 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergizing Multigrid Algorithms with Vision Transformer: A Novel Approach to Enhance the Seismic Foundation Model
Nov 17, 2025
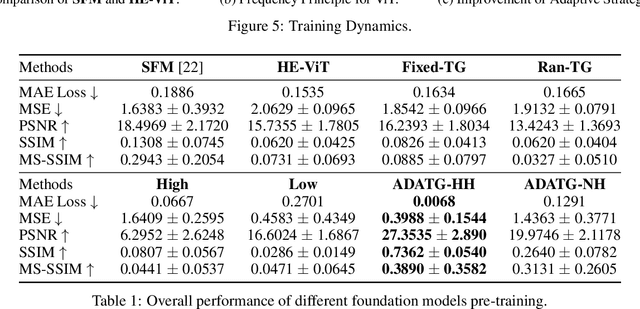


Due to the emergency and homogenization of Artificial Intelligence (AI) technology development, transformer-based foundation models have revolutionized scientific applications, such as drug discovery, materials research, and astronomy. However, seismic data presents unique characteristics that require specialized processing techniques for pretraining foundation models in seismic contexts with high- and low-frequency features playing crucial roles. Existing vision transformers (ViTs) with sequential tokenization ignore the intrinsic pattern and fail to grasp both the high- and low-frequency seismic information efficiently and effectively. This work introduces a novel adaptive two-grid foundation model training strategy (ADATG) with Hilbert encoding specifically tailored for seismogram data, leveraging the hierarchical structures inherent in seismic data. Specifically, our approach employs spectrum decomposition to separate high- and low-frequency components and utilizes hierarchical Hilbert encoding to represent the data effectively. Moreover, observing the frequency principle observed in ViTs, we propose an adaptive training strategy that initially emphasizes coarse-level information and then progressively refines the model's focus on fine-level features. Our extensive experiments demonstrate the effectiveness and efficiency of our training methods. This research highlights the importance of data encoding and training strategies informed by the distinct characteristics of high- and low-frequency features in seismic images, ultimately contributing to the enhancement of visual seismic foundation models pretraining.
IEPile: Unearthing Large-Scale Schema-Based Information Extraction Corpus
Feb 22, 2024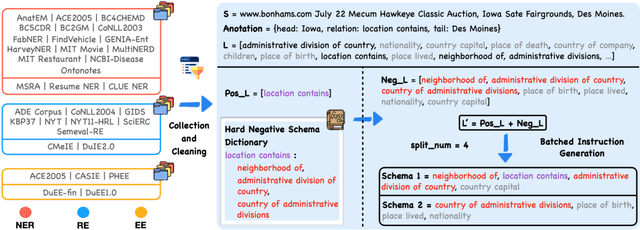
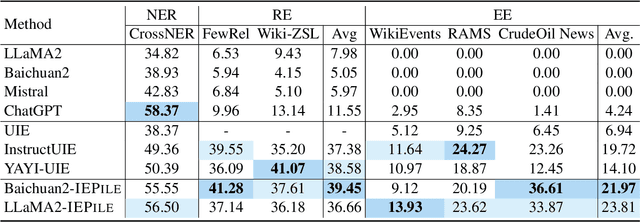
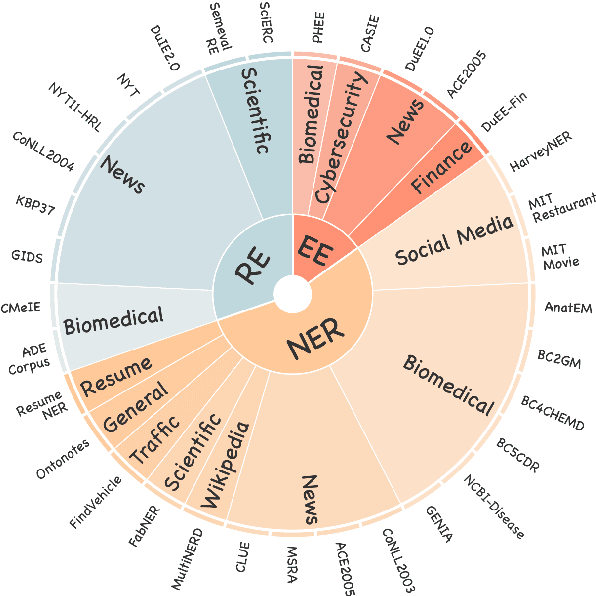
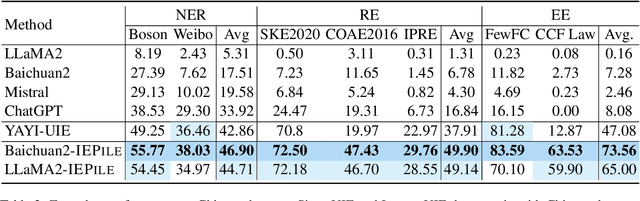
Large Language Models (LLMs) demonstrate remarkable potential across various domains; however, they exhibit a significant performance gap in Information Extraction (IE). Note that high-quality instruction data is the vital key for enhancing the specific capabilities of LLMs, while current IE datasets tend to be small in scale, fragmented, and lack standardized schema. To this end, we introduce IEPile, a comprehensive bilingual (English and Chinese) IE instruction corpus, which contains approximately 0.32B tokens. We construct IEPile by collecting and cleaning 33 existing IE datasets, and introduce schema-based instruction generation to unearth a large-scale corpus. Experimental results on LLaMA and Baichuan demonstrate that using IEPile can enhance the performance of LLMs for IE, especially the zero-shot generalization. We open-source the resource and pre-trained models, hoping to provide valuable support to the NLP community.
Beyond Isolation: Multi-Agent Synergy for Improving Knowledge Graph Construction
Dec 05, 2023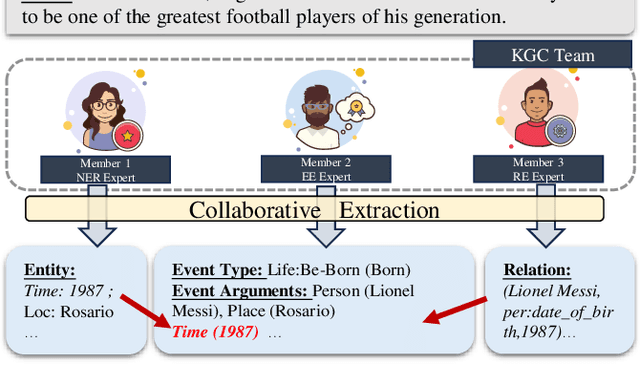


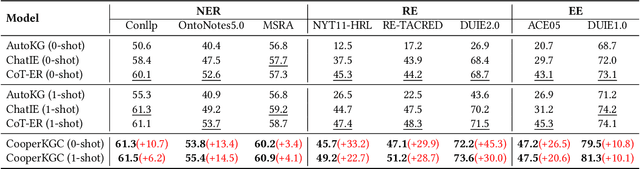
Knowledge graph construction (KGC) is a multifaceted undertaking involving the extraction of entities, relations, and events. Traditionally, large language models (LLMs) have been viewed as solitary task-solving agents in this complex landscape. However, this paper challenges this paradigm by introducing a novel framework, CooperKGC. Departing from the conventional approach, CooperKGC establishes a collaborative processing network, assembling a KGC collaboration team capable of concurrently addressing entity, relation, and event extraction tasks. Our experiments unequivocally demonstrate that fostering collaboration and information interaction among diverse agents within CooperKGC yields superior results compared to individual cognitive processes operating in isolation. Importantly, our findings reveal that the collaboration facilitated by CooperKGC enhances knowledge selection, correction, and aggregation capabilities across multiple rounds of interactions.
Cognitive Mirage: A Review of Hallucinations in Large Language Models
Sep 13, 2023



As large language models continue to develop in the field of AI, text generation systems are susceptible to a worrisome phenomenon known as hallucination. In this study, we summarize recent compelling insights into hallucinations in LLMs. We present a novel taxonomy of hallucinations from various text generation tasks, thus provide theoretical insights, detection methods and improvement approaches. Based on this, future research directions are proposed. Our contribution are threefold: (1) We provide a detailed and complete taxonomy for hallucinations appearing in text generation tasks; (2) We provide theoretical analyses of hallucinations in LLMs and provide existing detection and improvement methods; (3) We propose several research directions that can be developed in the future. As hallucinations garner significant attention from the community, we will maintain updates on relevant research progress.
InstructIE: A Chinese Instruction-based Information Extraction Dataset
May 19, 2023



We introduce a new Information Extraction (IE) task dubbed Instruction-based IE, which aims to ask the system to follow specific instructions or guidelines to extract information. To facilitate research in this area, we construct a dataset called InstructIE, consisting of 270,000 weakly supervised data from Chinese Wikipedia and 1,000 high-quality crowdsourced annotated instances. We further evaluate the performance of various baseline models on the InstructIE dataset. The results reveal that although current models exhibit promising performance, there is still room for improvement. Furthermore, we conduct a comprehensive case study analysis, underlining the challenges inherent in the Instruction-based IE task. Code and dataset are available at https://github.com/zjunlp/DeepKE/tree/main/example/llm.
Schema-adaptable Knowledge Graph Construction
May 19, 2023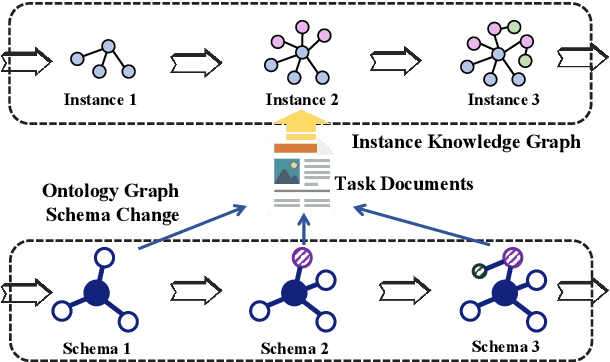
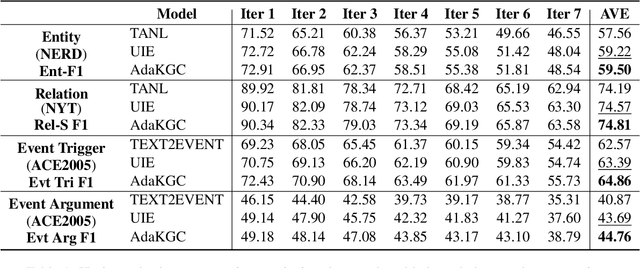
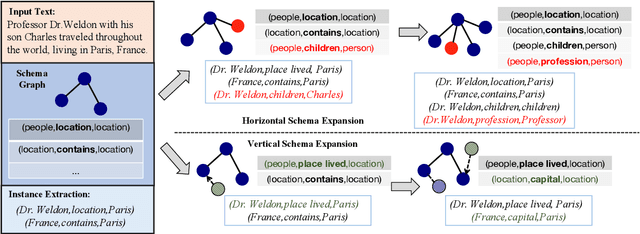
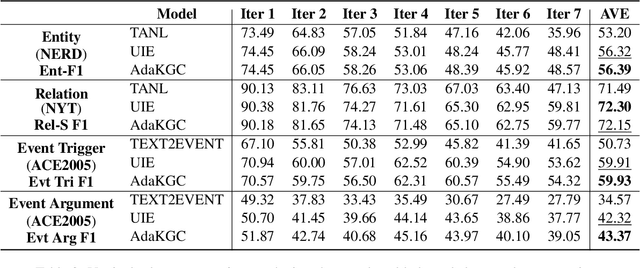
Conventional Knowledge Graph Construction (KGC) approaches typically follow the static information extraction paradigm with a closed set of pre-defined schema. As a result, such approaches fall short when applied to dynamic scenarios or domains, whereas a new type of knowledge emerges. This necessitates a system that can handle evolving schema automatically to extract information for KGC. To address this need, we propose a new task called schema-adaptable KGC, which aims to continually extract entity, relation, and event based on a dynamically changing schema graph without re-training. We first split and convert existing datasets based on three principles to build a benchmark, i.e., horizontal schema expansion, vertical schema expansion, and hybrid schema expansion; then investigate the schema-adaptable performance of several well-known approaches such as Text2Event, TANL, UIE and GPT-3.5. We further propose a simple yet effective baseline dubbed AdaKGC, which contains schema-enriched prefix instructor and schema-conditioned dynamic decoding to better handle evolving schema. Comprehensive experimental results illustrate that AdaKGC can outperform baselines but still have room for improvement. We hope the proposed work can deliver benefits to the community. Code and datasets will be available in https://github.com/zjunlp/AdaKGC.
Generative Knowledge Graph Construction: A Review
Oct 23, 2022



Generative Knowledge Graph Construction (KGC) refers to those methods that leverage the sequence-to-sequence framework for building knowledge graphs, which is flexible and can be adapted to widespread tasks. In this study, we summarize the recent compelling progress in generative knowledge graph construction. We present the advantages and weaknesses of each paradigm in terms of different generation targets and provide theoretical insight and empirical analysis. Based on the review, we suggest promising research directions for the future. Our contributions are threefold: (1) We present a detailed, complete taxonomy for the generative KGC methods; (2) We provide a theoretical and empirical analysis of the generative KGC methods; (3) We propose several research directions that can be developed in the future.
Ontology-enhanced Prompt-tuning for Few-shot Learning
Jan 27, 2022



Few-shot Learning (FSL) is aimed to make predictions based on a limited number of samples. Structured data such as knowledge graphs and ontology libraries has been leveraged to benefit the few-shot setting in various tasks. However, the priors adopted by the existing methods suffer from challenging knowledge missing, knowledge noise, and knowledge heterogeneity, which hinder the performance for few-shot learning. In this study, we explore knowledge injection for FSL with pre-trained language models and propose ontology-enhanced prompt-tuning (OntoPrompt). Specifically, we develop the ontology transformation based on the external knowledge graph to address the knowledge missing issue, which fulfills and converts structure knowledge to text. We further introduce span-sensitive knowledge injection via a visible matrix to select informative knowledge to handle the knowledge noise issue. To bridge the gap between knowledge and text, we propose a collective training algorithm to optimize representations jointly. We evaluate our proposed OntoPrompt in three tasks, including relation extraction, event extraction, and knowledge graph completion, with eight datasets. Experimental results demonstrate that our approach can obtain better few-shot performance than baselines.
DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Jan 24, 2022
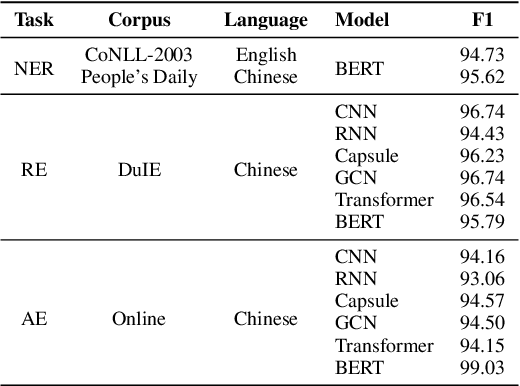
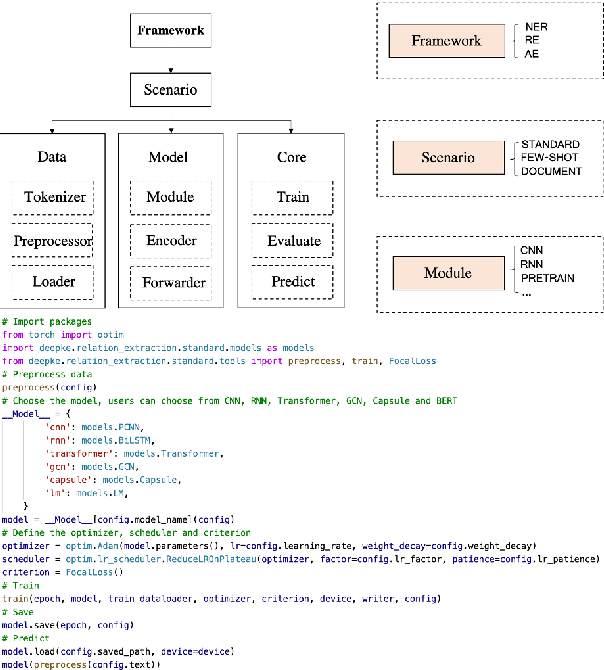
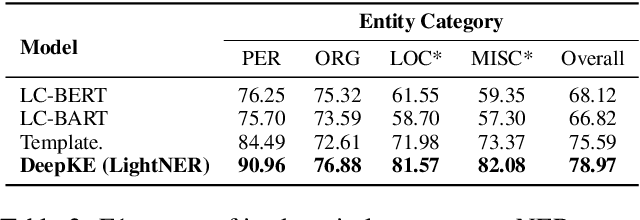
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE (Deep learning based Knowledge Extraction), supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different tasks and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Besides, we present an online platform in http://deepke.zjukg.cn/ for real-time extraction of various tasks. DeepKE has been equipped with Google Colab tutorials and comprehensive documents for beginners. We release the source code at https://github.com/zjunlp/DeepKE, with a demo video.
LOGEN: Few-shot Logical Knowledge-Conditioned Text Generation with Self-training
Dec 02, 2021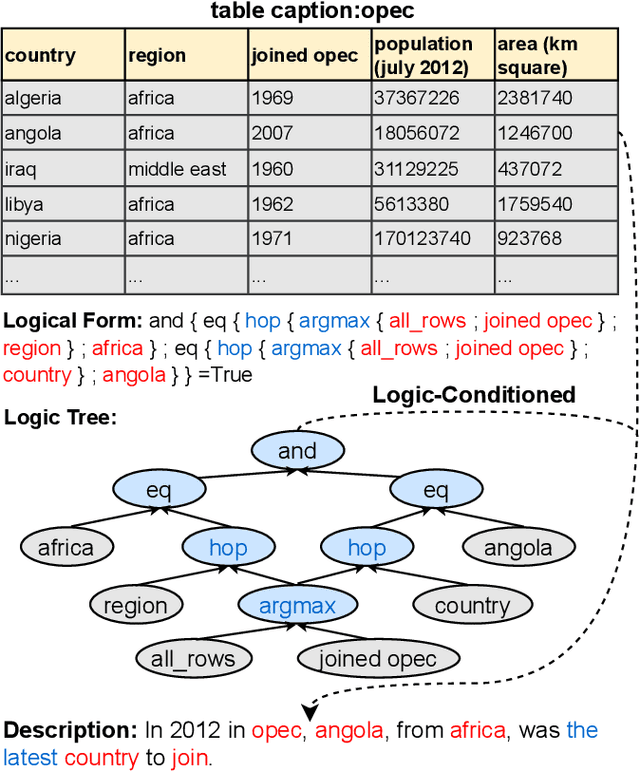
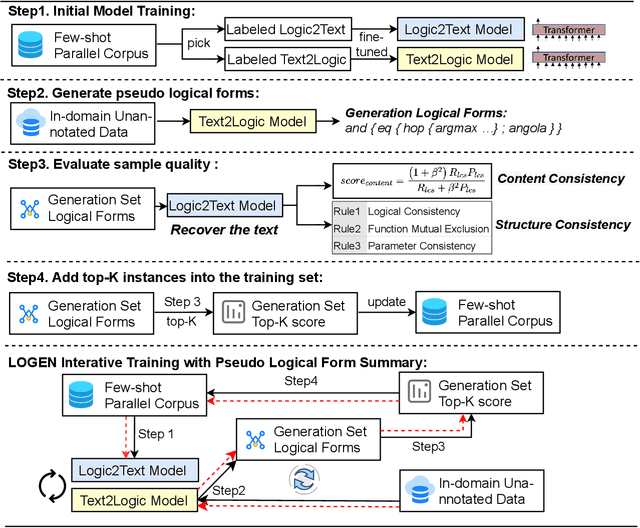
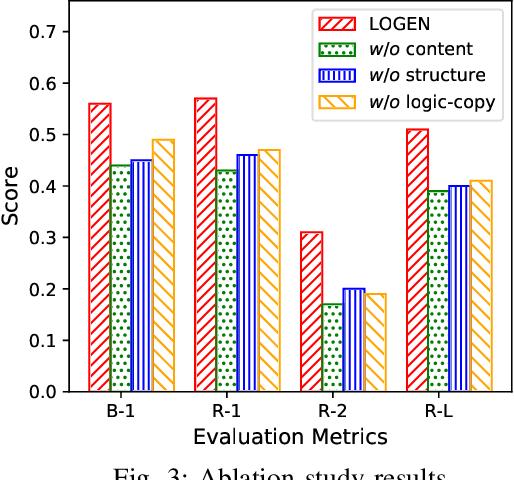

Natural language generation from structured data mainly focuses on surface-level descriptions, suffering from uncontrollable content selection and low fidelity. Previous works leverage logical forms to facilitate logical knowledge-conditioned text generation. Though achieving remarkable progress, they are data-hungry, which makes the adoption for real-world applications challenging with limited data. To this end, this paper proposes a unified framework for logical knowledge-conditioned text generation in the few-shot setting. With only a few seeds logical forms (e.g., 20/100 shot), our approach leverages self-training and samples pseudo logical forms based on content and structure consistency. Experimental results demonstrate that our approach can obtain better few-shot performance than baselines.