 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPO: Expanding Exploration for LLM Agents via Retrieval-Augmented Policy Optimization
Mar 03, 2026Agentic Reinforcement Learning (Agentic RL) has shown remarkable potential in large language model-based (LLM) agents. These works can empower LLM agents to tackle complex tasks via multi-step, tool-integrated reasoning. However, an inherent limitation of existing Agentic RL methods is their reliance on a pure on-policy paradigm for exploration, restricting exploration to the agent's self-generated outputs and preventing the discovery of new reasoning perspectives for further improvement. While recent efforts incorporate auxiliary off-policy signals to enhance exploration, they typically utilize full off-policy trajectories for trajectory-level policy estimation, overlooking the necessity for the fine-grained, step-level exploratory dynamics within agentic rollout. In this paper, we revisit exploration in Agentic RL and propose Retrieval-Augmented Policy Optimization (RAPO), a novel RL framework that introduces retrieval to explicitly expand exploration during training. To achieve this, we decompose the Agentic RL training process into two phases: (i) Hybrid-policy Agentic Rollout, and (ii) Retrieval-aware Policy Optimization. Specifically, we propose a Hybrid-policy Agentic Rollout strategy, which allows the agents to continuously reason over the retrieved off-policy step-level traces. It dynamically extends the reasoning receptive field of agents, enabling broader exploration conditioned on external behaviors. Subsequently, we introduce the Retrieval-aware Policy Optimization mechanism, which calibrates the policy gradient estimation with retrieval reward and importance shaping, stabilizing training and prioritizing retrieval-illuminating exploration. Extensive experiments show that RAPO achieves an +5.0% average gain on fourteen datasets across three agentic reasoning tasks, while delivering 1.2x faster training efficiency.
ShapeCond: Fast Shapelet-Guided Dataset Condensation for Time Series Classification
Feb 09, 2026Time series data supports many domains (e.g., finance and climate science), but its rapid growth strains storage and computation. Dataset condensation can alleviate this by synthesizing a compact training set that preserves key information. Yet most condensation methods are image-centric and often fail on time series because they miss time-series-specific temporal structure, especially local discriminative motifs such as shapelets. In this work, we propose ShapeCond, a novel and efficient condensation framework for time series classification that leverages shapelet-based dataset knowledge via a shapelet-guided optimization strategy. Our shapelet-assisted synthesis cost is independent of sequence length: longer series yield larger speedups in synthesis (e.g., 29$\times$ faster over prior state-of-the-art method CondTSC for time-series condensation, and up to 10,000$\times$ over naively using shapelets on the Sleep dataset with 3,000 timesteps). By explicitly preserving critical local patterns, ShapeCond improves downstream accuracy and consistently outperforms all prior state-of-the-art time series dataset condensation methods across extensive experiments. Code is available at https://github.com/lunaaa95/ShapeCond.
AttentionDrag: Exploiting Latent Correlation Knowledge in Pre-trained Diffusion Models for Image Editing
Jun 16, 2025



Traditional point-based image editing methods rely on iterative latent optimization or geometric transformations, which are either inefficient in their processing or fail to capture the semantic relationships within the image. These methods often overlook the powerful yet underutilized image editing capabilities inherent in pre-trained diffusion models. In this work, we propose a novel one-step point-based image editing method, named AttentionDrag, which leverages the inherent latent knowledge and feature correlations within pre-trained diffusion models for image editing tasks. This framework enables semantic consistency and high-quality manipulation without the need for extensive re-optimization or retraining. Specifically, we reutilize the latent correlations knowledge learned by the self-attention mechanism in the U-Net module during the DDIM inversion process to automatically identify and adjust relevant image regions, ensuring semantic validity and consistency. Additionally, AttentionDrag adaptively generates masks to guide the editing process, enabling precise and context-aware modifications with friendly interaction. Our results demonstrate a performance that surpasses most state-of-the-art methods with significantly faster speeds, showing a more efficient and semantically coherent solution for point-based image editing tasks.
A 2D Semantic-Aware Position Encoding for Vision Transformers
May 14, 2025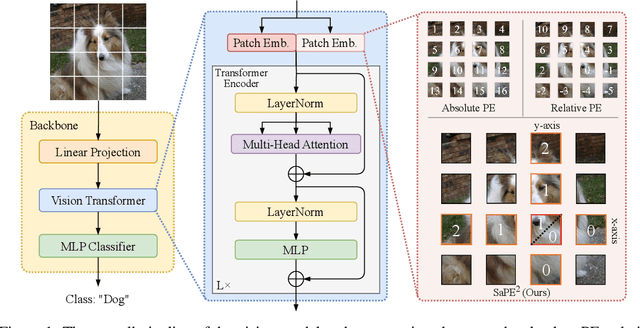
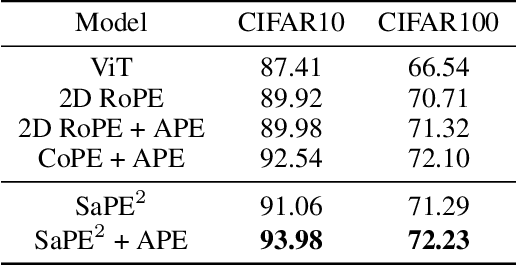
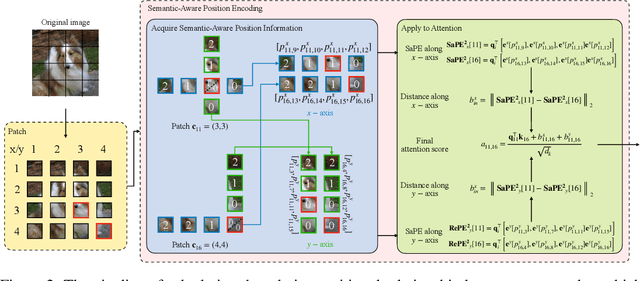
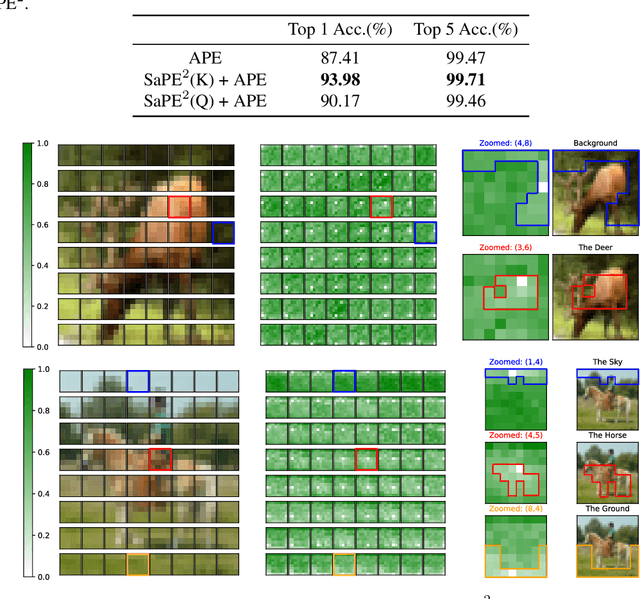
Vision transformers have demonstrated significant advantages in computer vision tasks due to their ability to capture long-range dependencies and contextual relationships through self-attention. However, existing position encoding techniques, which are largely borrowed from natural language processing, fail to effectively capture semantic-aware positional relationships between image patches. Traditional approaches like absolute position encoding and relative position encoding primarily focus on 1D linear position relationship, often neglecting the semantic similarity between distant yet contextually related patches. These limitations hinder model generalization, translation equivariance, and the ability to effectively handle repetitive or structured patterns in images. In this paper, we propose 2-Dimensional Semantic-Aware Position Encoding ($\text{SaPE}^2$), a novel position encoding method with semantic awareness that dynamically adapts position representations by leveraging local content instead of fixed linear position relationship or spatial coordinates. Our method enhances the model's ability to generalize across varying image resolutions and scales, improves translation equivariance, and better aggregates features for visually similar but spatially distant patches. By integrating $\text{SaPE}^2$ into vision transformers, we bridge the gap between position encoding and perceptual similarity, thereby improving performance on computer vision tasks.
Rethinking Time Encoding via Learnable Transformation Functions
May 01, 2025Effectively modeling time information and incorporating it into applications or models involving chronologically occurring events is crucial. Real-world scenarios often involve diverse and complex time patterns, which pose significant challenges for time encoding methods. While previous methods focus on capturing time patterns, many rely on specific inductive biases, such as using trigonometric functions to model periodicity. This narrow focus on single-pattern modeling makes them less effective in handling the diversity and complexities of real-world time patterns. In this paper, we investigate to improve the existing commonly used time encoding methods and introduce Learnable Transformation-based Generalized Time Encoding (LeTE). We propose using deep function learning techniques to parameterize non-linear transformations in time encoding, making them learnable and capable of modeling generalized time patterns, including diverse and complex temporal dynamics. By enabling learnable transformations, LeTE encompasses previous methods as specific cases and allows seamless integration into a wide range of tasks. Through extensive experiments across diverse domains, we demonstrate the versatility and effectiveness of LeTE.
Synergizing RAG and Reasoning: A Systematic Review
Apr 22, 2025



Recent breakthroughs in large language models (LLMs), particularly in reasoning capabilities, have propelled Retrieval-Augmented Generation (RAG) to unprecedented levels. By synergizing retrieval mechanisms with advanced reasoning, LLMs can now tackle increasingly complex problems. This paper presents a systematic review of the collaborative interplay between RAG and reasoning, clearly defining "reasoning" within the RAG context. It construct a comprehensive taxonomy encompassing multi-dimensional collaborative objectives, representative paradigms, and technical implementations, and analyze the bidirectional synergy methods. Additionally, we critically evaluate current limitations in RAG assessment, including the absence of intermediate supervision for multi-step reasoning and practical challenges related to cost-risk trade-offs. To bridge theory and practice, we provide practical guidelines tailored to diverse real-world applications. Finally, we identify promising research directions, such as graph-based knowledge integration, hybrid model collaboration, and RL-driven optimization. Overall, this work presents a theoretical framework and practical foundation to advance RAG systems in academia and industry, fostering the next generation of RAG solutions.
Unifying Text Semantics and Graph Structures for Temporal Text-attributed Graphs with Large Language Models
Mar 18, 2025Temporal graph neural networks (TGNNs) have shown remarkable performance in temporal graph modeling. However, real-world temporal graphs often possess rich textual information, giving rise to temporal text-attributed graphs (TTAGs). Such combination of dynamic text semantics and evolving graph structures introduces heightened complexity. Existing TGNNs embed texts statically and rely heavily on encoding mechanisms that biasedly prioritize structural information, overlooking the temporal evolution of text semantics and the essential interplay between semantics and structures for synergistic reinforcement. To tackle these issues, we present \textbf{{Cross}}, a novel framework that seamlessly extends existing TGNNs for TTAG modeling. The key idea is to employ the advanced large language models (LLMs) to extract the dynamic semantics in text space and then generate expressive representations unifying both semantics and structures. Specifically, we propose a Temporal Semantics Extractor in the {Cross} framework, which empowers the LLM to offer the temporal semantic understanding of node's evolving contexts of textual neighborhoods, facilitating semantic dynamics. Subsequently, we introduce the Semantic-structural Co-encoder, which collaborates with the above Extractor for synthesizing illuminating representations by jointly considering both semantic and structural information while encouraging their mutual reinforcement. Extensive experimental results on four public datasets and one practical industrial dataset demonstrate {Cross}'s significant effectiveness and robustness.
Enhancing Masked Time-Series Modeling via Dropping Patches
Dec 19, 2024



This paper explores how to enhance existing masked time-series modeling by randomly dropping sub-sequence level patches of time series. On this basis, a simple yet effective method named DropPatch is proposed, which has two remarkable advantages: 1) It improves the pre-training efficiency by a square-level advantage; 2) It provides additional advantages for modeling in scenarios such as in-domain, cross-domain, few-shot learning and cold start. This paper conducts comprehensive experiments to verify the effectiveness of the method and analyze its internal mechanism. Empirically, DropPatch strengthens the attention mechanism, reduces information redundancy and serves as an efficient means of data augmentation. Theoretically, it is proved that DropPatch slows down the rate at which the Transformer representations collapse into the rank-1 linear subspace by randomly dropping patches, thus optimizing the quality of the learned representations
An Efficient and Generalizable Symbolic Regression Method for Time Series Analysis
Sep 06, 2024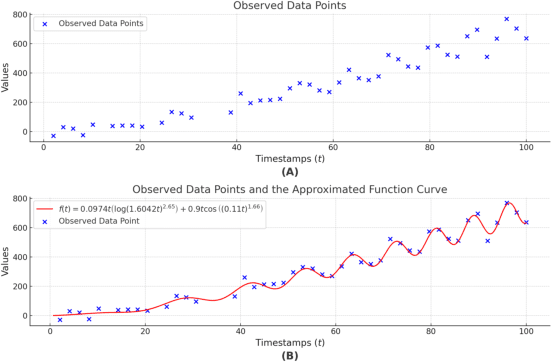

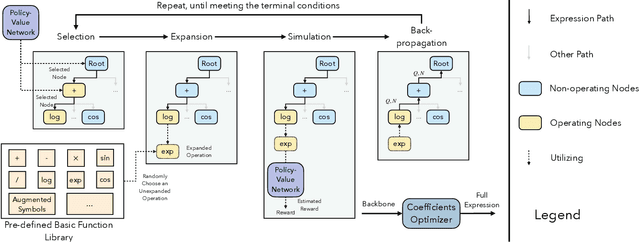
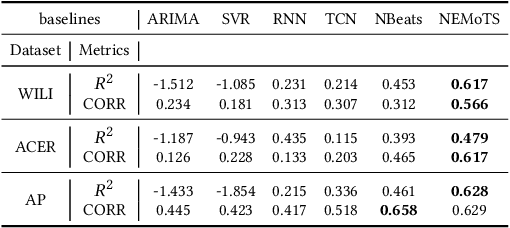
Time series analysis and prediction methods currently excel in quantitative analysis, offering accurate future predictions and diverse statistical indicators, but generally falling short in elucidating the underlying evolution patterns of time series. To gain a more comprehensive understanding and provide insightful explanations, we utilize symbolic regression techniques to derive explicit expressions for the non-linear dynamics in the evolution of time series variables. However, these techniques face challenges in computational efficiency and generalizability across diverse real-world time series data. To overcome these challenges, we propose \textbf{N}eural-\textbf{E}nhanced \textbf{Mo}nte-Carlo \textbf{T}ree \textbf{S}earch (NEMoTS) for time series. NEMoTS leverages the exploration-exploitation balance of Monte-Carlo Tree Search (MCTS), significantly reducing the search space in symbolic regression and improving expression quality. Furthermore, by integrating neural networks with MCTS, NEMoTS not only capitalizes on their superior fitting capabilities to concentrate on more pertinent operations post-search space reduction, but also replaces the complex and time-consuming simulation process, thereby substantially improving computational efficiency and generalizability in time series analysis. NEMoTS offers an efficient and comprehensive approach to time series analysis. Experiments with three real-world datasets demonstrate NEMoTS's significant superiority in performance, efficiency, reliability, and interpretability, making it well-suited for large-scale real-world time series data.
Mamba or Transformer for Time Series Forecasting? Mixture of Universals (MoU) Is All You Need
Aug 28, 2024



Time series forecasting requires balancing short-term and long-term dependencies for accurate predictions. Existing methods mainly focus on long-term dependency modeling, neglecting the complexities of short-term dynamics, which may hinder performance. Transformers are superior in modeling long-term dependencies but are criticized for their quadratic computational cost. Mamba provides a near-linear alternative but is reported less effective in time series longterm forecasting due to potential information loss. Current architectures fall short in offering both high efficiency and strong performance for long-term dependency modeling. To address these challenges, we introduce Mixture of Universals (MoU), a versatile model to capture both short-term and long-term dependencies for enhancing performance in time series forecasting. MoU is composed of two novel designs: Mixture of Feature Extractors (MoF), an adaptive method designed to improve time series patch representations for short-term dependency, and Mixture of Architectures (MoA), which hierarchically integrates Mamba, FeedForward, Convolution, and Self-Attention architectures in a specialized order to model long-term dependency from a hybrid perspective. The proposed approach achieves state-of-the-art performance while maintaining relatively low computational costs. Extensive experiments on seven real-world datasets demonstrate the superiority of MoU. Code is available at https://github.com/lunaaa95/mou/.