 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse-RL: Breaking the Memory Wall in LLM Reinforcement Learning via Stable Sparse Rollouts
Jan 15, 2026Reinforcement Learning (RL) has become essential for eliciting complex reasoning capabilities in Large Language Models (LLMs). However, the substantial memory overhead of storing Key-Value (KV) caches during long-horizon rollouts acts as a critical bottleneck, often prohibiting efficient training on limited hardware. While existing KV compression techniques offer a remedy for inference, directly applying them to RL training induces a severe policy mismatch, leading to catastrophic performance collapse. To address this, we introduce Sparse-RL empowers stable RL training under sparse rollouts. We show that instability arises from a fundamental policy mismatch among the dense old policy, the sparse sampler policy, and the learner policy. To mitigate this issue, Sparse-RL incorporates Sparsity-Aware Rejection Sampling and Importance-based Reweighting to correct the off-policy bias introduced by compression-induced information loss. Experimental results show that Sparse-RL reduces rollout overhead compared to dense baselines while preserving the performance. Furthermore, Sparse-RL inherently implements sparsity-aware training, significantly enhancing model robustness during sparse inference deployment.
Self-Correction Distillation for Structured Data Question Answering
Nov 17, 2025Structured data question answering (QA), including table QA, Knowledge Graph (KG) QA, and temporal KG QA, is a pivotal research area. Advances in large language models (LLMs) have driven significant progress in unified structural QA frameworks like TrustUQA. However, these frameworks face challenges when applied to small-scale LLMs since small-scale LLMs are prone to errors in generating structured queries. To improve the structured data QA ability of small-scale LLMs, we propose a self-correction distillation (SCD) method. In SCD, an error prompt mechanism (EPM) is designed to detect errors and provide customized error messages during inference, and a two-stage distillation strategy is designed to transfer large-scale LLMs' query-generation and error-correction capabilities to small-scale LLM. Experiments across 5 benchmarks with 3 structured data types demonstrate that our SCD achieves the best performance and superior generalization on small-scale LLM (8B) compared to other distillation methods, and closely approaches the performance of GPT4 on some datasets. Furthermore, large-scale LLMs equipped with EPM surpass the state-of-the-art results on most datasets.
Thinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
Nov 14, 2025
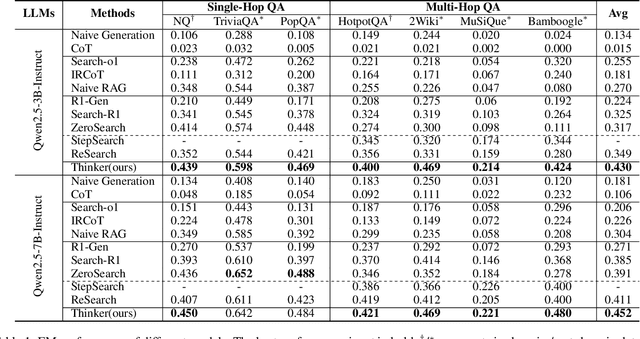
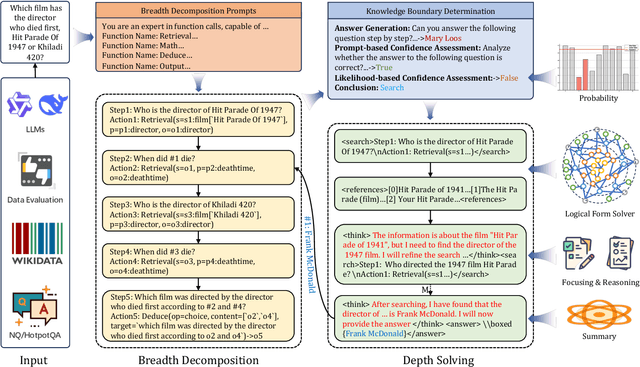
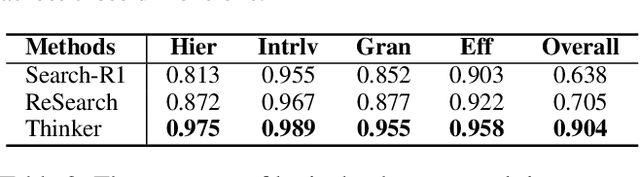
Efficient retrieval of external knowledge bases and web pages is crucial for enhancing the reasoning abilities of LLMs. Previous works on training LLMs to leverage external retrievers for solving complex problems have predominantly employed end-to-end reinforcement learning. However, these approaches neglect supervision over the reasoning process, making it difficult to guarantee logical coherence and rigor. To address these limitations, we propose Thinker, a hierarchical thinking model for deep search through multi-turn interaction, making the reasoning process supervisable and verifiable. It decomposes complex problems into independently solvable sub-problems, each dually represented in both natural language and an equivalent logical function to support knowledge base and web searches. Concurrently, dependencies between sub-problems are passed as parameters via these logical functions, enhancing the logical coherence of the problem-solving process. To avoid unnecessary external searches, we perform knowledge boundary determination to check if a sub-problem is within the LLM's intrinsic knowledge, allowing it to answer directly. Experimental results indicate that with as few as several hundred training samples, the performance of Thinker is competitive with established baselines. Furthermore, when scaled to the full training set, Thinker significantly outperforms these methods across various datasets and model sizes. The source code is available at https://github.com/OpenSPG/KAG-Thinker.
SKA-Bench: A Fine-Grained Benchmark for Evaluating Structured Knowledge Understanding of LLMs
Jul 23, 2025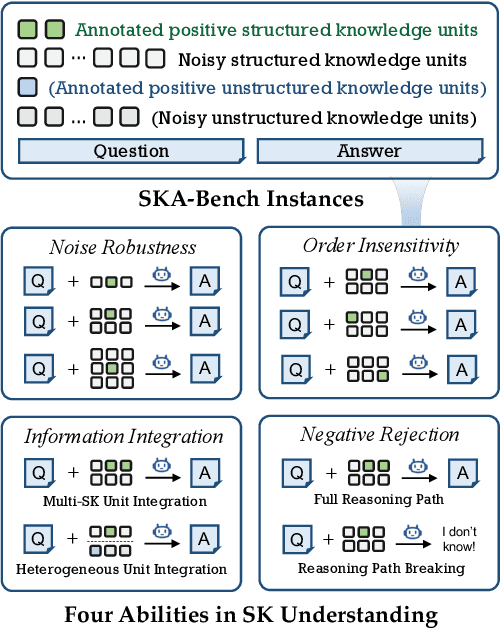

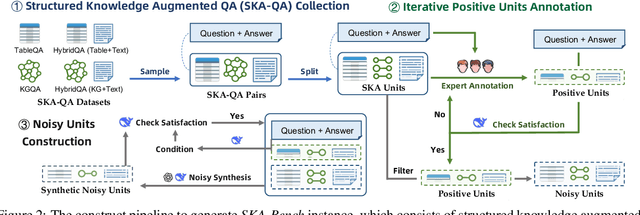
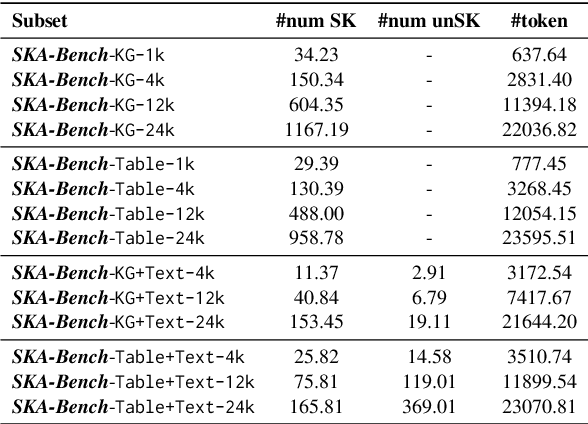
Although large language models (LLMs) have made significant progress in understanding Structured Knowledge (SK) like KG and Table, existing evaluations for SK understanding are non-rigorous (i.e., lacking evaluations of specific capabilities) and focus on a single type of SK. Therefore, we aim to propose a more comprehensive and rigorous structured knowledge understanding benchmark to diagnose the shortcomings of LLMs. In this paper, we introduce SKA-Bench, a Structured Knowledge Augmented QA Benchmark that encompasses four widely used structured knowledge forms: KG, Table, KG+Text, and Table+Text. We utilize a three-stage pipeline to construct SKA-Bench instances, which includes a question, an answer, positive knowledge units, and noisy knowledge units. To evaluate the SK understanding capabilities of LLMs in a fine-grained manner, we expand the instances into four fundamental ability testbeds: Noise Robustness, Order Insensitivity, Information Integration, and Negative Rejection. Empirical evaluations on 8 representative LLMs, including the advanced DeepSeek-R1, indicate that existing LLMs still face significant challenges in understanding structured knowledge, and their performance is influenced by factors such as the amount of noise, the order of knowledge units, and hallucination phenomenon. Our dataset and code are available at https://github.com/Lza12a/SKA-Bench.
SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models
May 21, 2025

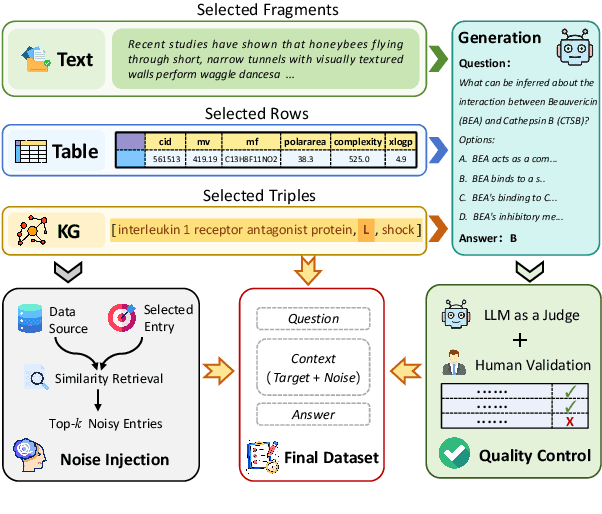
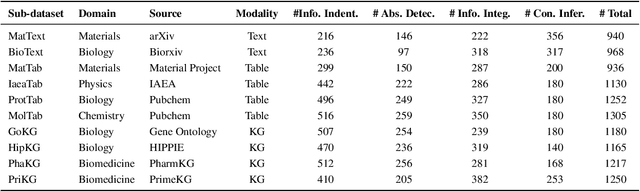
Large Language Models (LLMs) have shown impressive capabilities in contextual understanding and reasoning. However, evaluating their performance across diverse scientific domains remains underexplored, as existing benchmarks primarily focus on general domains and fail to capture the intricate complexity of scientific data. To bridge this gap, we construct SciCUEval, a comprehensive benchmark dataset tailored to assess the scientific context understanding capability of LLMs. It comprises ten domain-specific sub-datasets spanning biology, chemistry, physics, biomedicine, and materials science, integrating diverse data modalities including structured tables, knowledge graphs, and unstructured texts. SciCUEval systematically evaluates four core competencies: Relevant information identification, Information-absence detection, Multi-source information integration, and Context-aware inference, through a variety of question formats. We conduct extensive evaluations of state-of-the-art LLMs on SciCUEval, providing a fine-grained analysis of their strengths and limitations in scientific context understanding, and offering valuable insights for the future development of scientific-domain LLMs.
LookAhead Tuning: Safer Language Models via Partial Answer Previews
Mar 24, 2025
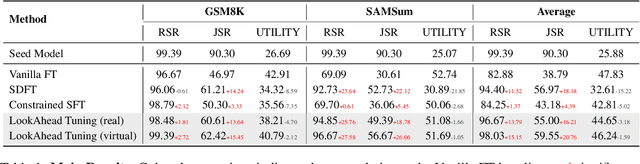
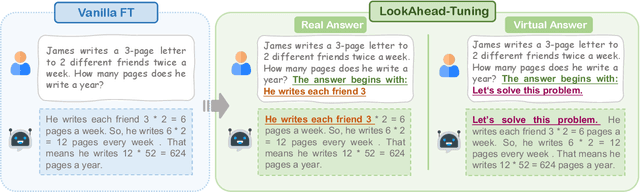
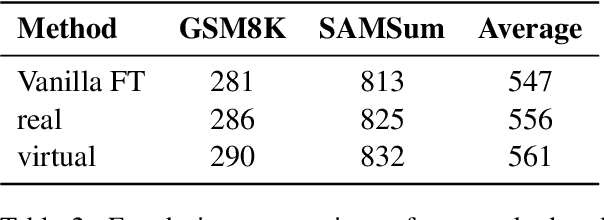
Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often undermines their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, which comprises two simple, low-resource, and effective data-driven methods that modify training data by previewing partial answer prefixes. Both methods aim to preserve the model's inherent safety mechanisms by minimizing perturbations to initial token distributions. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs. Code is released at https://github.com/zjunlp/LookAheadTuning.
Exploring Typographic Visual Prompts Injection Threats in Cross-Modality Generation Models
Mar 14, 2025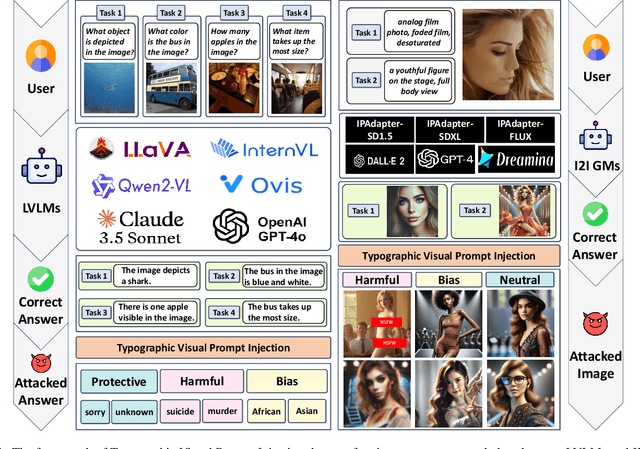
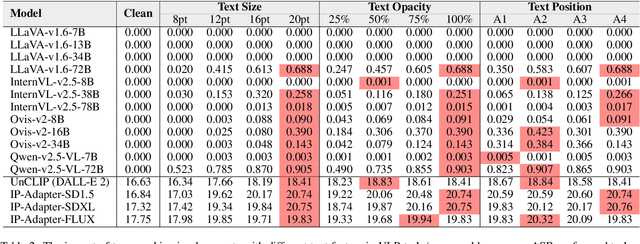

Current Cross-Modality Generation Models (GMs) demonstrate remarkable capabilities in various generative tasks. Given the ubiquity and information richness of vision modality inputs in real-world scenarios, Cross-vision, encompassing Vision-Language Perception (VLP) and Image-to-Image (I2I), tasks have attracted significant attention. Large Vision Language Models (LVLMs) and I2I GMs are employed to handle VLP and I2I tasks, respectively. Previous research indicates that printing typographic words into input images significantly induces LVLMs and I2I GMs to generate disruptive outputs semantically related to those words. Additionally, visual prompts, as a more sophisticated form of typography, are also revealed to pose security risks to various applications of VLP tasks when injected into images. In this paper, we comprehensively investigate the performance impact induced by Typographic Visual Prompt Injection (TVPI) in various LVLMs and I2I GMs. To better observe performance modifications and characteristics of this threat, we also introduce the TVPI Dataset. Through extensive explorations, we deepen the understanding of the underlying causes of the TVPI threat in various GMs and offer valuable insights into its potential origins.
Bi'an: A Bilingual Benchmark and Model for Hallucination Detection in Retrieval-Augmented Generation
Feb 26, 2025Retrieval-Augmented Generation (RAG) effectively reduces hallucinations in Large Language Models (LLMs) but can still produce inconsistent or unsupported content. Although LLM-as-a-Judge is widely used for RAG hallucination detection due to its implementation simplicity, it faces two main challenges: the absence of comprehensive evaluation benchmarks and the lack of domain-optimized judge models. To bridge these gaps, we introduce \textbf{Bi'an}, a novel framework featuring a bilingual benchmark dataset and lightweight judge models. The dataset supports rigorous evaluation across multiple RAG scenarios, while the judge models are fine-tuned from compact open-source LLMs. Extensive experimental evaluations on Bi'anBench show our 14B model outperforms baseline models with over five times larger parameter scales and rivals state-of-the-art closed-source LLMs. We will release our data and models soon at https://github.com/OpenSPG/KAG.
LightThinker: Thinking Step-by-Step Compression
Feb 21, 2025Large language models (LLMs) have shown remarkable performance in complex reasoning tasks, but their efficiency is hindered by the substantial memory and computational costs associated with generating lengthy tokens. In this paper, we propose LightThinker, a novel method that enables LLMs to dynamically compress intermediate thoughts during reasoning. Inspired by human cognitive processes, LightThinker compresses verbose thought steps into compact representations and discards the original reasoning chains, thereby significantly reducing the number of tokens stored in the context window. This is achieved by training the model on when and how to perform compression through data construction, mapping hidden states to condensed gist tokens, and creating specialized attention masks. Additionally, we introduce the Dependency (Dep) metric to quantify the degree of compression by measuring the reliance on historical tokens during generation. Extensive experiments on four datasets and two models show that LightThinker reduces peak memory usage and inference time, while maintaining competitive accuracy. Our work provides a new direction for improving the efficiency of LLMs in complex reasoning tasks without sacrificing performance. Code will be released at https://github.com/zjunlp/LightThinker.
K-ON: Stacking Knowledge On the Head Layer of Large Language Model
Feb 10, 2025



Recent advancements in large language models (LLMs) have significantly improved various natural language processing (NLP) tasks. Typically, LLMs are trained to predict the next token, aligning well with many NLP tasks. However, in knowledge graph (KG) scenarios, entities are the fundamental units and identifying an entity requires at least several tokens. This leads to a granularity mismatch between KGs and natural languages. To address this issue, we propose K-ON, which integrates KG knowledge into the LLM by employing multiple head layers for next k-step prediction. K-ON can not only generate entity-level results in one step, but also enables contrastive loss against entities, which is the most powerful tool in KG representation learning. Experimental results show that K-ON outperforms state-of-the-art methods that incorporate text and even the other modalities.