 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow vehicles change lanes after encountering crashes: Empirical analysis and modeling
Jan 13, 2026When a traffic crash occurs, following vehicles need to change lanes to bypass the obstruction. We define these maneuvers as post crash lane changes. In such scenarios, vehicles in the target lane may refuse to yield even after the lane change has already begun, increasing the complexity and crash risk of post crash LCs. However, the behavioral characteristics and motion patterns of post crash LCs remain unknown. To address this gap, we construct a post crash LC dataset by extracting vehicle trajectories from drone videos captured after crashes. Our empirical analysis reveals that, compared to mandatory LCs (MLCs) and discretionary LCs (DLCs), post crash LCs exhibit longer durations, lower insertion speeds, and higher crash risks. Notably, 79.4% of post crash LCs involve at least one instance of non yielding behavior from the new follower, compared to 21.7% for DLCs and 28.6% for MLCs. Building on these findings, we develop a novel trajectory prediction framework for post crash LCs. At its core is a graph based attention module that explicitly models yielding behavior as an auxiliary interaction aware task. This module is designed to guide both a conditional variational autoencoder and a Transformer based decoder to predict the lane changer's trajectory. By incorporating the interaction aware module, our model outperforms existing baselines in trajectory prediction performance by more than 10% in both average displacement error and final displacement error across different prediction horizons. Moreover, our model provides more reliable crash risk analysis by reducing false crash rates and improving conflict prediction accuracy. Finally, we validate the model's transferability using additional post crash LC datasets collected from different sites.
Power Consumption and Energy Efficiency of Mid-Band XL-MIMO: Modeling, Scaling Laws, and Performance Insights
Dec 14, 2025Mid-band extra-large-scale multiple-input multiple-output (XL-MIMO), emerging as a critical enabler for future communication systems, is expected to deliver significantly higher throughput by leveraging the extended bandwidth and enlarged antenna aperture. However, power consumption remains a significant concern due to the enlarged system dimension, underscoring the need for thorough investigations into efficient system design and deployment. To this end, an in-depth study is conducted on mid-band XL-MIMO systems. Specifically, a comprehensive power consumption model is proposed, encompassing the power consumption of major hardware components and signal processing procedures, while capturing the influence of key system parameters. Considering typical near-field propagation characteristics, closed-form approximations of throughput are derived, providing an analytical framework for assessing energy efficiency (EE). Based on the proposed framework, the scaling law of EE with respect to key system configurations is derived, offering valuable insights for system design. Subsequently, extensions and comparisons are conducted among representative multi-antenna technologies, demonstrating the superiority of mid-band XL-MIMO in EE. Extensive numerical results not only verify the tightness of the throughput analysis but also validate the EE evaluations, unveiling the potential of energy-efficient mid-band XL-MIMO systems.
A Trajectory-free Crash Detection Framework with Generative Approach and Segment Map Diffusion
Nov 17, 2025Real-time crash detection is essential for developing proactive safety management strategy and enhancing overall traffic efficiency. To address the limitations associated with trajectory acquisition and vehicle tracking, road segment maps recording the individual-level traffic dynamic data were directly served in crash detection. A novel two-stage trajectory-free crash detection framework, was present to generate the rational future road segment map and identify crashes. The first-stage diffusion-based segment map generation model, Mapfusion, conducts a noisy-to-normal process that progressively adds noise to the road segment map until the map is corrupted to pure Gaussian noise. The denoising process is guided by sequential embedding components capturing the temporal dynamics of segment map sequences. Furthermore, the generation model is designed to incorporate background context through ControlNet to enhance generation control. Crash detection is achieved by comparing the monitored segment map with the generations from diffusion model in second stage. Trained on non-crash vehicle motion data, Mapfusion successfully generates realistic road segment evolution maps based on learned motion patterns and remains robust across different sampling intervals. Experiments on real-world crashes indicate the effectiveness of the proposed two-stage method in accurately detecting crashes.
AI for Regulatory Affairs: Balancing Accuracy, Interpretability, and Computational Cost in Medical Device Classification
May 24, 2025Regulatory affairs, which sits at the intersection of medicine and law, can benefit significantly from AI-enabled automation. Classification task is the initial step in which manufacturers position their products to regulatory authorities, and it plays a critical role in determining market access, regulatory scrutiny, and ultimately, patient safety. In this study, we investigate a broad range of AI models -- including traditional machine learning (ML) algorithms, deep learning architectures, and large language models -- using a regulatory dataset of medical device descriptions. We evaluate each model along three key dimensions: accuracy, interpretability, and computational cost.
Extract the Best, Discard the Rest: CSI Feedback with Offline Large AI Models
May 13, 2025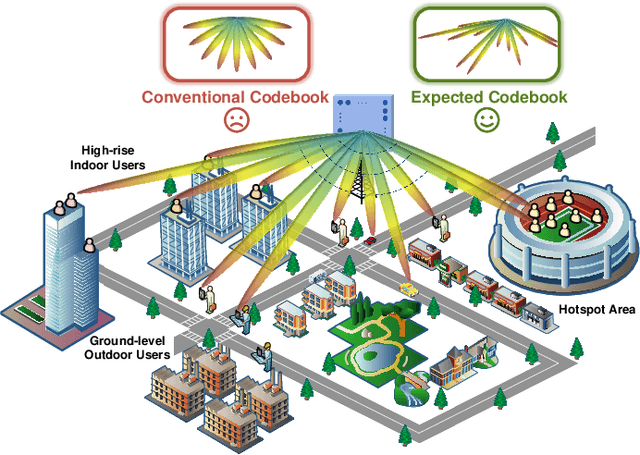
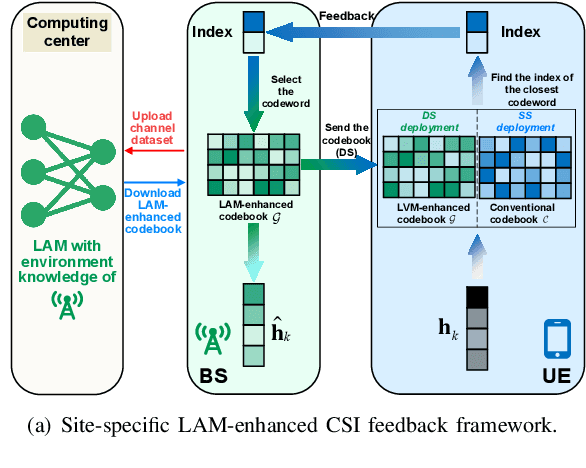
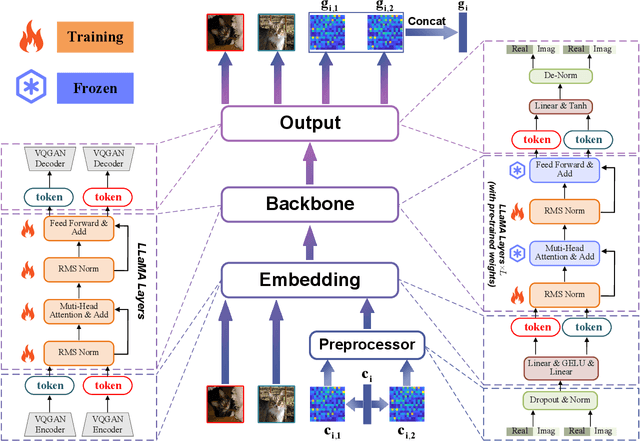
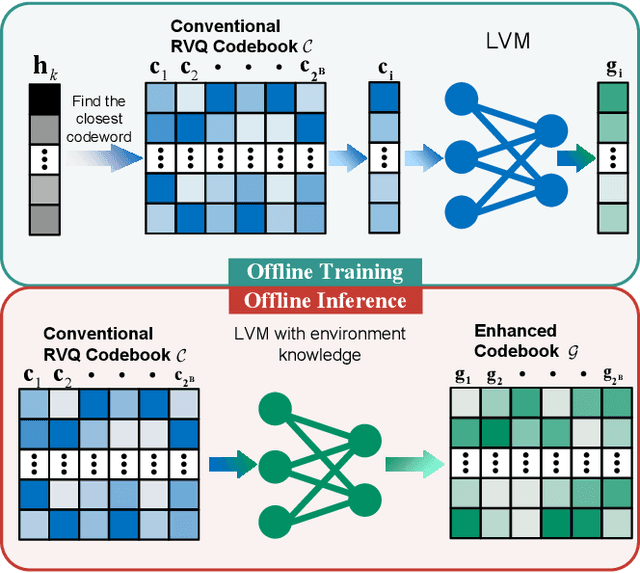
Large AI models (LAMs) have shown strong potential in wireless communication tasks, but their practical deployment remains hindered by latency and computational constraints. In this work, we focus on the challenge of integrating LAMs into channel state information (CSI) feedback for frequency-division duplex (FDD) massive multiple-intput multiple-output (MIMO) systems. To this end, we propose two offline frameworks, namely site-specific LAM-enhanced CSI feedback (SSLCF) and multi-scenario LAM-enhanced CSI feedback (MSLCF), that incorporate LAMs into the codebook-based CSI feedback paradigm without requiring real-time inference. Specifically, SSLCF generates a site-specific enhanced codebook through fine-tuning on locally collected CSI data, while MSLCF improves generalization by pre-generating a set of environment-aware codebooks. Both of these frameworks build upon the LAM with vision-based backbone, which is pre-trained on large-scale image datasets and fine-tuned with CSI data to generate customized codebooks. This resulting network named LVM4CF captures the structural similarity between CSI and image, allowing the LAM to refine codewords tailored to the specific environments. To optimize the codebook refinement capability of LVM4CF under both single- and dual-side deployment modes, we further propose corresponding training and inference algorithms. Simulation results show that our frameworks significantly outperform existing schemes in both reconstruction accuracy and system throughput, without introducing additional inference latency or computational overhead. These results also support the core design methodology of our proposed frameworks, extracting the best and discarding the rest, as a promising pathway for integrating LAMs into future wireless systems.
Toward Automated Regulatory Decision-Making: Trustworthy Medical Device Risk Classification with Multimodal Transformers and Self-Training
May 01, 2025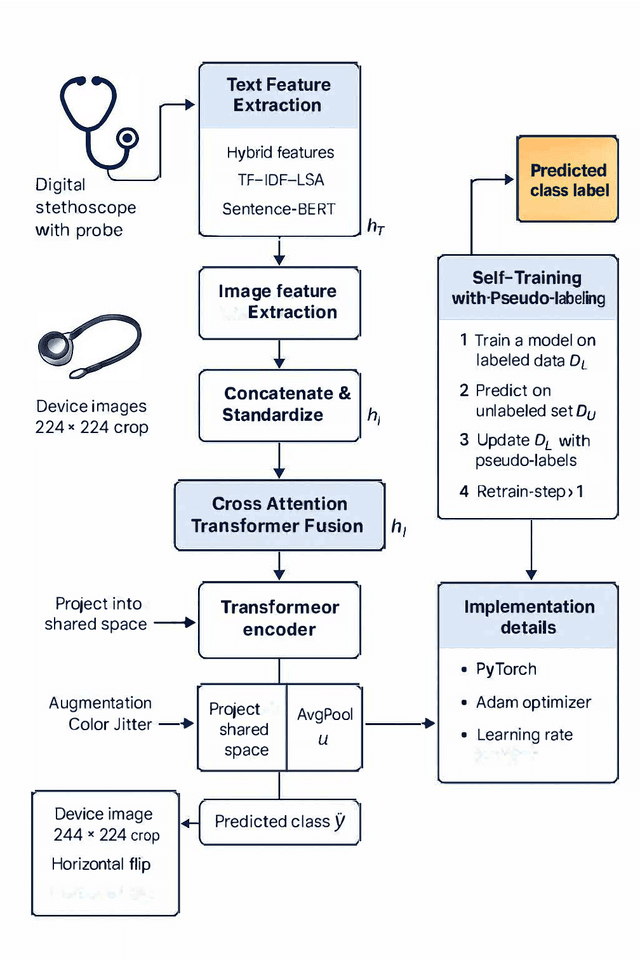



Accurate classification of medical device risk levels is essential for regulatory oversight and clinical safety. We present a Transformer-based multimodal framework that integrates textual descriptions and visual information to predict device regulatory classification. The model incorporates a cross-attention mechanism to capture intermodal dependencies and employs a self-training strategy for improved generalization under limited supervision. Experiments on a real-world regulatory dataset demonstrate that our approach achieves up to 90.4% accuracy and 97.9% AUROC, significantly outperforming text-only (77.2%) and image-only (54.8%) baselines. Compared to standard multimodal fusion, the self-training mechanism improved SVM performance by 3.3 percentage points in accuracy (from 87.1% to 90.4%) and 1.4 points in macro-F1, suggesting that pseudo-labeling can effectively enhance generalization under limited supervision. Ablation studies further confirm the complementary benefits of both cross-modal attention and self-training.
Distributed U6G ELAA Communication Systems: Channel Measurement and Small-Scale Fading Characterization
Apr 29, 2025The distributed upper 6 GHz (U6G) extra-large scale antenna array (ELAA) is a key enabler for future wireless communication systems, offering higher throughput and wider coverage, similar to existing ELAA systems, while effectively mitigating unaffordable complexity and hardware overhead. Uncertain channel characteristics, however, present significant bottleneck problems that hinder the hardware structure and algorithm design of the distributed U6G ELAA system. In response, we construct a U6G channel sounder and carry out extensive measurement campaigns across various typical scenarios. Initially, U6G channel characteristics, particularly small-scale fading characteristics, are unveiled and compared across different scenarios. Subsequently, the U6G ELAA channel characteristics are analyzed using a virtual array comprising 64 elements. Furthermore, inspired by the potential for distributed processing, we investigate U6G ELAA channel characteristics from the perspectives of subarrays and sub-bands, including subarray-wise nonstationarities, consistencies, far-field approximations, and sub-band characteristics. Through a combination of analysis and measurement validation, several insights and benefits, particularly suitable for distributed processing in U6G ELAA systems, are revealed, which provides practical validation for the deployment of U6G ELAA systems.
Keypoint Detection Empowered Near-Field User Localization and Channel Reconstruction
Jan 21, 2025In the near-field region of an extremely large-scale multiple-input multiple-output (XL MIMO) system, channel reconstruction is typically addressed through sparse parameter estimation based on compressed sensing (CS) algorithms after converting the received pilot signals into the transformed domain. However, the exhaustive search on the codebook in CS algorithms consumes significant computational resources and running time, particularly when a large number of antennas are equipped at the base station (BS). To overcome this challenge, we propose a novel scheme to replace the high-cost exhaustive search procedure. We visualize the sparse channel matrix in the transformed domain as a channel image and design the channel keypoint detection network (CKNet) to locate the user and scatterers in high speed. Subsequently, we use a small-scale newtonized orthogonal matching pursuit (NOMP) based refiner to further enhance the precision. Our method is applicable to both the Cartesian domain and the Polar domain. Additionally, to deal with scenarios with a flexible number of propagation paths, we further design FlexibleCKNet to predict both locations and confidence scores. Our experimental results validate that the CKNet and FlexibleCKNet-empowered channel reconstruction scheme can significantly reduce the computational complexity while maintaining high accuracy in both user and scatterer localization and channel reconstruction tasks.
ViPOcc: Leveraging Visual Priors from Vision Foundation Models for Single-View 3D Occupancy Prediction
Dec 15, 2024Inferring the 3D structure of a scene from a single image is an ill-posed and challenging problem in the field of vision-centric autonomous driving. Existing methods usually employ neural radiance fields to produce voxelized 3D occupancy, lacking instance-level semantic reasoning and temporal photometric consistency. In this paper, we propose ViPOcc, which leverages the visual priors from vision foundation models (VFMs) for fine-grained 3D occupancy prediction. Unlike previous works that solely employ volume rendering for RGB and depth image reconstruction, we introduce a metric depth estimation branch, in which an inverse depth alignment module is proposed to bridge the domain gap in depth distribution between VFM predictions and the ground truth. The recovered metric depth is then utilized in temporal photometric alignment and spatial geometric alignment to ensure accurate and consistent 3D occupancy prediction. Additionally, we also propose a semantic-guided non-overlapping Gaussian mixture sampler for efficient, instance-aware ray sampling, which addresses the redundant and imbalanced sampling issue that still exists in previous state-of-the-art methods. Extensive experiments demonstrate the superior performance of ViPOcc in both 3D occupancy prediction and depth estimation tasks on the KITTI-360 and KITTI Raw datasets. Our code is available at: \url{https://mias.group/ViPOcc}.
Regulator-Manufacturer AI Agents Modeling: Mathematical Feedback-Driven Multi-Agent LLM Framework
Nov 22, 2024



The increasing complexity of regulatory updates from global authorities presents significant challenges for medical device manufacturers, necessitating agile strategies to sustain compliance and maintain market access. Concurrently, regulatory bodies must effectively monitor manufacturers' responses and develop strategic surveillance plans. This study employs a multi-agent modeling approach, enhanced with Large Language Models (LLMs), to simulate regulatory dynamics and examine the adaptive behaviors of key actors, including regulatory bodies, manufacturers, and competitors. These agents operate within a simulated environment governed by regulatory flow theory, capturing the impacts of regulatory changes on compliance decisions, market adaptation, and innovation strategies. Our findings illuminate the influence of regulatory shifts on industry behaviour and identify strategic opportunities for improving regulatory practices, optimizing compliance, and fostering innovation. By leveraging the integration of multi-agent systems and LLMs, this research provides a novel perspective and offers actionable insights for stakeholders navigating the evolving regulatory landscape of the medical device industry.