 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Impairs the Balancedness of Foundation Models in Long-tailed Personalized Federated Learning
May 04, 2026Personalized federated learning (PFL) with foundation models has emerged as a promising paradigm enabling clients to adapt to heterogeneous data distributions. However, real-world scenarios often face the co-occurrence of non-IID data and long-tailed class distributions, presenting unique challenges that remain underexplored in PFL. In this paper, we investigate this long-tailed personalized federated learning and observe that current methods suffer from two limitations: (i) fine-tuning degrades performance below zero-shot baselines due to the erosion of inherent class balance in foundation models; (ii) conventional personalization techniques further transfer this bias to local models through parameter or feature-level fusion. To address these challenges, we propose Federated Learning via Gradient Purification and Residual Learning (FedPuReL), which preserves balanced knowledge in the global model while enabling unbiased personalization. Specifically, we purify local gradients using zero-shot predictions to maintain a class-balanced global model, and model personalization as residual correction atop the frozen global model. Extensive experiments demonstrate that FedPuReL consistently outperforms state-of-the-art methods, achieving superior performance on both global and personalized models across diverse long-tailed scenarios. The code is available at https://github.com/shihaohou/FedPuReL.
Annotation-Free Visual Reasoning for High-Resolution Large Multimodal Models via Reinforcement Learning
Feb 27, 2026Current Large Multimodal Models (LMMs) struggle with high-resolution visual inputs during the reasoning process, as the number of image tokens increases quadratically with resolution, introducing substantial redundancy and irrelevant information. A common practice is to identify key image regions and refer to their high-resolution counterparts during reasoning, typically trained with external visual supervision. However, such visual supervision cues require costly grounding labels from human annotators. Meanwhile, it remains an open question how to enhance a model's grounding abilities to support reasoning without relying on additional annotations. In this paper, we propose High-resolution Annotation-free Reasoning Technique (HART), a closed-loop framework that enables LMMs to focus on and self-verify key regions of high-resolution visual inputs. HART incorporates a post-training paradigm in which we design Advantage Preference Group Relative Policy Optimization (AP-GRPO) to encourage accurate localization of key regions. Notably, HART provides explainable reasoning pathways and enables efficient optimization of localization. Extensive experiments demonstrate that HART improves performance across a wide range of high-resolution visual tasks, consistently outperforming strong baselines. When applied to post-train Qwen2.5-VL-7B, HART even surpasses larger-scale models such as Qwen2.5-VL-72B and LLaVA-OneVision-72B on high-resolution, vision-centric benchmarks.
veScale-FSDP: Flexible and High-Performance FSDP at Scale
Feb 25, 2026Fully Sharded Data Parallel (FSDP), also known as ZeRO, is widely used for training large-scale models, featuring its flexibility and minimal intrusion on model code. However, current FSDP systems struggle with structure-aware training methods (e.g., block-wise quantized training) and with non-element-wise optimizers (e.g., Shampoo and Muon) used in cutting-edge models (e.g., Gemini, Kimi K2). FSDP's fixed element- or row-wise sharding formats conflict with the block-structured computations. In addition, today's implementations fall short in communication and memory efficiency, limiting scaling to tens of thousands of GPUs. We introduce veScale-FSDP, a redesigned FSDP system that couples a flexible sharding format, RaggedShard, with a structure-aware planning algorithm to deliver both flexibility and performance at scale. veScale-FSDP natively supports efficient data placement required by FSDP, empowering block-wise quantization and non-element-wise optimizers. As a result, veScale-FSDP achieves 5~66% higher throughput and 16~30% lower memory usage than existing FSDP systems, while scaling efficiently to tens of thousands of GPUs.
StreamFusion: Scalable Sequence Parallelism for Distributed Inference of Diffusion Transformers on GPUs
Jan 28, 2026Diffusion Transformers (DiTs) have gained increasing adoption in high-quality image and video generation. As demand for higher-resolution images and longer videos increases, single-GPU inference becomes inefficient due to increased latency and large activation sizes. Current frameworks employ sequence parallelism (SP) techniques such as Ulysses Attention and Ring Attention to scale inference. However, these implementations have three primary limitations: (1) suboptimal communication patterns for network topologies on modern GPU machines, (2) latency bottlenecks from all-to-all operations in inter-machine communication, and (3) GPU sender-receiver synchronization and computation overheads from using two-sided communication libraries. To address these issues, we present StreamFusion, a topology-aware efficient DiT serving engine. StreamFusion incorporates three key innovations: (1) a topology-aware sequence parallelism technique that accounts for inter- and intra-machine bandwidth differences, (2) Torus Attention, a novel SP technique enabling overlapping of inter-machine all-to-all operations with computation, and (3) a one-sided communication implementation that minimizes GPU sender-receiver synchronization and computation overheads. Our experiments demonstrate that StreamFusion outperforms the state-of-the-art approach by an average of $1.35\times$ (up to $1.77\times$).
FUSE-RSVLM: Feature Fusion Vision-Language Model for Remote Sensing
Dec 30, 2025Large vision-language models (VLMs) exhibit strong performance across various tasks. However, these VLMs encounter significant challenges when applied to the remote sensing domain due to the inherent differences between remote sensing images and natural images. Existing remote sensing VLMs often fail to extract fine-grained visual features and suffer from visual forgetting during deep language processing. To address this, we introduce MF-RSVLM, a Multi-Feature Fusion Remote Sensing Vision--Language Model that effectively extracts and fuses visual features for RS understanding. MF-RSVLM learns multi-scale visual representations and combines global context with local details, improving the capture of small and complex structures in RS scenes. A recurrent visual feature injection scheme ensures the language model remains grounded in visual evidence and reduces visual forgetting during generation. Extensive experiments on diverse RS benchmarks show that MF-RSVLM achieves state-of-the-art or highly competitive performance across remote sensing classification, image captioning, and VQA tasks. Our code is publicly available at https://github.com/Yunkaidang/RSVLM.
A Benchmark for Ultra-High-Resolution Remote Sensing MLLMs
Dec 19, 2025Multimodal large language models (MLLMs) demonstrate strong perception and reasoning performance on existing remote sensing (RS) benchmarks. However, most prior benchmarks rely on low-resolution imagery, and some high-resolution benchmarks suffer from flawed reasoning-task designs. We show that text-only LLMs can perform competitively with multimodal vision-language models on RS reasoning tasks without access to images, revealing a critical mismatch between current benchmarks and the intended evaluation of visual understanding. To enable faithful assessment, we introduce RSHR-Bench, a super-high-resolution benchmark for RS visual understanding and reasoning. RSHR-Bench contains 5,329 full-scene images with a long side of at least 4,000 pixels, with up to about 3 x 10^8 pixels per image, sourced from widely used RS corpora and UAV collections. We design four task families: multiple-choice VQA, open-ended VQA, image captioning, and single-image evaluation. These tasks cover nine perception categories and four reasoning types, supporting multi-turn and multi-image dialog. To reduce reliance on language priors, we apply adversarial filtering with strong LLMs followed by rigorous human verification. Overall, we construct 3,864 VQA tasks, 3,913 image captioning tasks, and 500 fully human-written or verified single-image evaluation VQA pairs. Evaluations across open-source, closed-source, and RS-specific VLMs reveal persistent performance gaps in super-high-resolution scenarios. Code: https://github.com/Yunkaidang/RSHR
Static Batching of Irregular Workloads on GPUs: Framework and Application to Efficient MoE Model Inference
Jan 27, 2025
It has long been a problem to arrange and execute irregular workloads on massively parallel devices. We propose a general framework for statically batching irregular workloads into a single kernel with a runtime task mapping mechanism on GPUs. We further apply this framework to Mixture-of-Experts (MoE) model inference and implement an optimized and efficient CUDA kernel. Our MoE kernel achieves up to 91% of the peak Tensor Core throughput on NVIDIA H800 GPU and 95% on NVIDIA H20 GPU.
CTA-Net: A CNN-Transformer Aggregation Network for Improving Multi-Scale Feature Extraction
Oct 15, 2024
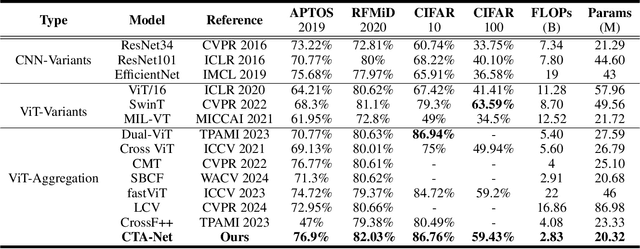
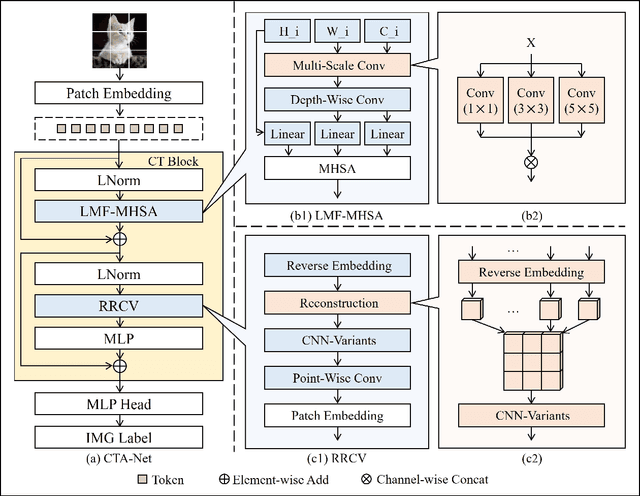
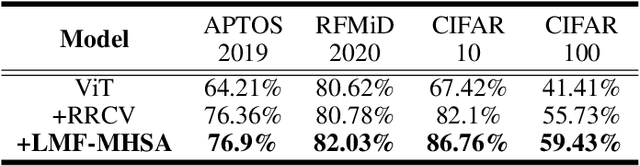
Convolutional neural networks (CNNs) and vision transformers (ViTs) have become essential in computer vision for local and global feature extraction. However, aggregating these architectures in existing methods often results in inefficiencies. To address this, the CNN-Transformer Aggregation Network (CTA-Net) was developed. CTA-Net combines CNNs and ViTs, with transformers capturing long-range dependencies and CNNs extracting localized features. This integration enables efficient processing of detailed local and broader contextual information. CTA-Net introduces the Light Weight Multi-Scale Feature Fusion Multi-Head Self-Attention (LMF-MHSA) module for effective multi-scale feature integration with reduced parameters. Additionally, the Reverse Reconstruction CNN-Variants (RRCV) module enhances the embedding of CNNs within the transformer architecture. Extensive experiments on small-scale datasets with fewer than 100,000 samples show that CTA-Net achieves superior performance (TOP-1 Acc 86.76\%), fewer parameters (20.32M), and greater efficiency (FLOPs 2.83B), making it a highly efficient and lightweight solution for visual tasks on small-scale datasets (fewer than 100,000).
Accelerating Graph Neural Networks on Real Processing-In-Memory Systems
Feb 26, 2024



Graph Neural Networks (GNNs) are emerging ML models to analyze graph-structure data. Graph Neural Network (GNN) execution involves both compute-intensive and memory-intensive kernels, the latter dominates the total time, being significantly bottlenecked by data movement between memory and processors. Processing-In-Memory (PIM) systems can alleviate this data movement bottleneck by placing simple processors near or inside to memory arrays. In this work, we introduce PyGim, an efficient ML framework that accelerates GNNs on real PIM systems. We propose intelligent parallelization techniques for memory-intensive kernels of GNNs tailored for real PIM systems, and develop handy Python API for them. We provide hybrid GNN execution, in which the compute-intensive and memory-intensive kernels are executed in processor-centric and memory-centric computing systems, respectively, to match their algorithmic nature. We extensively evaluate PyGim on a real-world PIM system with 1992 PIM cores using emerging GNN models, and demonstrate that it outperforms its state-of-the-art CPU counterpart on Intel Xeon by on average 3.04x, and achieves higher resource utilization than CPU and GPU systems. Our work provides useful recommendations for software, system and hardware designers. PyGim will be open-sourced to enable the widespread use of PIM systems in GNNs.
LOGEN: Few-shot Logical Knowledge-Conditioned Text Generation with Self-training
Dec 02, 2021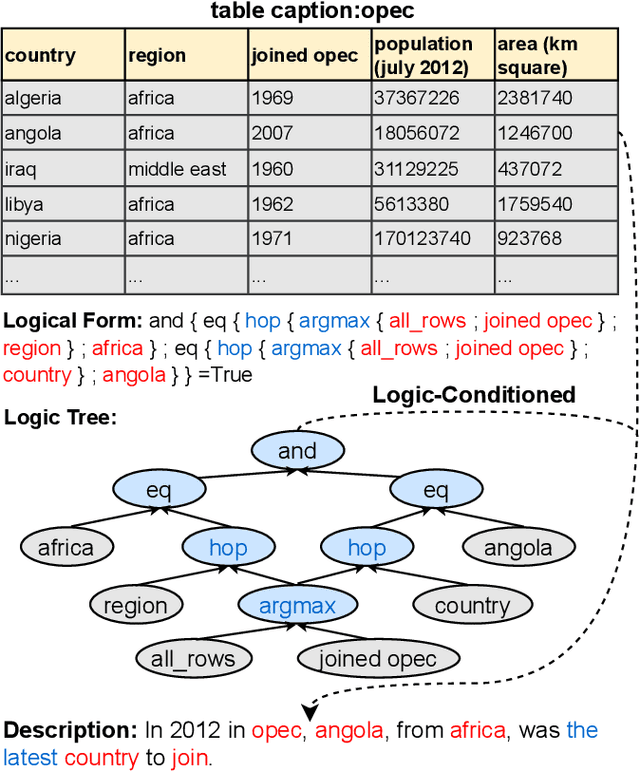
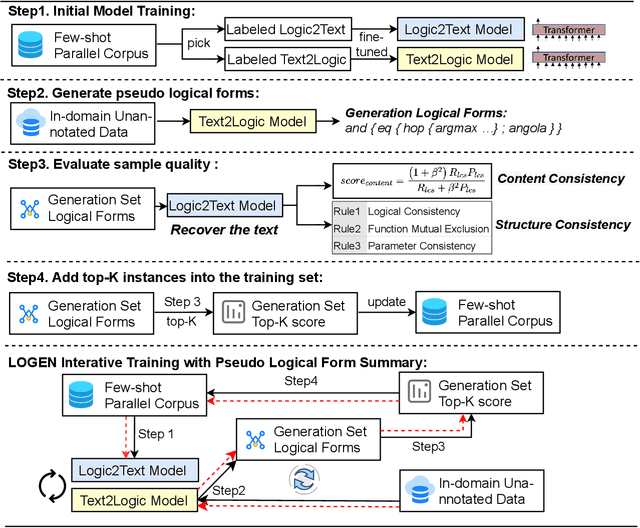
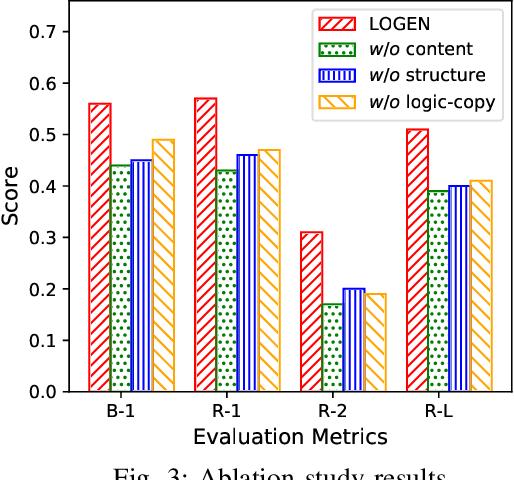

Natural language generation from structured data mainly focuses on surface-level descriptions, suffering from uncontrollable content selection and low fidelity. Previous works leverage logical forms to facilitate logical knowledge-conditioned text generation. Though achieving remarkable progress, they are data-hungry, which makes the adoption for real-world applications challenging with limited data. To this end, this paper proposes a unified framework for logical knowledge-conditioned text generation in the few-shot setting. With only a few seeds logical forms (e.g., 20/100 shot), our approach leverages self-training and samples pseudo logical forms based on content and structure consistency. Experimental results demonstrate that our approach can obtain better few-shot performance than baselines.