 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Textual Knowledge for Enhanced Image Clustering
Apr 13, 2026Image clustering aims to group images in an unsupervised fashion. Traditional methods focus on knowledge from visual space, making it difficult to distinguish between visually similar but semantically different classes. Recent advances in vision-language models enable the use of textual knowledge to enhance image clustering. However, most existing methods rely on coarse class labels or simple nouns, overlooking the rich conceptual and attribute-level semantics embedded in textual space. In this paper, we propose a knowledge-enhanced clustering (KEC) method that constructs a hierarchical concept-attribute structured knowledge with the help of large language models (LLMs) to guide clustering. Specifically, we first condense redundant textual labels into abstract concepts and then automatically extract discriminative attributes for each single concept and similar concept pairs, via structured prompts to LLMs. This knowledge is instantiated for each input image to achieve the knowledge-enhanced features. The knowledge-enhanced features with original visual features are adapted to various downstream clustering algorithms. We evaluate KEC on 20 diverse datasets, showing consistent improvements across existing methods using additional textual knowledge. KEC without training outperforms zero-shot CLIP on 14 out of 20 datasets. Furthermore, the naive use of textual knowledge may harm clustering performance, while KEC provides both accuracy and robustness.
HingeMem: Boundary Guided Long-Term Memory with Query Adaptive Retrieval for Scalable Dialogues
Apr 08, 2026Long-term memory is critical for dialogue systems that support continuous, sustainable, and personalized interactions. However, existing methods rely on continuous summarization or OpenIE-based graph construction paired with fixed Top-\textit{k} retrieval, leading to limited adaptability across query categories and high computational overhead. In this paper, we propose HingeMem, a boundary-guided long-term memory that operationalizes event segmentation theory to build an interpretable indexing interface via boundary-triggered hyperedges over four elements: person, time, location, and topic. When any such element changes, HingeMem draws a boundary and writes the current segment, thereby reducing redundant operations and preserving salient context. To enable robust and efficient retrieval under diverse information needs, HingeMem introduces query-adaptive retrieval mechanisms that jointly decide (a) \textit{what to retrieve}: determine the query-conditioned routing over the element-indexed memory; (b) \textit{how much to retrieve}: control the retrieval depth based on the estimated query type. Extensive experiments across LLM scales (from 0.6B to production-tier models; \textit{e.g.}, Qwen3-0.6B to Qwen-Flash) on LOCOMO show that HingeMem achieves approximately $20\%$ relative improvement over strong baselines without query categories specification, while reducing computational cost (68\%$\downarrow$ question answering token cost compared to HippoRAG2). Beyond advancing memory modeling, HingeMem's adaptive retrieval makes it a strong fit for web applications requiring efficient and trustworthy memory over extended interactions.
Embodied Science: Closing the Discovery Loop with Agentic Embodied AI
Mar 20, 2026Artificial intelligence has demonstrated remarkable capability in predicting scientific properties, yet scientific discovery remains an inherently physical, long-horizon pursuit governed by experimental cycles. Most current computational approaches are misaligned with this reality, framing discovery as isolated, task-specific predictions rather than continuous interaction with the physical world. Here, we argue for embodied science, a paradigm that reframes scientific discovery as a closed loop tightly coupling agentic reasoning with physical execution. We propose a unified Perception-Language-Action-Discovery (PLAD) framework, wherein embodied agents perceive experimental environments, reason over scientific knowledge, execute physical interventions, and internalize outcomes to drive subsequent exploration. By grounding computational reasoning in robust physical feedback, this approach bridges the gap between digital prediction and empirical validation, offering a roadmap for autonomous discovery systems in the life and chemical sciences.
Scene-Aware Memory Discrimination: Deciding Which Personal Knowledge Stays
Feb 12, 2026Intelligent devices have become deeply integrated into everyday life, generating vast amounts of user interactions that form valuable personal knowledge. Efficient organization of this knowledge in user memory is essential for enabling personalized applications. However, current research on memory writing, management, and reading using large language models (LLMs) faces challenges in filtering irrelevant information and in dealing with rising computational costs. Inspired by the concept of selective attention in the human brain, we introduce a memory discrimination task. To address large-scale interactions and diverse memory standards in this task, we propose a Scene-Aware Memory Discrimination method (SAMD), which comprises two key components: the Gating Unit Module (GUM) and the Cluster Prompting Module (CPM). GUM enhances processing efficiency by filtering out non-memorable interactions and focusing on the salient content most relevant to application demands. CPM establishes adaptive memory standards, guiding LLMs to discern what information should be remembered or discarded. It also analyzes the relationship between user intents and memory contexts to build effective clustering prompts. Comprehensive direct and indirect evaluations demonstrate the effectiveness and generalization of our approach. We independently assess the performance of memory discrimination, showing that SAMD successfully recalls the majority of memorable data and remains robust in dynamic scenarios. Furthermore, when integrated into personalized applications, SAMD significantly enhances both the efficiency and quality of memory construction, leading to better organization of personal knowledge.
CitySeeker: How Do VLMS Explore Embodied Urban Navigation With Implicit Human Needs?
Dec 18, 2025Vision-Language Models (VLMs) have made significant progress in explicit instruction-based navigation; however, their ability to interpret implicit human needs (e.g., "I am thirsty") in dynamic urban environments remains underexplored. This paper introduces CitySeeker, a novel benchmark designed to assess VLMs' spatial reasoning and decision-making capabilities for exploring embodied urban navigation to address implicit needs. CitySeeker includes 6,440 trajectories across 8 cities, capturing diverse visual characteristics and implicit needs in 7 goal-driven scenarios. Extensive experiments reveal that even top-performing models (e.g., Qwen2.5-VL-32B-Instruct) achieve only 21.1% task completion. We find key bottlenecks in error accumulation in long-horizon reasoning, inadequate spatial cognition, and deficient experiential recall. To further analyze them, we investigate a series of exploratory strategies-Backtracking Mechanisms, Enriching Spatial Cognition, and Memory-Based Retrieval (BCR), inspired by human cognitive mapping's emphasis on iterative observation-reasoning cycles and adaptive path optimization. Our analysis provides actionable insights for developing VLMs with robust spatial intelligence required for tackling "last-mile" navigation challenges.
Thinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
Nov 14, 2025
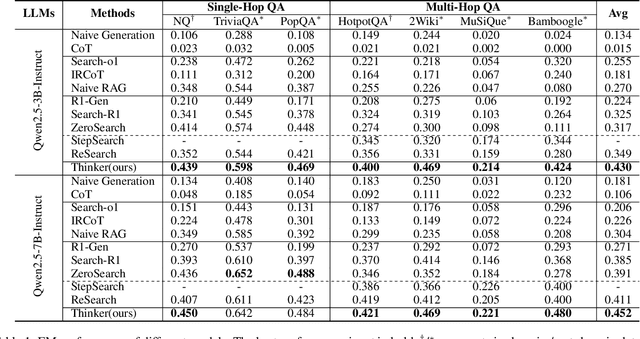
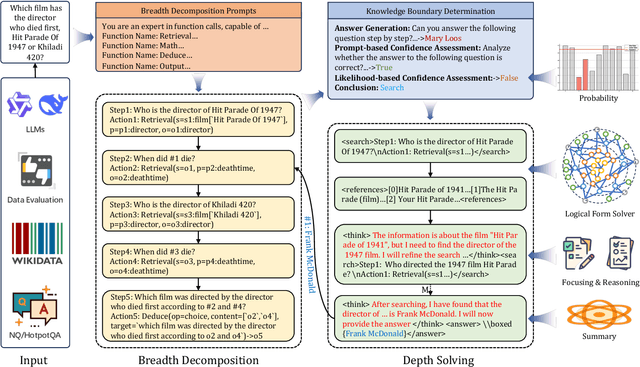
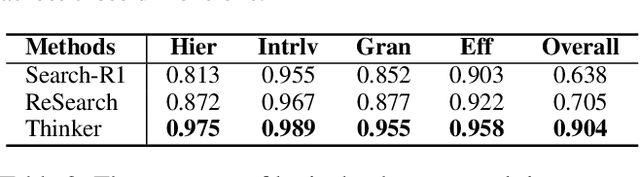
Efficient retrieval of external knowledge bases and web pages is crucial for enhancing the reasoning abilities of LLMs. Previous works on training LLMs to leverage external retrievers for solving complex problems have predominantly employed end-to-end reinforcement learning. However, these approaches neglect supervision over the reasoning process, making it difficult to guarantee logical coherence and rigor. To address these limitations, we propose Thinker, a hierarchical thinking model for deep search through multi-turn interaction, making the reasoning process supervisable and verifiable. It decomposes complex problems into independently solvable sub-problems, each dually represented in both natural language and an equivalent logical function to support knowledge base and web searches. Concurrently, dependencies between sub-problems are passed as parameters via these logical functions, enhancing the logical coherence of the problem-solving process. To avoid unnecessary external searches, we perform knowledge boundary determination to check if a sub-problem is within the LLM's intrinsic knowledge, allowing it to answer directly. Experimental results indicate that with as few as several hundred training samples, the performance of Thinker is competitive with established baselines. Furthermore, when scaled to the full training set, Thinker significantly outperforms these methods across various datasets and model sizes. The source code is available at https://github.com/OpenSPG/KAG-Thinker.
JoyAgent-JDGenie: Technical Report on the GAIA
Oct 01, 2025Large Language Models are increasingly deployed as autonomous agents for complex real-world tasks, yet existing systems often focus on isolated improvements without a unifying design for robustness and adaptability. We propose a generalist agent architecture that integrates three core components: a collective multi-agent framework combining planning and execution agents with critic model voting, a hierarchical memory system spanning working, semantic, and procedural layers, and a refined tool suite for search, code execution, and multimodal parsing. Evaluated on a comprehensive benchmark, our framework consistently outperforms open-source baselines and approaches the performance of proprietary systems. These results demonstrate the importance of system-level integration and highlight a path toward scalable, resilient, and adaptive AI assistants capable of operating across diverse domains and tasks.
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025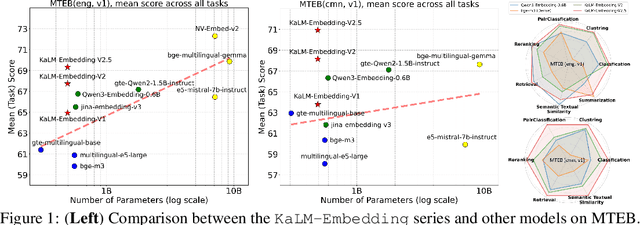
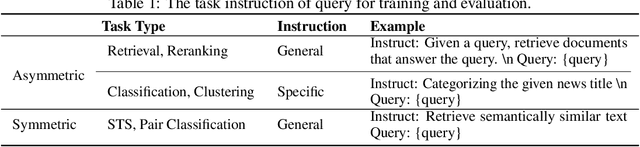


In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
Synergizing RAG and Reasoning: A Systematic Review
Apr 22, 2025



Recent breakthroughs in large language models (LLMs), particularly in reasoning capabilities, have propelled Retrieval-Augmented Generation (RAG) to unprecedented levels. By synergizing retrieval mechanisms with advanced reasoning, LLMs can now tackle increasingly complex problems. This paper presents a systematic review of the collaborative interplay between RAG and reasoning, clearly defining "reasoning" within the RAG context. It construct a comprehensive taxonomy encompassing multi-dimensional collaborative objectives, representative paradigms, and technical implementations, and analyze the bidirectional synergy methods. Additionally, we critically evaluate current limitations in RAG assessment, including the absence of intermediate supervision for multi-step reasoning and practical challenges related to cost-risk trade-offs. To bridge theory and practice, we provide practical guidelines tailored to diverse real-world applications. Finally, we identify promising research directions, such as graph-based knowledge integration, hybrid model collaboration, and RL-driven optimization. Overall, this work presents a theoretical framework and practical foundation to advance RAG systems in academia and industry, fostering the next generation of RAG solutions.