 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinReadNet: A clinical reading-inspired network for low-dose abdominal CT image quality assessment
Jun 09, 2026In abdominal CT imaging, developing a low-dose, no-reference image quality assessment (No-reference IQA) model that mimics doctors' reading habits for evaluating CT image quality has significant practical value. This paper proposes a novel deep learning-based framework, ClinReadNet, whose design aligns with the clinical reading logic of radiologists: first, it introduces the Sobel ordinal quality network (SOQN) module, which can simultaneously focus on edge details highly relevant to image quality and the quality distribution pattern of the entire image, accurately matching the clinical image-reading judgment habit of "considering both local details and overall context"; second, the framework integrates the (shifted) window multi-scale temperature multi-head self-attention ((S)W-MTMSA) module, which further replicates the radiologists' image-reading process of shifting from overall scanning to local focusing, and accurately locks in regions of interest through multi-sharpness attention; third, it designs the hierarchical ranked probability score (HRPS) loss function, which combines the dual logics of coarse classification and fine classification, while paying attention to the distance information between grading labels, effectively improving the performance of image quality assessment. Experiments conducted on the LDCTIQAG2023 dataset show that the proposed method achieves the current state-of-the-art (SOTA) performance: the values of Pearson's linear correlation coefficient (PLCC), Spearman's rank-order correlation coefficient (SROCC), and Kendall's rank-order correlation coefficient (KROCC) reach 0.9507, 0.9554, and 0.8629 respectively, with the sum of their absolute values (Score) being 2.7690, outperforming existing methods.
Exploring Autonomous Agentic Data Engineering for Model Specialization
May 28, 2026Large Language Models (LLMs) have demonstrated strong performance on general tasks, while often struggling to adapt to specialized domains without high-quality domain-specific data. Existing LLM-based data curation methods primarily rely on human-designed workflows, leaving it unexamined whether LLMs can autonomously execute an end-to-end data engineering pipeline for model specialization. We formalize \textbf{Autonomous Agentic Data Engineering}, a novel task designed to evaluate LLMs as autonomous data engineers that drive model specialization through end-to-end data curation. We frame data as an optimizable component and study agents that plan, generate, and iteratively optimize training data across multiple domains, guided by post-training performance improvement. Experiments show that autonomous LLM data engineers yield substantial gains, as GPT-5.2 constructs a training curriculum that improves a student model by \textbf{57.29\%}, entirely through iterative, agent-driven data adaptation. By illuminating both potential and bottlenecks, our study establishes autonomous data engineering as a measurable capability and charts a path toward agent-driven model specialization\footnote{Code will be released at https://github.com/zjunlp/DataAgent.}.
LightThinker++: From Reasoning Compression to Memory Management
Apr 04, 2026Large language models (LLMs) excel at complex reasoning, yet their efficiency is limited by the surging cognitive overhead of long thought traces. In this paper, we propose LightThinker, a method that enables LLMs to dynamically compress intermediate thoughts into compact semantic representations. However, static compression often struggles with complex reasoning where the irreversible loss of intermediate details can lead to logical bottlenecks. To address this, we evolve the framework into LightThinker++, introducing Explicit Adaptive Memory Management. This paradigm shifts to behavioral-level management by incorporating explicit memory primitives, supported by a specialized trajectory synthesis pipeline to train purposeful memory scheduling. Extensive experiments demonstrate the framework's versatility across three dimensions. (1) LightThinker reduces peak token usage by 70% and inference time by 26% with minimal accuracy loss. (2) In standard reasoning, LightThinker++ slashes peak token usage by 69.9% while yielding a +2.42% accuracy gain under the same context budget for maximum performance. (3) Most notably, in long-horizon agentic tasks, it maintains a stable footprint beyond 80 rounds (a 60%-70% reduction), achieving an average performance gain of 14.8% across different complex scenarios. Overall, our work provides a scalable direction for sustaining deep LLM reasoning over extended horizons with minimal overhead.
Can We Predict Before Executing Machine Learning Agents?
Jan 09, 2026Autonomous machine learning agents have revolutionized scientific discovery, yet they remain constrained by a Generate-Execute-Feedback paradigm. Previous approaches suffer from a severe Execution Bottleneck, as hypothesis evaluation relies strictly on expensive physical execution. To bypass these physical constraints, we internalize execution priors to substitute costly runtime checks with instantaneous predictive reasoning, drawing inspiration from World Models. In this work, we formalize the task of Data-centric Solution Preference and construct a comprehensive corpus of 18,438 pairwise comparisons. We demonstrate that LLMs exhibit significant predictive capabilities when primed with a Verified Data Analysis Report, achieving 61.5% accuracy and robust confidence calibration. Finally, we instantiate this framework in FOREAGENT, an agent that employs a Predict-then-Verify loop, achieving a 6x acceleration in convergence while surpassing execution-based baselines by +6%. Our code and dataset will be publicly available soon at https://github.com/zjunlp/predict-before-execute.
RecGPT-V2 Technical Report
Dec 16, 2025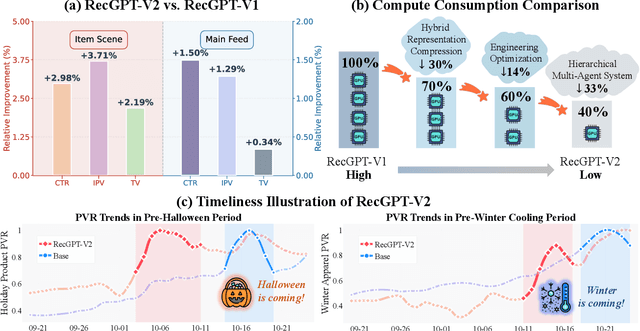
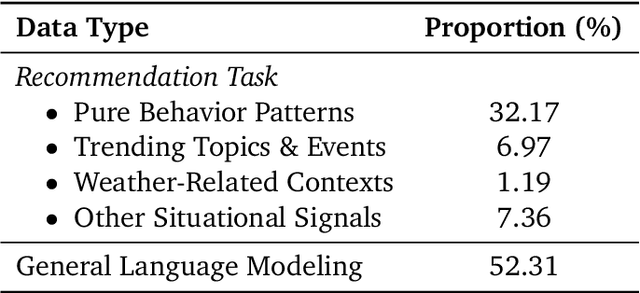
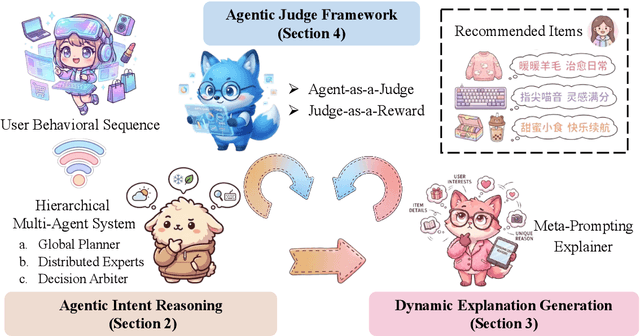

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
Why Do Open-Source LLMs Struggle with Data Analysis? A Systematic Empirical Study
Jun 24, 2025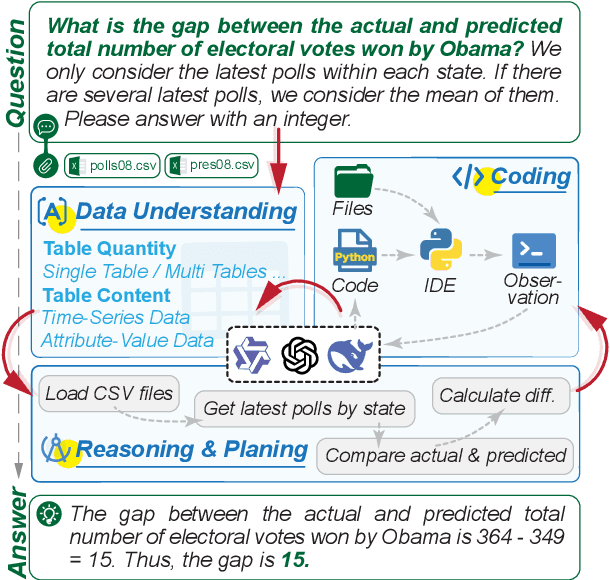
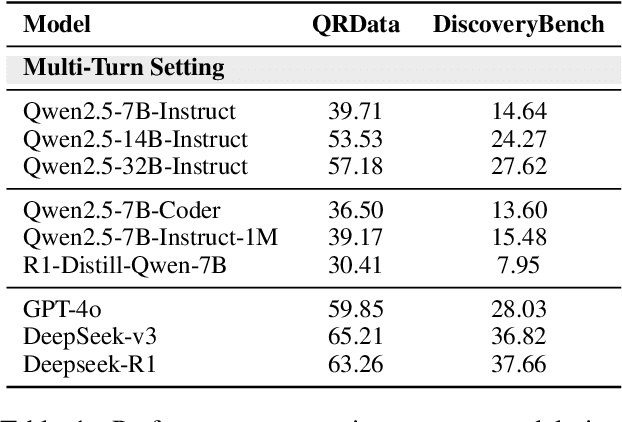
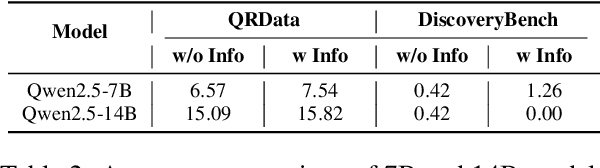
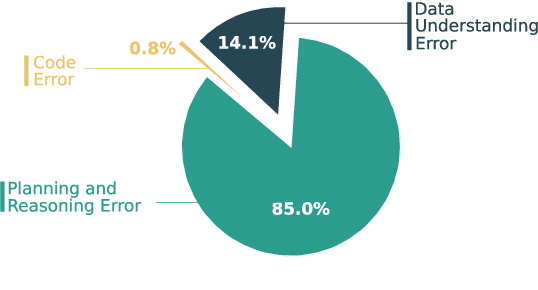
Large Language Models (LLMs) hold promise in automating data analysis tasks, yet open-source models face significant limitations in these kinds of reasoning-intensive scenarios. In this work, we investigate strategies to enhance the data analysis capabilities of open-source LLMs. By curating a seed dataset of diverse, realistic scenarios, we evaluate models across three dimensions: data understanding, code generation, and strategic planning. Our analysis reveals three key findings: (1) Strategic planning quality serves as the primary determinant of model performance; (2) Interaction design and task complexity significantly influence reasoning capabilities; (3) Data quality demonstrates a greater impact than diversity in achieving optimal performance. We leverage these insights to develop a data synthesis methodology, demonstrating significant improvements in open-source LLMs' analytical reasoning capabilities.
AutoMind: Adaptive Knowledgeable Agent for Automated Data Science
Jun 12, 2025Large Language Model (LLM) agents have shown great potential in addressing real-world data science problems. LLM-driven data science agents promise to automate the entire machine learning pipeline, yet their real-world effectiveness remains limited. Existing frameworks depend on rigid, pre-defined workflows and inflexible coding strategies; consequently, they excel only on relatively simple, classical problems and fail to capture the empirical expertise that human practitioners bring to complex, innovative tasks. In this work, we introduce AutoMind, an adaptive, knowledgeable LLM-agent framework that overcomes these deficiencies through three key advances: (1) a curated expert knowledge base that grounds the agent in domain expert knowledge, (2) an agentic knowledgeable tree search algorithm that strategically explores possible solutions, and (3) a self-adaptive coding strategy that dynamically tailors code generation to task complexity. Evaluations on two automated data science benchmarks demonstrate that AutoMind delivers superior performance versus state-of-the-art baselines. Additional analyses confirm favorable effectiveness, efficiency, and qualitative solution quality, highlighting AutoMind as an efficient and robust step toward fully automated data science.
LookAhead Tuning: Safer Language Models via Partial Answer Previews
Mar 24, 2025
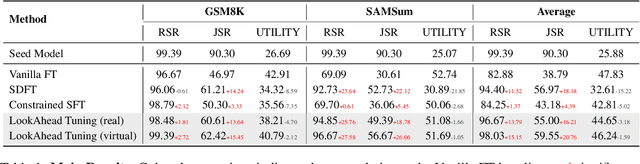
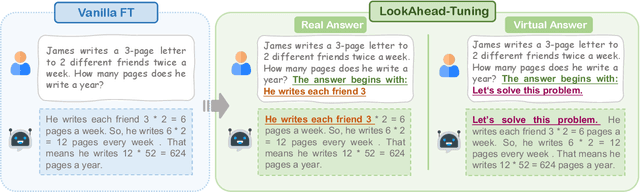
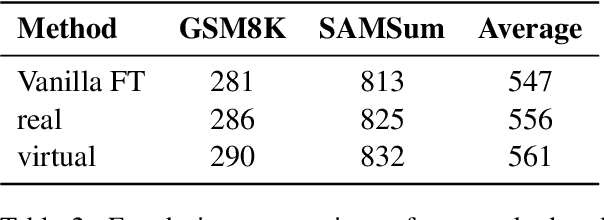
Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often undermines their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, which comprises two simple, low-resource, and effective data-driven methods that modify training data by previewing partial answer prefixes. Both methods aim to preserve the model's inherent safety mechanisms by minimizing perturbations to initial token distributions. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs. Code is released at https://github.com/zjunlp/LookAheadTuning.
LightThinker: Thinking Step-by-Step Compression
Feb 21, 2025Large language models (LLMs) have shown remarkable performance in complex reasoning tasks, but their efficiency is hindered by the substantial memory and computational costs associated with generating lengthy tokens. In this paper, we propose LightThinker, a novel method that enables LLMs to dynamically compress intermediate thoughts during reasoning. Inspired by human cognitive processes, LightThinker compresses verbose thought steps into compact representations and discards the original reasoning chains, thereby significantly reducing the number of tokens stored in the context window. This is achieved by training the model on when and how to perform compression through data construction, mapping hidden states to condensed gist tokens, and creating specialized attention masks. Additionally, we introduce the Dependency (Dep) metric to quantify the degree of compression by measuring the reliance on historical tokens during generation. Extensive experiments on four datasets and two models show that LightThinker reduces peak memory usage and inference time, while maintaining competitive accuracy. Our work provides a new direction for improving the efficiency of LLMs in complex reasoning tasks without sacrificing performance. Code will be released at https://github.com/zjunlp/LightThinker.