 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from Training Grounded LLMs with Verifiable Rewards
Jun 18, 2025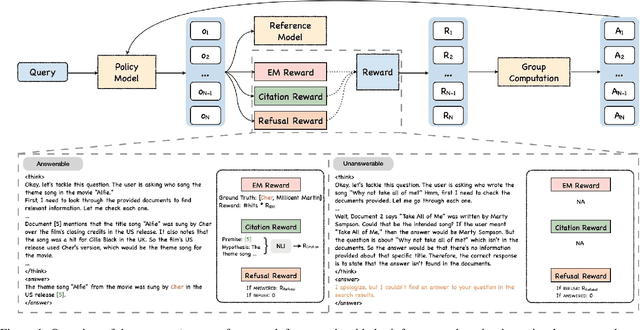
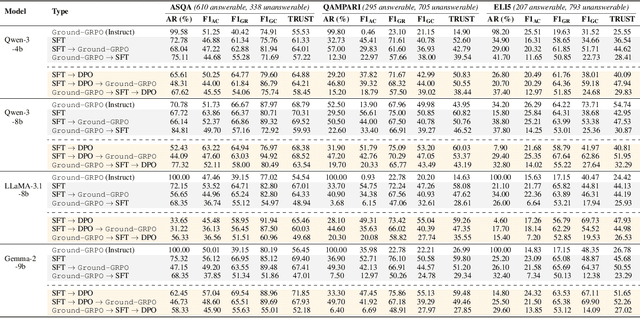
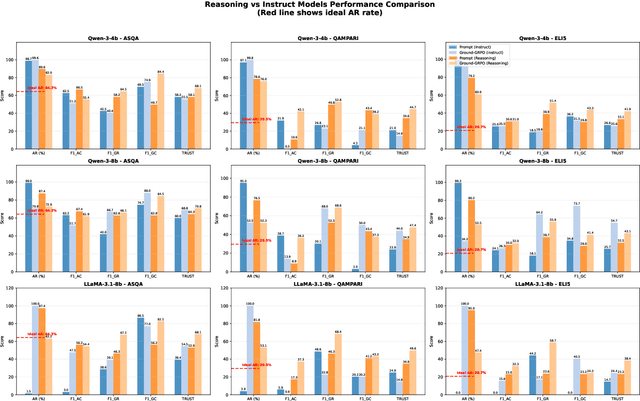
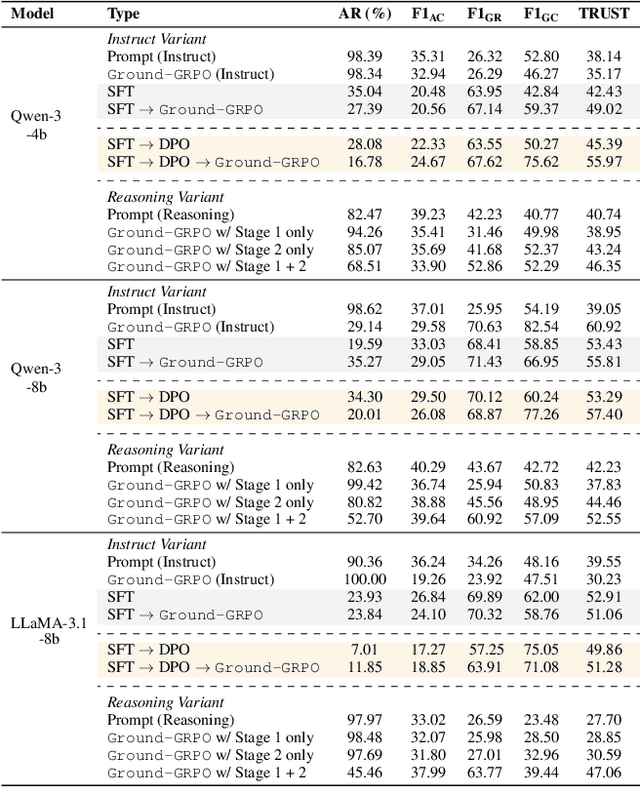
Generating grounded and trustworthy responses remains a key challenge for large language models (LLMs). While retrieval-augmented generation (RAG) with citation-based grounding holds promise, instruction-tuned models frequently fail even in straightforward scenarios: missing explicitly stated answers, citing incorrectly, or refusing when evidence is available. In this work, we explore how reinforcement learning (RL) and internal reasoning can enhance grounding in LLMs. We use the GRPO (Group Relative Policy Optimization) method to train models using verifiable outcome-based rewards targeting answer correctness, citation sufficiency, and refusal quality, without requiring gold reasoning traces or expensive annotations. Through comprehensive experiments across ASQA, QAMPARI, ELI5, and ExpertQA we show that reasoning-augmented models significantly outperform instruction-only variants, especially in handling unanswerable queries and generating well-cited responses. A two-stage training setup, first optimizing answer and citation behavior and then refusal, further improves grounding by stabilizing the learning signal. Additionally, we revisit instruction tuning via GPT-4 distillation and find that combining it with GRPO enhances performance on long-form, generative QA tasks. Overall, our findings highlight the value of reasoning, stage-wise optimization, and outcome-driven RL for building more verifiable and reliable LLMs.
Error Typing for Smarter Rewards: Improving Process Reward Models with Error-Aware Hierarchical Supervision
May 26, 2025Large Language Models (LLMs) are prone to hallucination, especially during multi-hop and reasoning-intensive tasks such as mathematical problem solving. While Outcome Reward Models verify only final answers, Process Reward Models (PRMs) score each intermediate step to steer generation toward coherent solutions. We introduce PathFinder-PRM, a novel hierarchical, error-aware discriminative PRM that first classifies math and consistency errors at each step, then combines these fine-grained signals to estimate step correctness. To train PathFinder-PRM, we construct a 400K-sample dataset by enriching the human-annotated PRM800K corpus and RLHFlow Mistral traces with three-dimensional step-level labels. On PRMBench, PathFinder-PRM achieves a new state-of-the-art PRMScore of 67.7, outperforming the prior best (65.5) while using 3 times less data. When applied to reward guided greedy search, our model yields prm@8 48.3, a +1.5 point gain over the strongest baseline. These results demonstrate that decoupled error detection and reward estimation not only boost fine-grained error detection but also substantially improve end-to-end, reward-guided mathematical reasoning with greater data efficiency.
PromptDistill: Query-based Selective Token Retention in Intermediate Layers for Efficient Large Language Model Inference
Mar 30, 2025
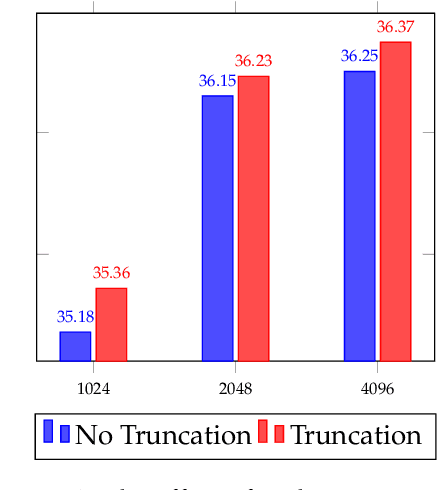
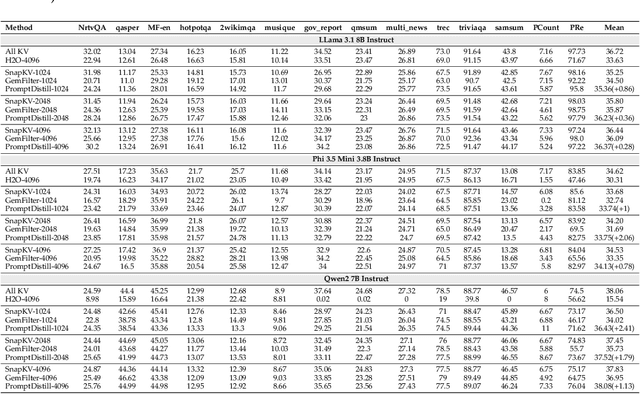
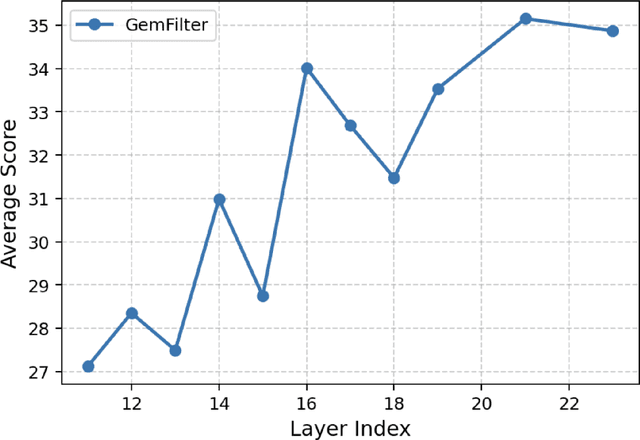
As large language models (LLMs) tackle increasingly complex tasks and longer documents, their computational and memory costs during inference become a major bottleneck. To address this, we propose PromptDistill, a novel, training-free method that improves inference efficiency while preserving generation quality. PromptDistill identifies and retains the most informative tokens by leveraging attention interactions in early layers, preserving their hidden states while reducing the computational burden in later layers. This allows the model to focus on essential contextual information without fully processing all tokens. Unlike previous methods such as H2O and SnapKV, which perform compression only after processing the entire input, or GemFilter, which selects a fixed portion of the initial prompt without considering contextual dependencies, PromptDistill dynamically allocates computational resources to the most relevant tokens while maintaining a global awareness of the input. Experiments using our method and baseline approaches with base models such as LLaMA 3.1 8B Instruct, Phi 3.5 Mini Instruct, and Qwen2 7B Instruct on benchmarks including LongBench, InfBench, and Needle in a Haystack demonstrate that PromptDistill significantly improves efficiency while having minimal impact on output quality compared to the original models. With a single-stage selection strategy, PromptDistill effectively balances performance and efficiency, outperforming prior methods like GemFilter, H2O, and SnapKV due to its superior ability to retain essential information. Specifically, compared to GemFilter, PromptDistill achieves an overall $1\%$ to $5\%$ performance improvement while also offering better time efficiency. Additionally, we explore multi-stage selection, which further improves efficiency while maintaining strong generation performance.
Emma-X: An Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning
Dec 17, 2024Traditional reinforcement learning-based robotic control methods are often task-specific and fail to generalize across diverse environments or unseen objects and instructions. Visual Language Models (VLMs) demonstrate strong scene understanding and planning capabilities but lack the ability to generate actionable policies tailored to specific robotic embodiments. To address this, Visual-Language-Action (VLA) models have emerged, yet they face challenges in long-horizon spatial reasoning and grounded task planning. In this work, we propose the Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning, Emma-X. Emma-X leverages our constructed hierarchical embodiment dataset based on BridgeV2, containing 60,000 robot manipulation trajectories auto-annotated with grounded task reasoning and spatial guidance. Additionally, we introduce a trajectory segmentation strategy based on gripper states and motion trajectories, which can help mitigate hallucination in grounding subtask reasoning generation. Experimental results demonstrate that Emma-X achieves superior performance over competitive baselines, particularly in real-world robotic tasks requiring spatial reasoning.
Ferret: Faster and Effective Automated Red Teaming with Reward-Based Scoring Technique
Aug 20, 2024



In today's era, where large language models (LLMs) are integrated into numerous real-world applications, ensuring their safety and robustness is crucial for responsible AI usage. Automated red-teaming methods play a key role in this process by generating adversarial attacks to identify and mitigate potential vulnerabilities in these models. However, existing methods often struggle with slow performance, limited categorical diversity, and high resource demands. While Rainbow Teaming, a recent approach, addresses the diversity challenge by framing adversarial prompt generation as a quality-diversity search, it remains slow and requires a large fine-tuned mutator for optimal performance. To overcome these limitations, we propose Ferret, a novel approach that builds upon Rainbow Teaming by generating multiple adversarial prompt mutations per iteration and using a scoring function to rank and select the most effective adversarial prompt. We explore various scoring functions, including reward models, Llama Guard, and LLM-as-a-judge, to rank adversarial mutations based on their potential harm to improve the efficiency of the search for harmful mutations. Our results demonstrate that Ferret, utilizing a reward model as a scoring function, improves the overall attack success rate (ASR) to 95%, which is 46% higher than Rainbow Teaming. Additionally, Ferret reduces the time needed to achieve a 90% ASR by 15.2% compared to the baseline and generates adversarial prompts that are transferable i.e. effective on other LLMs of larger size. Our codes are available at https://github.com/declare-lab/ferret.