 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Natural Language Understanding for LLMs via Large-Scale Instruction Synthesis
Feb 06, 2025



High-quality, large-scale instructions are crucial for aligning large language models (LLMs), however, there is a severe shortage of instruction in the field of natural language understanding (NLU). Previous works on constructing NLU instructions mainly focus on information extraction (IE), neglecting tasks such as machine reading comprehension, question answering, and text classification. Furthermore, the lack of diversity in the data has led to a decreased generalization ability of trained LLMs in other NLU tasks and a noticeable decline in the fundamental model's general capabilities. To address this issue, we propose Hum, a large-scale, high-quality synthetic instruction corpus for NLU tasks, designed to enhance the NLU capabilities of LLMs. Specifically, Hum includes IE (either close IE or open IE), machine reading comprehension, text classification, and instruction generalist tasks, thereby enriching task diversity. Additionally, we introduce a human-LLMs collaborative mechanism to synthesize instructions, which enriches instruction diversity by incorporating guidelines, preference rules, and format variants. We conduct extensive experiments on 5 NLU tasks and 28 general capability evaluation datasets for LLMs. Experimental results show that Hum enhances the NLU capabilities of six LLMs by an average of 3.1\%, with no significant decline observed in other general capabilities.
IEPile: Unearthing Large-Scale Schema-Based Information Extraction Corpus
Feb 22, 2024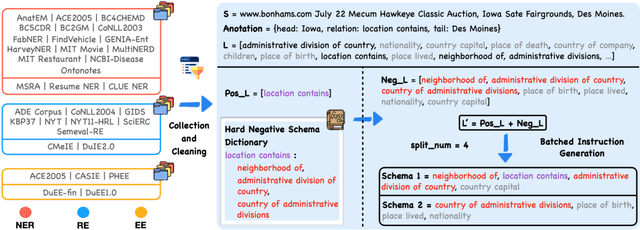
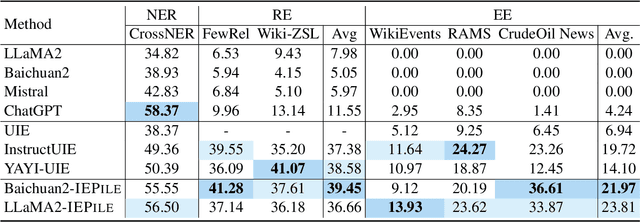
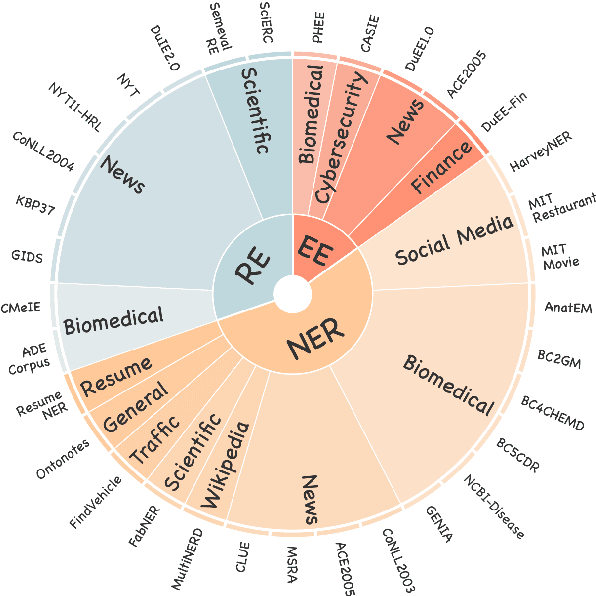
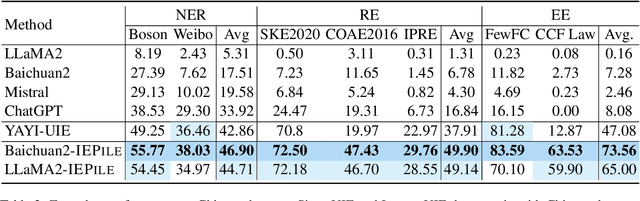
Large Language Models (LLMs) demonstrate remarkable potential across various domains; however, they exhibit a significant performance gap in Information Extraction (IE). Note that high-quality instruction data is the vital key for enhancing the specific capabilities of LLMs, while current IE datasets tend to be small in scale, fragmented, and lack standardized schema. To this end, we introduce IEPile, a comprehensive bilingual (English and Chinese) IE instruction corpus, which contains approximately 0.32B tokens. We construct IEPile by collecting and cleaning 33 existing IE datasets, and introduce schema-based instruction generation to unearth a large-scale corpus. Experimental results on LLaMA and Baichuan demonstrate that using IEPile can enhance the performance of LLMs for IE, especially the zero-shot generalization. We open-source the resource and pre-trained models, hoping to provide valuable support to the NLP community.
EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models
Feb 06, 2024



In recent years, instruction tuning has gained increasing attention and emerged as a crucial technique to enhance the capabilities of Large Language Models (LLMs). To construct high-quality instruction datasets, many instruction processing approaches have been proposed, aiming to achieve a delicate balance between data quantity and data quality. Nevertheless, due to inconsistencies that persist among various instruction processing methods, there is no standard open-source instruction processing implementation framework available for the community, which hinders practitioners from further developing and advancing. To facilitate instruction processing research and development, we present EasyInstruct, an easy-to-use instruction processing framework for LLMs, which modularizes instruction generation, selection, and prompting, while also considering their combination and interaction. EasyInstruct is publicly released and actively maintained at https://github.com/zjunlp/EasyInstruct, along with a running demo App at https://huggingface.co/spaces/zjunlp/EasyInstruct for quick-start, calling for broader research centered on instruction data.
Beyond Isolation: Multi-Agent Synergy for Improving Knowledge Graph Construction
Dec 05, 2023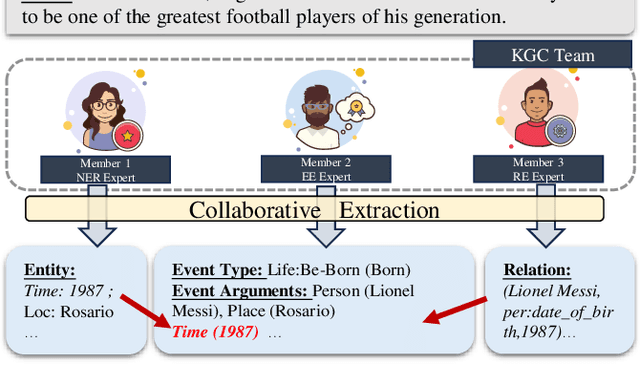


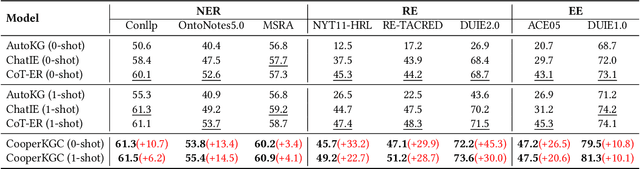
Knowledge graph construction (KGC) is a multifaceted undertaking involving the extraction of entities, relations, and events. Traditionally, large language models (LLMs) have been viewed as solitary task-solving agents in this complex landscape. However, this paper challenges this paradigm by introducing a novel framework, CooperKGC. Departing from the conventional approach, CooperKGC establishes a collaborative processing network, assembling a KGC collaboration team capable of concurrently addressing entity, relation, and event extraction tasks. Our experiments unequivocally demonstrate that fostering collaboration and information interaction among diverse agents within CooperKGC yields superior results compared to individual cognitive processes operating in isolation. Importantly, our findings reveal that the collaboration facilitated by CooperKGC enhances knowledge selection, correction, and aggregation capabilities across multiple rounds of interactions.
Unveiling the Siren's Song: Towards Reliable Fact-Conflicting Hallucination Detection
Oct 18, 2023



Large Language Models (LLMs), such as ChatGPT/GPT-4, have garnered widespread attention owing to their myriad of practical applications, yet their adoption has been constrained by issues of fact-conflicting hallucinations across web platforms. The assessment of factuality in text, produced by LLMs, remains inadequately explored, extending not only to the judgment of vanilla facts but also encompassing the evaluation of factual errors emerging in complex inferential tasks like multi-hop, and etc. In response, we introduce FactCHD, a fact-conflicting hallucination detection benchmark meticulously designed for LLMs. Functioning as a pivotal tool in evaluating factuality within "Query-Respons" contexts, our benchmark assimilates a large-scale dataset, encapsulating a broad spectrum of factuality patterns, such as vanilla, multi-hops, comparison, and set-operation patterns. A distinctive feature of our benchmark is its incorporation of fact-based chains of evidence, thereby facilitating comprehensive and conducive factual reasoning throughout the assessment process. We evaluate multiple LLMs, demonstrating the effectiveness of the benchmark and current methods fall short of faithfully detecting factual errors. Furthermore, we present TRUTH-TRIANGULATOR that synthesizes reflective considerations by tool-enhanced ChatGPT and LoRA-tuning based on Llama2, aiming to yield more credible detection through the amalgamation of predictive results and evidence. The benchmark dataset and source code will be made available in https://github.com/zjunlp/FactCHD.
Making Language Models Better Tool Learners with Execution Feedback
May 22, 2023

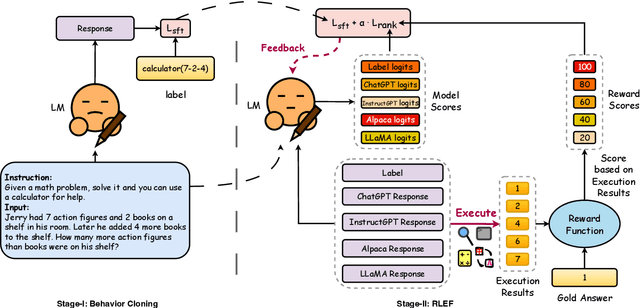
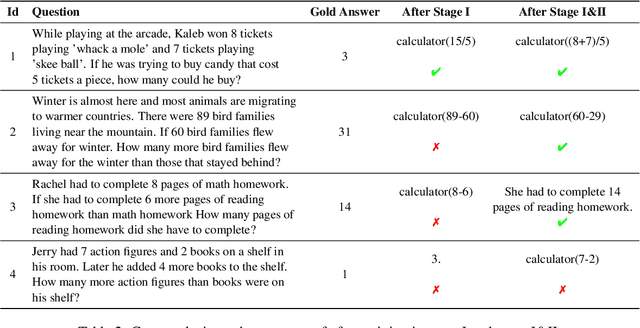
Tools serve as pivotal interfaces that enable humans to understand and reshape the world. With the advent of foundational models, AI systems can utilize tools to expand their capabilities and interact with the world. Existing tool learning methodologies, encompassing supervised fine-tuning and prompt engineering approaches, often induce language models to utilize tools indiscriminately, as complex problems often exceed their own competencies. However, introducing tools for simple tasks, which the models themselves can readily resolve, can inadvertently propagate errors rather than enhance performance. This leads to the research question: can we teach language models when and how to use tools? To meet this need, we propose Tool leaRning wIth exeCution fEedback (TRICE), a two-stage end-to-end framework that enables the model to continually learn through feedback derived from tool execution, thereby learning when and how to use tools effectively. Experimental results, backed by further analysis, show that TRICE can make the language model to selectively use tools by decreasing the model's dependency on tools while enhancing the performance. Code and datasets will be available in https://github.com/zjunlp/trice.
Schema-adaptable Knowledge Graph Construction
May 19, 2023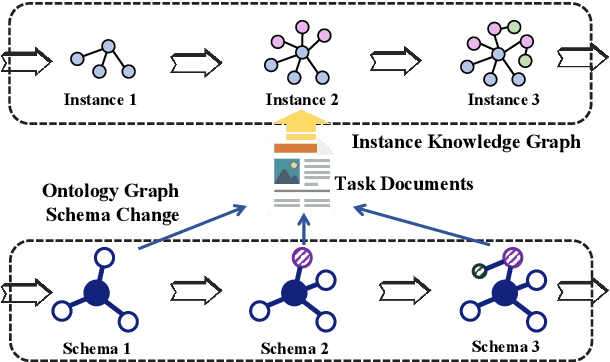
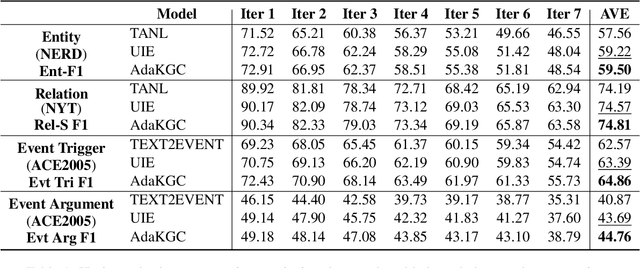
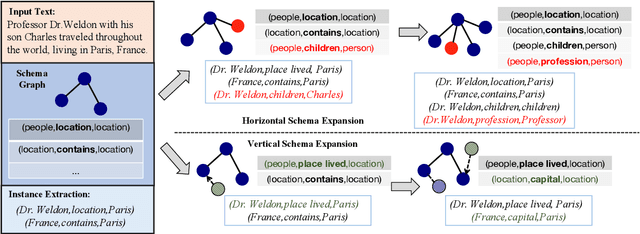
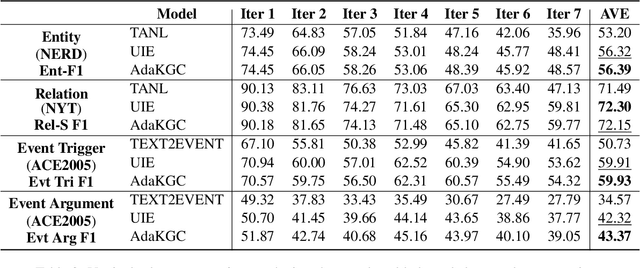
Conventional Knowledge Graph Construction (KGC) approaches typically follow the static information extraction paradigm with a closed set of pre-defined schema. As a result, such approaches fall short when applied to dynamic scenarios or domains, whereas a new type of knowledge emerges. This necessitates a system that can handle evolving schema automatically to extract information for KGC. To address this need, we propose a new task called schema-adaptable KGC, which aims to continually extract entity, relation, and event based on a dynamically changing schema graph without re-training. We first split and convert existing datasets based on three principles to build a benchmark, i.e., horizontal schema expansion, vertical schema expansion, and hybrid schema expansion; then investigate the schema-adaptable performance of several well-known approaches such as Text2Event, TANL, UIE and GPT-3.5. We further propose a simple yet effective baseline dubbed AdaKGC, which contains schema-enriched prefix instructor and schema-conditioned dynamic decoding to better handle evolving schema. Comprehensive experimental results illustrate that AdaKGC can outperform baselines but still have room for improvement. We hope the proposed work can deliver benefits to the community. Code and datasets will be available in https://github.com/zjunlp/AdaKGC.
InstructIE: A Chinese Instruction-based Information Extraction Dataset
May 19, 2023



We introduce a new Information Extraction (IE) task dubbed Instruction-based IE, which aims to ask the system to follow specific instructions or guidelines to extract information. To facilitate research in this area, we construct a dataset called InstructIE, consisting of 270,000 weakly supervised data from Chinese Wikipedia and 1,000 high-quality crowdsourced annotated instances. We further evaluate the performance of various baseline models on the InstructIE dataset. The results reveal that although current models exhibit promising performance, there is still room for improvement. Furthermore, we conduct a comprehensive case study analysis, underlining the challenges inherent in the Instruction-based IE task. Code and dataset are available at https://github.com/zjunlp/DeepKE/tree/main/example/llm.