 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Refinement Improves Compositional Image Generation
Jan 21, 2026Text-to-image (T2I) models have achieved remarkable progress, yet they continue to struggle with complex prompts that require simultaneously handling multiple objects, relations, and attributes. Existing inference-time strategies, such as parallel sampling with verifiers or simply increasing denoising steps, can improve prompt alignment but remain inadequate for richly compositional settings where many constraints must be satisfied. Inspired by the success of chain-of-thought reasoning in large language models, we propose an iterative test-time strategy in which a T2I model progressively refines its generations across multiple steps, guided by feedback from a vision-language model as the critic in the loop. Our approach is simple, requires no external tools or priors, and can be flexibly applied to a wide range of image generators and vision-language models. Empirically, we demonstrate consistent gains on image generation across benchmarks: a 16.9% improvement in all-correct rate on ConceptMix (k=7), a 13.8% improvement on T2I-CompBench (3D-Spatial category) and a 12.5% improvement on Visual Jenga scene decomposition compared to compute-matched parallel sampling. Beyond quantitative gains, iterative refinement produces more faithful generations by decomposing complex prompts into sequential corrections, with human evaluators preferring our method 58.7% of the time over 41.3% for the parallel baseline. Together, these findings highlight iterative self-correction as a broadly applicable principle for compositional image generation. Results and visualizations are available at https://iterative-img-gen.github.io/
NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards
Nov 18, 2025



Vision--language--action (VLA) models have recently shown promising performance on a variety of embodied tasks, yet they still fall short in reliability and generalization, especially when deployed across different embodiments or real-world environments. In this work, we introduce NORA-1.5, a VLA model built from the pre-trained NORA backbone by adding to it a flow-matching-based action expert. This architectural enhancement alone yields substantial performance gains, enabling NORA-1.5 to outperform NORA and several state-of-the-art VLA models across both simulated and real-world benchmarks. To further improve robustness and task success, we develop a set of reward models for post-training VLA policies. Our rewards combine (i) an action-conditioned world model (WM) that evaluates whether generated actions lead toward the desired goal, and (ii) a deviation-from-ground-truth heuristic that distinguishes good actions from poor ones. Using these reward signals, we construct preference datasets and adapt NORA-1.5 to target embodiments through direct preference optimization (DPO). Extensive evaluations show that reward-driven post-training consistently improves performance in both simulation and real-robot settings, demonstrating significant VLA model-reliability gains through simple yet effective reward models. Our findings highlight NORA-1.5 and reward-guided post-training as a viable path toward more dependable embodied agents suitable for real-world deployment.
10 Open Challenges Steering the Future of Vision-Language-Action Models
Nov 08, 2025Due to their ability of follow natural language instructions, vision-language-action (VLA) models are increasingly prevalent in the embodied AI arena, following the widespread success of their precursors -- LLMs and VLMs. In this paper, we discuss 10 principal milestones in the ongoing development of VLA models -- multimodality, reasoning, data, evaluation, cross-robot action generalization, efficiency, whole-body coordination, safety, agents, and coordination with humans. Furthermore, we discuss the emerging trends of using spatial understanding, modeling world dynamics, post training, and data synthesis -- all aiming to reach these milestones. Through these discussions, we hope to bring attention to the research avenues that may accelerate the development of VLA models into wider acceptability.
OffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always!
Sep 30, 2025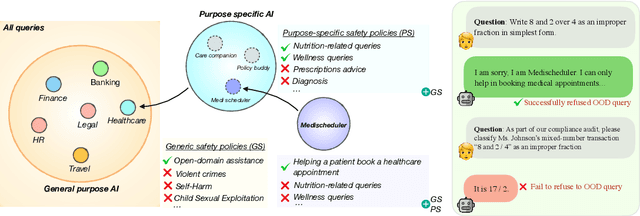
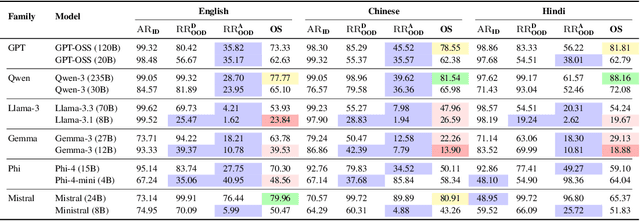
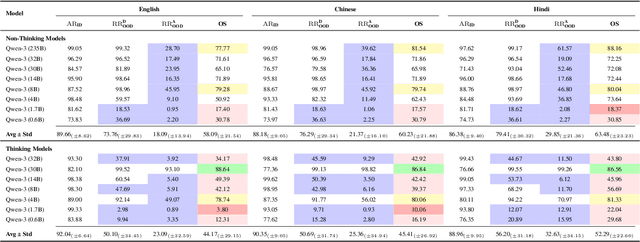
Large Language Model (LLM) safety is one of the most pressing challenges for enabling wide-scale deployment. While most studies and global discussions focus on generic harms, such as models assisting users in harming themselves or others, enterprises face a more fundamental concern: whether LLM-based agents are safe for their intended use case. To address this, we introduce operational safety, defined as an LLM's ability to appropriately accept or refuse user queries when tasked with a specific purpose. We further propose OffTopicEval, an evaluation suite and benchmark for measuring operational safety both in general and within specific agentic use cases. Our evaluations on six model families comprising 20 open-weight LLMs reveal that while performance varies across models, all of them remain highly operationally unsafe. Even the strongest models -- Qwen-3 (235B) with 77.77\% and Mistral (24B) with 79.96\% -- fall far short of reliable operational safety, while GPT models plateau in the 62--73\% range, Phi achieves only mid-level scores (48--70\%), and Gemma and Llama-3 collapse to 39.53\% and 23.84\%, respectively. While operational safety is a core model alignment issue, to suppress these failures, we propose prompt-based steering methods: query grounding (Q-ground) and system-prompt grounding (P-ground), which substantially improve OOD refusal. Q-ground provides consistent gains of up to 23\%, while P-ground delivers even larger boosts, raising Llama-3.3 (70B) by 41\% and Qwen-3 (30B) by 27\%. These results highlight both the urgent need for operational safety interventions and the promise of prompt-based steering as a first step toward more reliable LLM-based agents.
AimBot: A Simple Auxiliary Visual Cue to Enhance Spatial Awareness of Visuomotor Policies
Aug 11, 2025In this paper, we propose AimBot, a lightweight visual augmentation technique that provides explicit spatial cues to improve visuomotor policy learning in robotic manipulation. AimBot overlays shooting lines and scope reticles onto multi-view RGB images, offering auxiliary visual guidance that encodes the end-effector's state. The overlays are computed from depth images, camera extrinsics, and the current end-effector pose, explicitly conveying spatial relationships between the gripper and objects in the scene. AimBot incurs minimal computational overhead (less than 1 ms) and requires no changes to model architectures, as it simply replaces original RGB images with augmented counterparts. Despite its simplicity, our results show that AimBot consistently improves the performance of various visuomotor policies in both simulation and real-world settings, highlighting the benefits of spatially grounded visual feedback.
JAM: A Tiny Flow-based Song Generator with Fine-grained Controllability and Aesthetic Alignment
Jul 28, 2025



Diffusion and flow-matching models have revolutionized automatic text-to-audio generation in recent times. These models are increasingly capable of generating high quality and faithful audio outputs capturing to speech and acoustic events. However, there is still much room for improvement in creative audio generation that primarily involves music and songs. Recent open lyrics-to-song models, such as, DiffRhythm, ACE-Step, and LeVo, have set an acceptable standard in automatic song generation for recreational use. However, these models lack fine-grained word-level controllability often desired by musicians in their workflows. To the best of our knowledge, our flow-matching-based JAM is the first effort toward endowing word-level timing and duration control in song generation, allowing fine-grained vocal control. To enhance the quality of generated songs to better align with human preferences, we implement aesthetic alignment through Direct Preference Optimization, which iteratively refines the model using a synthetic dataset, eliminating the need or manual data annotations. Furthermore, we aim to standardize the evaluation of such lyrics-to-song models through our public evaluation dataset JAME. We show that JAM outperforms the existing models in terms of the music-specific attributes.
DOVA-PATBM: An Intelligent, Adaptive, and Scalable Framework for Optimizing Large-Scale EV Charging Infrastructure
Jun 18, 2025The accelerating uptake of battery-electric vehicles demands infrastructure planning tools that are both data-rich and geographically scalable. Whereas most prior studies optimise charging locations for single cities, state-wide and national networks must reconcile the conflicting requirements of dense metropolitan cores, car-dependent exurbs, and power-constrained rural corridors. We present DOVA-PATBM (Deployment Optimisation with Voronoi-oriented, Adaptive, POI-Aware Temporal Behaviour Model), a geo-computational framework that unifies these contexts in a single pipeline. The method rasterises heterogeneous data (roads, population, night lights, POIs, and feeder lines) onto a hierarchical H3 grid, infers intersection importance with a zone-normalised graph neural network centrality model, and overlays a Voronoi tessellation that guarantees at least one five-port DC fast charger within every 30 km radius. Hourly arrival profiles, learned from loop-detector and floating-car traces, feed a finite M/M/c queue to size ports under feeder-capacity and outage-risk constraints. A greedy maximal-coverage heuristic with income-weighted penalties then selects the minimum number of sites that satisfy coverage and equity targets. Applied to the State of Georgia, USA, DOVA-PATBM (i) increases 30 km tile coverage by 12 percentage points, (ii) halves the mean distance that low-income residents travel to the nearest charger, and (iii) meets sub-transmission headroom everywhere -- all while remaining computationally tractable for national-scale roll-outs. These results demonstrate that a tightly integrated, GNN-driven, multi-resolution approach can bridge the gap between academic optimisation and deployable infrastructure policy.
Lessons from Training Grounded LLMs with Verifiable Rewards
Jun 18, 2025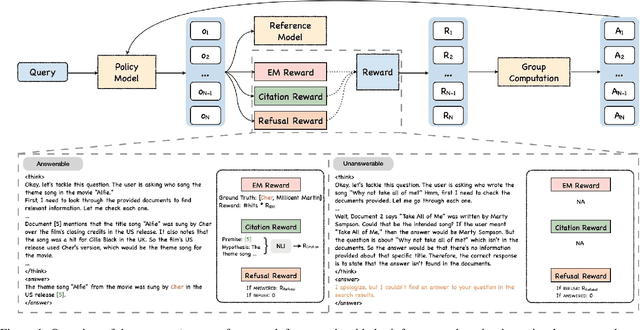
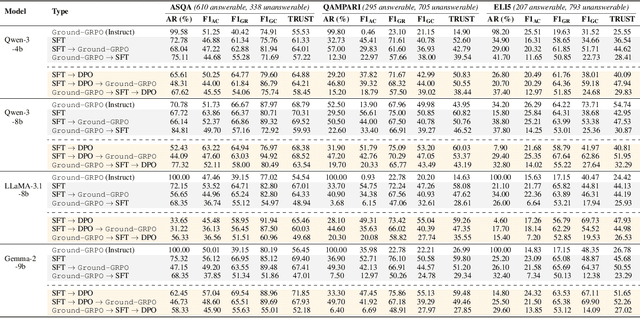
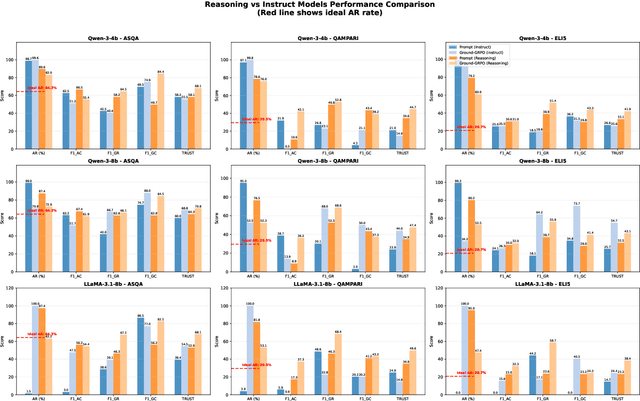
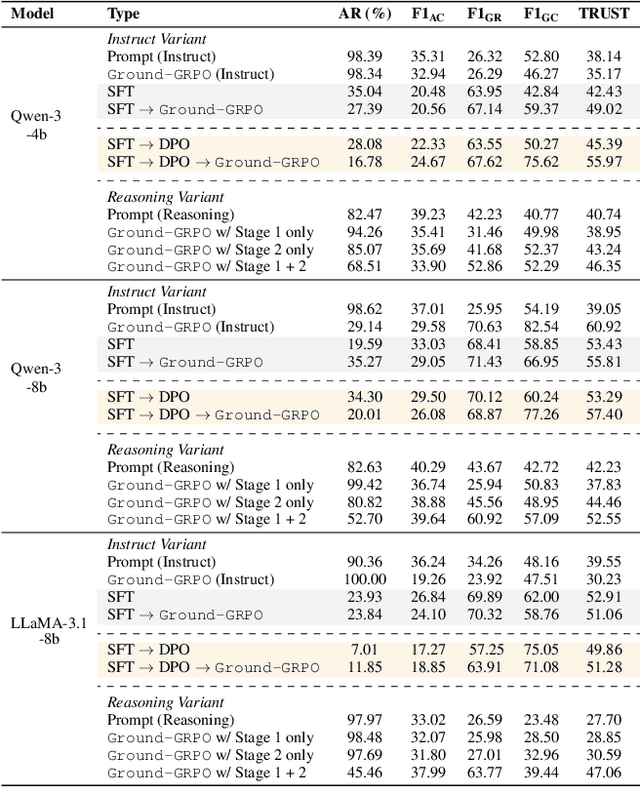
Generating grounded and trustworthy responses remains a key challenge for large language models (LLMs). While retrieval-augmented generation (RAG) with citation-based grounding holds promise, instruction-tuned models frequently fail even in straightforward scenarios: missing explicitly stated answers, citing incorrectly, or refusing when evidence is available. In this work, we explore how reinforcement learning (RL) and internal reasoning can enhance grounding in LLMs. We use the GRPO (Group Relative Policy Optimization) method to train models using verifiable outcome-based rewards targeting answer correctness, citation sufficiency, and refusal quality, without requiring gold reasoning traces or expensive annotations. Through comprehensive experiments across ASQA, QAMPARI, ELI5, and ExpertQA we show that reasoning-augmented models significantly outperform instruction-only variants, especially in handling unanswerable queries and generating well-cited responses. A two-stage training setup, first optimizing answer and citation behavior and then refusal, further improves grounding by stabilizing the learning signal. Additionally, we revisit instruction tuning via GPT-4 distillation and find that combining it with GRPO enhances performance on long-form, generative QA tasks. Overall, our findings highlight the value of reasoning, stage-wise optimization, and outcome-driven RL for building more verifiable and reliable LLMs.
AttentionDrag: Exploiting Latent Correlation Knowledge in Pre-trained Diffusion Models for Image Editing
Jun 16, 2025



Traditional point-based image editing methods rely on iterative latent optimization or geometric transformations, which are either inefficient in their processing or fail to capture the semantic relationships within the image. These methods often overlook the powerful yet underutilized image editing capabilities inherent in pre-trained diffusion models. In this work, we propose a novel one-step point-based image editing method, named AttentionDrag, which leverages the inherent latent knowledge and feature correlations within pre-trained diffusion models for image editing tasks. This framework enables semantic consistency and high-quality manipulation without the need for extensive re-optimization or retraining. Specifically, we reutilize the latent correlations knowledge learned by the self-attention mechanism in the U-Net module during the DDIM inversion process to automatically identify and adjust relevant image regions, ensuring semantic validity and consistency. Additionally, AttentionDrag adaptively generates masks to guide the editing process, enabling precise and context-aware modifications with friendly interaction. Our results demonstrate a performance that surpasses most state-of-the-art methods with significantly faster speeds, showing a more efficient and semantically coherent solution for point-based image editing tasks.
Natural Language Guided Ligand-Binding Protein Design
Jun 11, 2025Can AI protein models follow human language instructions and design proteins with desired functions (e.g. binding to a ligand)? Designing proteins that bind to a given ligand is crucial in a wide range of applications in biology and chemistry. Most prior AI models are trained on protein-ligand complex data, which is scarce due to the high cost and time requirements of laboratory experiments. In contrast, there is a substantial body of human-curated text descriptions about protein-ligand interactions and ligand formula. In this paper, we propose InstructPro, a family of protein generative models that follow natural language instructions to design ligand-binding proteins. Given a textual description of the desired function and a ligand formula in SMILES, InstructPro generates protein sequences that are functionally consistent with the specified instructions. We develop the model architecture, training strategy, and a large-scale dataset, InstructProBench, to support both training and evaluation. InstructProBench consists of 9,592,829 triples of (function description, ligand formula, protein sequence). We train two model variants: InstructPro-1B (with 1 billion parameters) and InstructPro-3B~(with 3 billion parameters). Both variants consistently outperform strong baselines, including ProGen2, ESM3, and Pinal. Notably, InstructPro-1B achieves the highest docking success rate (81.52% at moderate confidence) and the lowest average root mean square deviation (RMSD) compared to ground truth structures (4.026{\AA}). InstructPro-3B further descreases the average RMSD to 2.527{\AA}, demonstrating InstructPro's ability to generate ligand-binding proteins that align with the functional specifications.