 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Tell and Summarize: Dense Video Captioning Using Visual Cue Aided Sentence Summarization
Jun 25, 2025In this work, we propose a division-and-summarization (DaS) framework for dense video captioning. After partitioning each untrimmed long video as multiple event proposals, where each event proposal consists of a set of short video segments, we extract visual feature (e.g., C3D feature) from each segment and use the existing image/video captioning approach to generate one sentence description for this segment. Considering that the generated sentences contain rich semantic descriptions about the whole event proposal, we formulate the dense video captioning task as a visual cue aided sentence summarization problem and propose a new two stage Long Short Term Memory (LSTM) approach equipped with a new hierarchical attention mechanism to summarize all generated sentences as one descriptive sentence with the aid of visual features. Specifically, the first-stage LSTM network takes all semantic words from the generated sentences and the visual features from all segments within one event proposal as the input, and acts as the encoder to effectively summarize both semantic and visual information related to this event proposal. The second-stage LSTM network takes the output from the first-stage LSTM network and the visual features from all video segments within one event proposal as the input, and acts as the decoder to generate one descriptive sentence for this event proposal. Our comprehensive experiments on the ActivityNet Captions dataset demonstrate the effectiveness of our newly proposed DaS framework for dense video captioning.
Sharing, Teaching and Aligning: Knowledgeable Transfer Learning for Cross-Lingual Machine Reading Comprehension
Nov 12, 2023



In cross-lingual language understanding, machine translation is often utilized to enhance the transferability of models across languages, either by translating the training data from the source language to the target, or from the target to the source to aid inference. However, in cross-lingual machine reading comprehension (MRC), it is difficult to perform a deep level of assistance to enhance cross-lingual transfer because of the variation of answer span positions in different languages. In this paper, we propose X-STA, a new approach for cross-lingual MRC. Specifically, we leverage an attentive teacher to subtly transfer the answer spans of the source language to the answer output space of the target. A Gradient-Disentangled Knowledge Sharing technique is proposed as an improved cross-attention block. In addition, we force the model to learn semantic alignments from multiple granularities and calibrate the model outputs with teacher guidance to enhance cross-lingual transferability. Experiments on three multi-lingual MRC datasets show the effectiveness of our method, outperforming state-of-the-art approaches.
Query and Response Augmentation Cannot Help Out-of-domain Math Reasoning Generalization
Oct 09, 2023
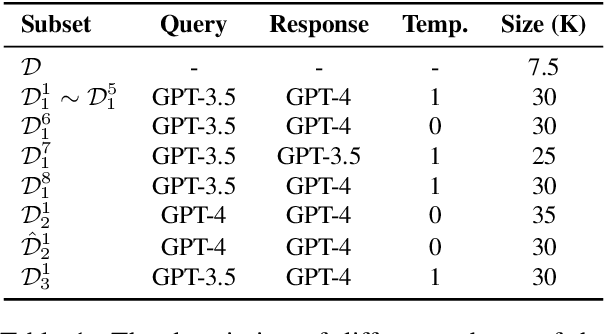
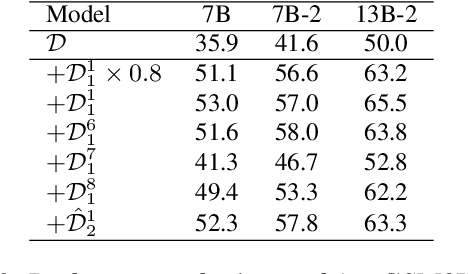
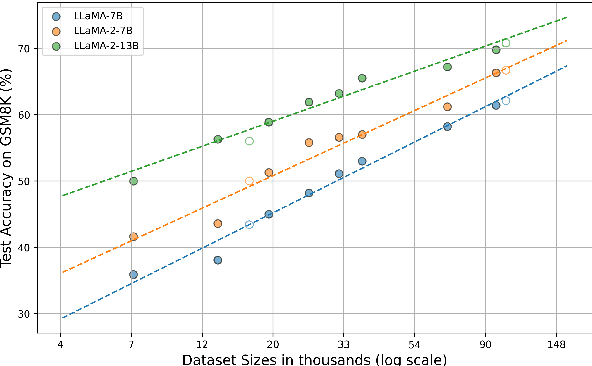
In math reasoning with large language models (LLMs), fine-tuning data augmentation by query evolution and diverse reasoning paths is empirically verified effective, profoundly narrowing the gap between open-sourced LLMs and cutting-edge proprietary LLMs. In this paper, we conduct an investigation for such data augmentation in math reasoning and are intended to answer: (1) What strategies of data augmentation are more effective; (2) What is the scaling relationship between the amount of augmented data and model performance; and (3) Can data augmentation incentivize generalization to out-of-domain mathematical reasoning tasks? To this end, we create a new dataset, AugGSM8K, by complicating and diversifying the queries from GSM8K and sampling multiple reasoning paths. We obtained a series of LLMs called MuggleMath by fine-tuning on subsets of AugGSM8K. MuggleMath substantially achieves new state-of-the-art on GSM8K (from 54% to 68.4% at the scale of 7B, and from 63.9% to 74.0% at the scale of 13B). A log-linear relationship is presented between MuggleMath's performance and the amount of augmented data. We also find that MuggleMath is weak in out-of-domain math reasoning generalization to MATH. This is attributed to the differences in query distribution between AugGSM8K and MATH which suggest that augmentation on a single benchmark could not help with overall math reasoning performance. Codes and AugGSM8K will be uploaded to https://github.com/OFA-Sys/gsm8k-ScRel.
Qwen Technical Report
Sep 28, 2023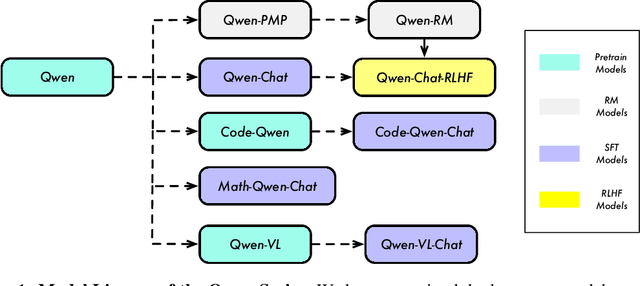

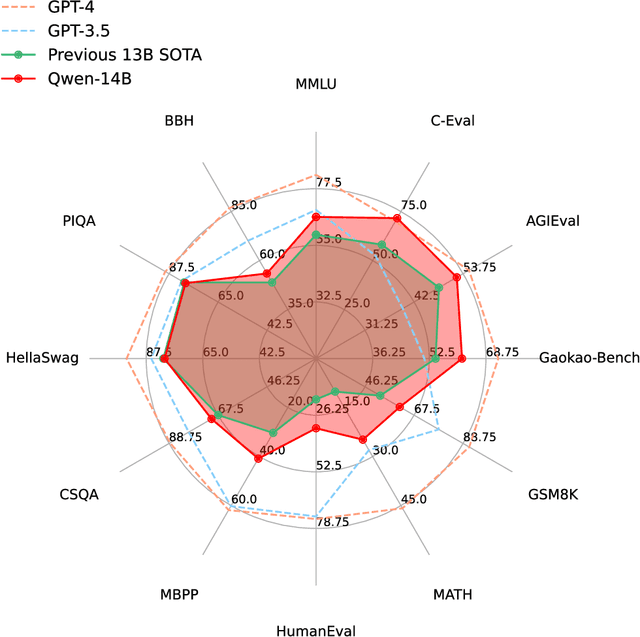
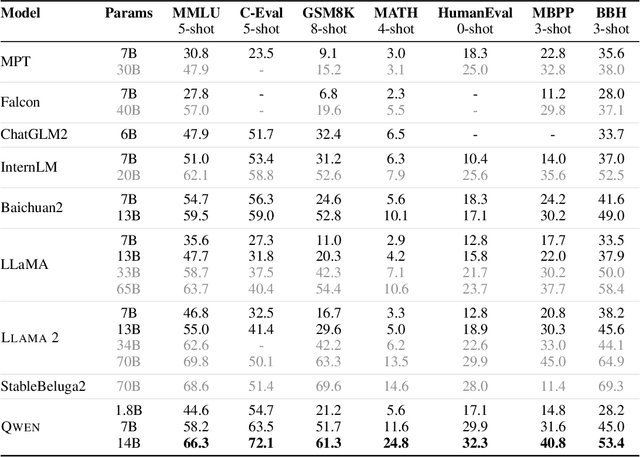
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
Boosting In-Context Learning with Factual Knowledge
Sep 26, 2023
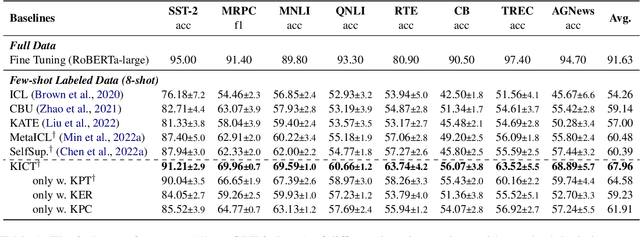
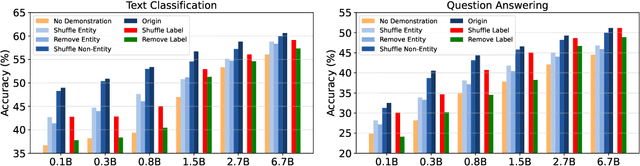
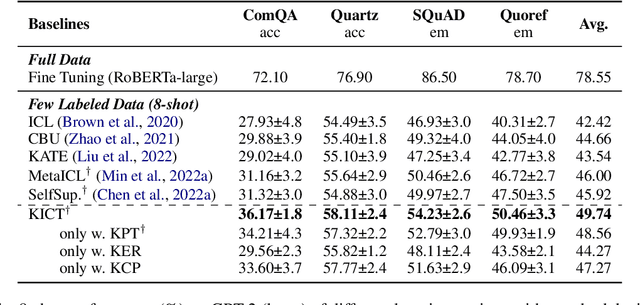
In-Context Learning (ICL) over Large language models (LLMs) aims at solving previously unseen tasks by conditioning on a few training examples, eliminating the need for parameter updates and achieving competitive performance. In this paper, we demonstrate that factual knowledge is imperative for the performance of ICL in three core facets, i.e., the inherent knowledge learned in LLMs, the factual knowledge derived from the selected in-context examples, and the knowledge biases in LLMs for output generation. To unleash the power of LLMs in few-shot learning scenarios, we introduce a novel Knowledgeable In-Context Tuning (KICT) framework to further improve the performance of ICL: 1) injecting factual knowledge to LLMs during continual self-supervised pre-training, 2) judiciously selecting the examples with high knowledge relevance, and 3) calibrating the prediction results based on prior knowledge. We evaluate the proposed approaches on auto-regressive LLMs (e.g., GPT-style models) over multiple text classification and question answering tasks. Experimental results demonstrate that KICT substantially outperforms strong baselines, and improves by more than 13% and 7% of accuracy on text classification and question answering tasks, respectively.
#InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models
Aug 15, 2023


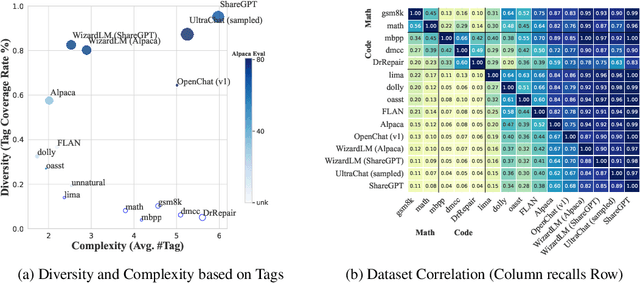
Foundation language models obtain the instruction-following ability through supervised fine-tuning (SFT). Diversity and complexity are considered critical factors of a successful SFT dataset, while their definitions remain obscure and lack quantitative analyses. In this work, we propose InsTag, an open-set fine-grained tagger, to tag samples within SFT datasets based on semantics and intentions and define instruction diversity and complexity regarding tags. We obtain 6.6K tags to describe comprehensive user queries. Then we analyze popular open-sourced SFT datasets and find that the model ability grows with more diverse and complex data. Based on this observation, we propose a data selector based on InsTag to select 6K diverse and complex samples from open-source datasets and fine-tune models on InsTag-selected data. The resulting models, TagLM, outperform open-source models based on considerably larger SFT data evaluated by MT-Bench, echoing the importance of query diversity and complexity. We open-source InsTag in https://github.com/OFA-Sys/InsTag.
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
Aug 03, 2023Mathematical reasoning is a challenging task for large language models (LLMs), while the scaling relationship of it with respect to LLM capacity is under-explored. In this paper, we investigate how the pre-training loss, supervised data amount, and augmented data amount influence the reasoning performances of a supervised LLM. We find that pre-training loss is a better indicator of the model's performance than the model's parameter count. We apply supervised fine-tuning (SFT) with different amounts of supervised data and empirically find a log-linear relation between data amount and model performance, and we find better models improve less with enlarged supervised datasets. To augment more data samples for improving model performances without any human effort, we propose to apply Rejection sampling Fine-Tuning (RFT). RFT uses supervised models to generate and collect correct reasoning paths as augmented fine-tuning datasets. We find with augmented samples containing more distinct reasoning paths, RFT improves mathematical reasoning performance more for LLMs. We also find RFT brings more improvement for less performant LLMs. Furthermore, we combine rejection samples from multiple models which push LLaMA-7B to an accuracy of 49.3% and outperforms the supervised fine-tuning (SFT) accuracy of 35.9% significantly.
Towards Adaptive Prefix Tuning for Parameter-Efficient Language Model Fine-tuning
May 24, 2023
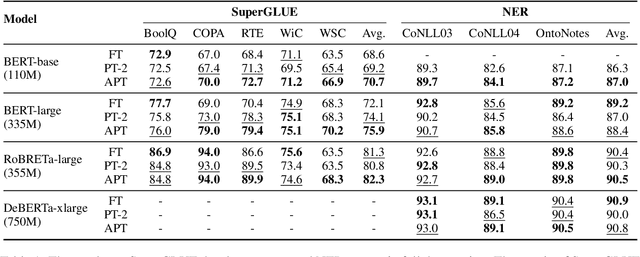
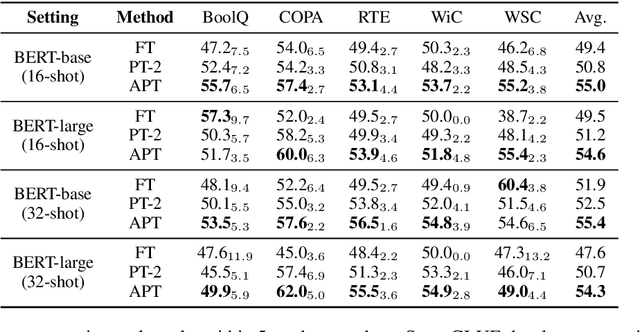
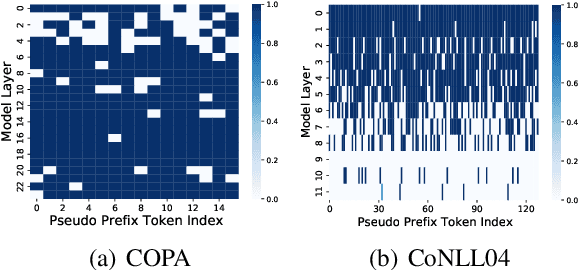
Fine-tuning large pre-trained language models on various downstream tasks with whole parameters is prohibitively expensive. Hence, Parameter-efficient fine-tuning has attracted attention that only optimizes a few task-specific parameters with the frozen pre-trained model. In this work, we focus on prefix tuning, which only optimizes continuous prefix vectors (i.e. pseudo tokens) inserted into Transformer layers. Based on the observation that the learned syntax and semantics representation varies a lot at different layers, we argue that the adaptive prefix will be further tailored to each layer than the fixed one, enabling the fine-tuning more effective and efficient. Thus, we propose Adaptive Prefix Tuning (APT) to adjust the prefix in terms of both fine-grained token level and coarse-grained layer level with a gate mechanism. Experiments on the SuperGLUE and NER datasets show the effectiveness of APT. In addition, taking the gate as a probing, we validate the efficiency and effectiveness of the variable prefix.
Knowledge Rumination for Pre-trained Language Models
May 15, 2023
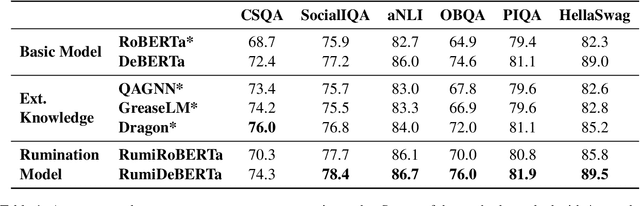


Previous studies have revealed that vanilla pre-trained language models (PLMs) lack the capacity to handle knowledge-intensive NLP tasks alone; thus, several works have attempted to integrate external knowledge into PLMs. However, despite the promising outcome, we empirically observe that PLMs may have already encoded rich knowledge in their pre-trained parameters but fails to fully utilize them when applying to knowledge-intensive tasks. In this paper, we propose a new paradigm dubbed Knowledge Rumination to help the pre-trained language model utilize those related latent knowledge without retrieving them from the external corpus. By simply adding a prompt like ``As far as I know'' to the PLMs, we try to review related latent knowledge and inject them back to the model for knowledge consolidation. We apply the proposed knowledge rumination to various language models, including RoBERTa, DeBERTa, GPT-3 and OPT. Experimental results on six commonsense reasoning tasks and GLUE benchmarks demonstrate the effectiveness of our proposed approach, which further proves that the knowledge stored in PLMs can be better exploited to enhance the downstream performance. Code will be available in https://github.com/zjunlp/knowledge-rumination.
VECO 2.0: Cross-lingual Language Model Pre-training with Multi-granularity Contrastive Learning
Apr 17, 2023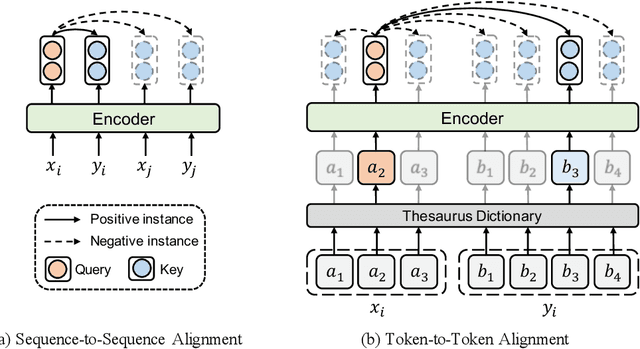
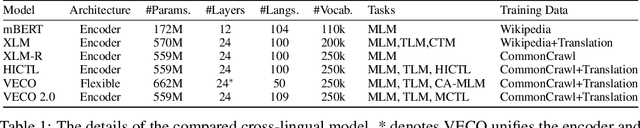
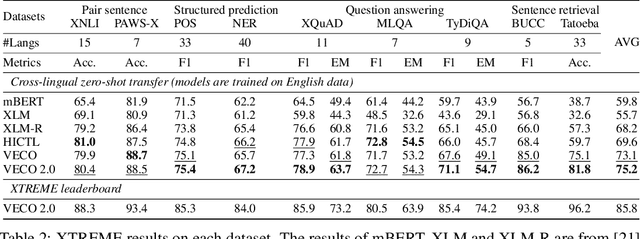
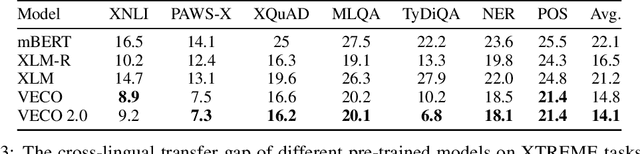
Recent studies have demonstrated the potential of cross-lingual transferability by training a unified Transformer encoder for multiple languages. In addition to involving the masked language model objective, existing cross-lingual pre-training works leverage sentence-level contrastive learning or plugs in extra cross-attention module to complement the insufficient capabilities of cross-lingual alignment. Nonetheless, synonym pairs residing in bilingual corpus are not exploited and aligned, which is more crucial than sentence interdependence establishment for token-level tasks. In this work, we propose a cross-lingual pre-trained model VECO~2.0 based on contrastive learning with multi-granularity alignments. Specifically, the sequence-to-sequence alignment is induced to maximize the similarity of the parallel pairs and minimize the non-parallel pairs. Then, token-to-token alignment is integrated to bridge the gap between synonymous tokens excavated via the thesaurus dictionary from the other unpaired tokens in a bilingual instance. Experiments show the effectiveness of the proposed strategy for cross-lingual model pre-training on the XTREME benchmark.