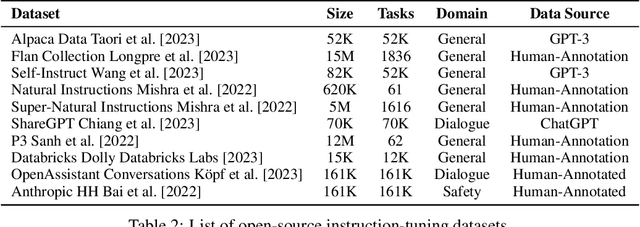
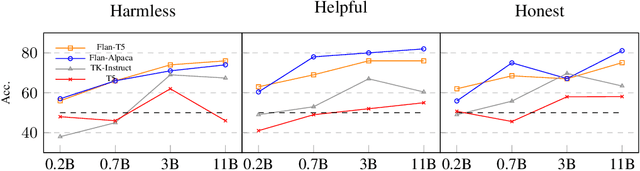
Instruction-tuned large language models have revolutionized natural language processing and have shown great potential in applications such as conversational agents. These models, such as GPT-4, can not only master language but also solve complex tasks in areas like mathematics, coding, medicine, and law. Despite their impressive capabilities, there is still a lack of comprehensive understanding regarding their full potential, primarily due to the black-box nature of many models and the absence of holistic evaluation studies. To address these challenges, we present INSTRUCTEVAL, a more comprehensive evaluation suite designed specifically for instruction-tuned large language models. Unlike previous works, our evaluation involves a rigorous assessment of models based on problem-solving, writing ability, and alignment to human values. We take a holistic approach to analyze various factors affecting model performance, including the pretraining foundation, instruction-tuning data, and training methods. Our findings reveal that the quality of instruction data is the most crucial factor in scaling model performance. While open-source models demonstrate impressive writing abilities, there is substantial room for improvement in problem-solving and alignment. We are encouraged by the rapid development of models by the open-source community, but we also highlight the need for rigorous evaluation to support claims made about these models. Through INSTRUCTEVAL, we aim to foster a deeper understanding of instruction-tuned models and advancements in their capabilities. INSTRUCTEVAL is publicly available at https://github.com/declare-lab/instruct-eval.
Uncertainty Guided Label Denoising for Document-level Distant Relation Extraction
May 26, 2023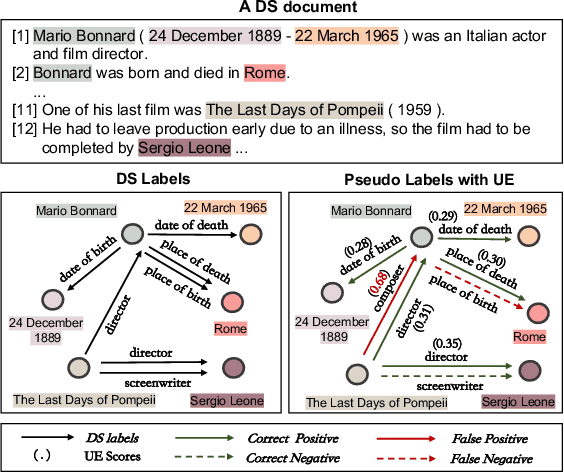
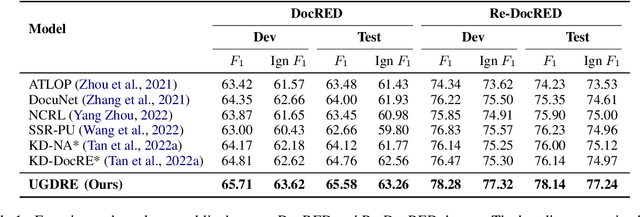
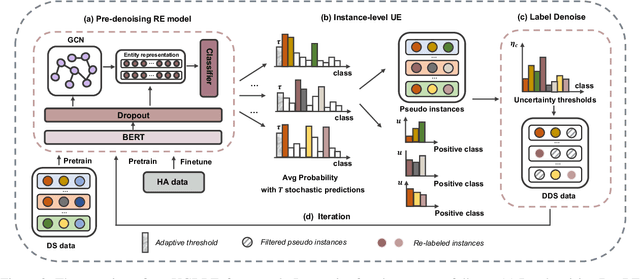
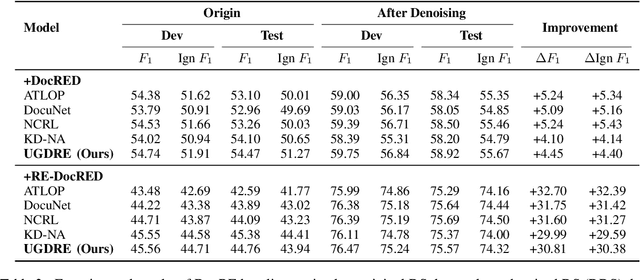
Document-level relation extraction (DocRE) aims to infer complex semantic relations among entities in a document. Distant supervision (DS) is able to generate massive auto-labeled data, which can improve DocRE performance. Recent works leverage pseudo labels generated by the pre-denoising model to reduce noise in DS data. However, unreliable pseudo labels bring new noise, e.g., adding false pseudo labels and losing correct DS labels. Therefore, how to select effective pseudo labels to denoise DS data is still a challenge in document-level distant relation extraction. To tackle this issue, we introduce uncertainty estimation technology to determine whether pseudo labels can be trusted. In this work, we propose a Document-level distant Relation Extraction framework with Uncertainty Guided label denoising, UGDRE. Specifically, we propose a novel instance-level uncertainty estimation method, which measures the reliability of the pseudo labels with overlapping relations. By further considering the long-tail problem, we design dynamic uncertainty thresholds for different types of relations to filter high-uncertainty pseudo labels. We conduct experiments on two public datasets. Our framework outperforms strong baselines by 1.91 F1 and 2.28 Ign F1 on the RE-DocRED dataset.
ReMask: A Robust Information-Masking Approach for Domain Counterfactual Generation
May 04, 2023



Domain shift is a big challenge in NLP, thus, many approaches resort to learning domain-invariant features to mitigate the inference phase domain shift. Such methods, however, fail to leverage the domain-specific nuances relevant to the task at hand. To avoid such drawbacks, domain counterfactual generation aims to transform a text from the source domain to a given target domain. However, due to the limited availability of data, such frequency-based methods often miss and lead to some valid and spurious domain-token associations. Hence, we employ a three-step domain obfuscation approach that involves frequency and attention norm-based masking, to mask domain-specific cues, and unmasking to regain the domain generic context. Our experiments empirically show that the counterfactual samples sourced from our masked text lead to improved domain transfer on 10 out of 12 domain sentiment classification settings, with an average of 2% accuracy improvement over the state-of-the-art for unsupervised domain adaptation (UDA). Further, our model outperforms the state-of-the-art by achieving 1.4% average accuracy improvement in the adversarial domain adaptation (ADA) setting. Moreover, our model also shows its domain adaptation efficacy on a large multi-domain intent classification dataset where it attains state-of-the-art results. We release the codes publicly at \url{https://github.com/declare-lab/remask}.
Few-shot Multimodal Sentiment Analysis based on Multimodal Probabilistic Fusion Prompts
Nov 12, 2022



Multimodal sentiment analysis is a trending topic with the explosion of multimodal content on the web. Present studies in multimodal sentiment analysis rely on large-scale supervised data. Collating supervised data is time-consuming and labor-intensive. As such, it is essential to investigate the problem of few-shot multimodal sentiment analysis. Previous works in few-shot models generally use language model prompts, which can improve performance in low-resource settings. However, the textual prompt ignores the information from other modalities. We propose Multimodal Probabilistic Fusion Prompts, which can provide diverse cues for multimodal sentiment detection. We first design a unified multimodal prompt to reduce the discrepancy in different modal prompts. To improve the robustness of our model, we then leverage multiple diverse prompts for each input and propose a probabilistic method to fuse the output predictions. Extensive experiments conducted on three datasets confirm the effectiveness of our approach.
CIDER: Commonsense Inference for Dialogue Explanation and Reasoning
Jun 01, 2021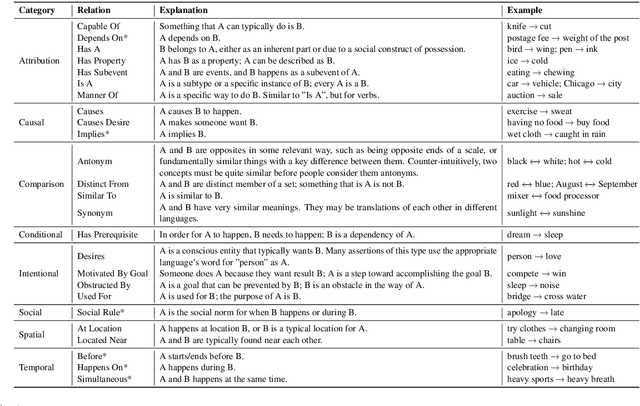

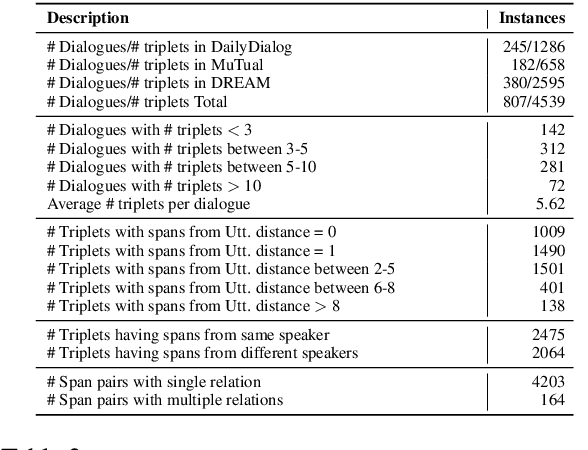

Commonsense inference to understand and explain human language is a fundamental research problem in natural language processing. Explaining human conversations poses a great challenge as it requires contextual understanding, planning, inference, and several aspects of reasoning including causal, temporal, and commonsense reasoning. In this work, we introduce CIDER -- a manually curated dataset that contains dyadic dialogue explanations in the form of implicit and explicit knowledge triplets inferred using contextual commonsense inference. Extracting such rich explanations from conversations can be conducive to improving several downstream applications. The annotated triplets are categorized by the type of commonsense knowledge present (e.g., causal, conditional, temporal). We set up three different tasks conditioned on the annotated dataset: Dialogue-level Natural Language Inference, Span Extraction, and Multi-choice Span Selection. Baseline results obtained with transformer-based models reveal that the tasks are difficult, paving the way for promising future research. The dataset and the baseline implementations are publicly available at https://github.com/declare-lab/CIDER.
MIME: MIMicking Emotions for Empathetic Response Generation
Oct 04, 2020

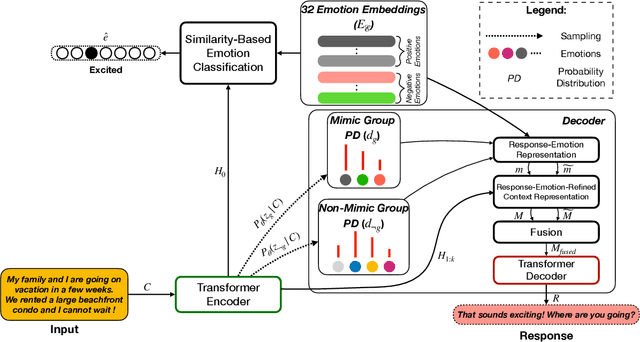
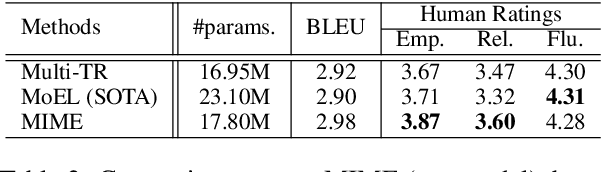
Current approaches to empathetic response generation view the set of emotions expressed in the input text as a flat structure, where all the emotions are treated uniformly. We argue that empathetic responses often mimic the emotion of the user to a varying degree, depending on its positivity or negativity and content. We show that the consideration of this polarity-based emotion clusters and emotional mimicry results in improved empathy and contextual relevance of the response as compared to the state-of-the-art. Also, we introduce stochasticity into the emotion mixture that yields emotionally more varied empathetic responses than the previous work. We demonstrate the importance of these factors to empathetic response generation using both automatic- and human-based evaluations. The implementation of MIME is publicly available at https://github.com/declare-lab/MIME.
Dialogue Relation Extraction with Document-level Heterogeneous Graph Attention Networks
Sep 14, 2020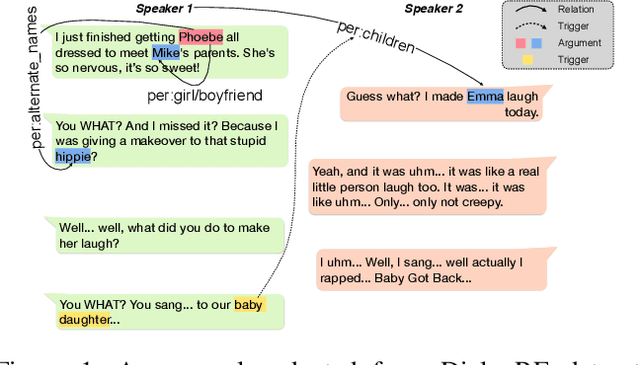
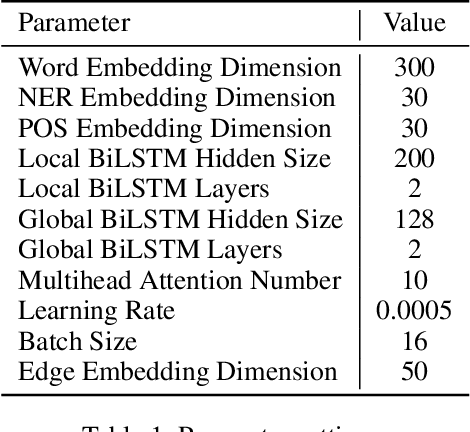
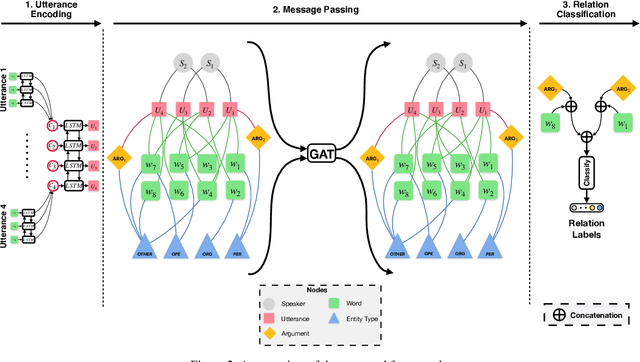
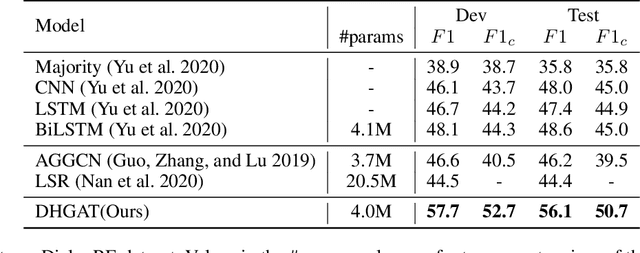
Dialogue relation extraction (DRE) aims to detect the relation between two entities mentioned in a multi-party dialogue. It plays an important role in constructing knowledge graphs from conversational data increasingly abundant on the internet and facilitating intelligent dialogue system development. The prior methods of DRE do not meaningfully leverage speaker information-they just prepend the utterances with the respective speaker names. Thus, they fail to model the crucial inter-speaker relations that may give additional context to relevant argument entities through pronouns and triggers. We, however, present a graph attention network-based method for DRE where a graph, that contains meaningfully connected speaker, entity, entity-type, and utterance nodes, is constructed. This graph is fed to a graph attention network for context propagation among relevant nodes, which effectively captures the dialogue context. We empirically show that this graph-based approach quite effectively captures the relations between different entity pairs in a dialogue as it outperforms the state-of-the-art approaches by a significant margin on the benchmark dataset DialogRE. Our code is released at: https://github.com/declare-lab/dialog-HGAT