 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeaiXcoder-7B: A Lightweight and Effective Large Language Model for Code Completion
Oct 17, 2024


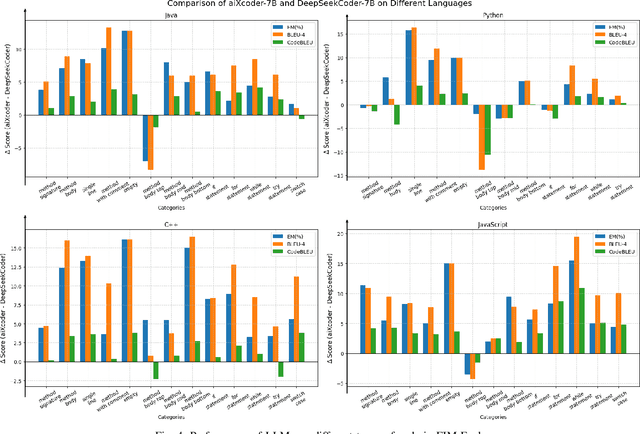
Large Language Models (LLMs) have been widely used in code completion, and researchers are focusing on scaling up LLMs to improve their accuracy. However, larger LLMs will increase the response time of code completion and decrease the developers' productivity. In this paper, we propose a lightweight and effective LLM for code completion named aiXcoder-7B. Compared to existing LLMs, aiXcoder-7B achieves higher code completion accuracy while having smaller scales (i.e., 7 billion parameters). We attribute the superiority of aiXcoder-7B to three key factors: (1) Multi-objective training. We employ three training objectives, one of which is our proposed Structured Fill-In-the-Middle (SFIM). SFIM considers the syntax structures in code and effectively improves the performance of LLMs for code. (2) Diverse data sampling strategies. They consider inter-file relationships and enhance the capability of LLMs in understanding cross-file contexts. (3) Extensive high-quality data. We establish a rigorous data collection pipeline and consume a total of 1.2 trillion unique tokens for training aiXcoder-7B. This vast volume of data enables aiXcoder-7B to learn a broad distribution of code. We evaluate aiXcoder-7B in five popular code completion benchmarks and a new benchmark collected by this paper. The results show that aiXcoder-7B outperforms the latest six LLMs with similar sizes and even surpasses four larger LLMs (e.g., StarCoder2-15B and CodeLlama-34B), positioning aiXcoder-7B as a lightweight and effective LLM for academia and industry. Finally, we summarize three valuable insights for helping practitioners train the next generations of LLMs for code. aiXcoder-7B has been open-souced and gained significant attention. As of the submission date, aiXcoder-7B has received 2,193 GitHub Stars.
MLoRA: Multi-Domain Low-Rank Adaptive Network for CTR Prediction
Aug 14, 2024



Click-through rate (CTR) prediction is one of the fundamental tasks in the industry, especially in e-commerce, social media, and streaming media. It directly impacts website revenues, user satisfaction, and user retention. However, real-world production platforms often encompass various domains to cater for diverse customer needs. Traditional CTR prediction models struggle in multi-domain recommendation scenarios, facing challenges of data sparsity and disparate data distributions across domains. Existing multi-domain recommendation approaches introduce specific-domain modules for each domain, which partially address these issues but often significantly increase model parameters and lead to insufficient training. In this paper, we propose a Multi-domain Low-Rank Adaptive network (MLoRA) for CTR prediction, where we introduce a specialized LoRA module for each domain. This approach enhances the model's performance in multi-domain CTR prediction tasks and is able to be applied to various deep-learning models. We evaluate the proposed method on several multi-domain datasets. Experimental results demonstrate our MLoRA approach achieves a significant improvement compared with state-of-the-art baselines. Furthermore, we deploy it in the production environment of the Alibaba.COM. The online A/B testing results indicate the superiority and flexibility in real-world production environments. The code of our MLoRA is publicly available.
Modeling User Intent Beyond Trigger: Incorporating Uncertainty for Trigger-Induced Recommendation
Aug 07, 2024



To cater to users' desire for an immersive browsing experience, numerous e-commerce platforms provide various recommendation scenarios, with a focus on Trigger-Induced Recommendation (TIR) tasks. However, the majority of current TIR methods heavily rely on the trigger item to understand user intent, lacking a higher-level exploration and exploitation of user intent (e.g., popular items and complementary items), which may result in an overly convergent understanding of users' short-term intent and can be detrimental to users' long-term purchasing experiences. Moreover, users' short-term intent shows uncertainty and is affected by various factors such as browsing context and historical behaviors, which poses challenges to user intent modeling. To address these challenges, we propose a novel model called Deep Uncertainty Intent Network (DUIN), comprising three essential modules: i) Explicit Intent Exploit Module extracting explicit user intent using the contrastive learning paradigm; ii) Latent Intent Explore Module exploring latent user intent by leveraging the multi-view relationships between items; iii) Intent Uncertainty Measurement Module offering a distributional estimation and capturing the uncertainty associated with user intent. Experiments on three real-world datasets demonstrate the superior performance of DUIN compared to existing baselines. Notably, DUIN has been deployed across all TIR scenarios in our e-commerce platform, with online A/B testing results conclusively validating its superiority.
Robust Interaction-based Relevance Modeling for Online E-Commerce and LLM-based Retrieval
Jun 04, 2024Semantic relevance calculation is crucial for e-commerce search engines, as it ensures that the items selected closely align with customer intent. Inadequate attention to this aspect can detrimentally affect user experience and engagement. Traditional text-matching techniques are prevalent but often fail to capture the nuances of search intent accurately, so neural networks now have become a preferred solution to processing such complex text matching. Existing methods predominantly employ representation-based architectures, which strike a balance between high traffic capacity and low latency. However, they exhibit significant shortcomings in generalization and robustness when compared to interaction-based architectures. In this work, we introduce a robust interaction-based modeling paradigm to address these shortcomings. It encompasses 1) a dynamic length representation scheme for expedited inference, 2) a professional terms recognition method to identify subjects and core attributes from complex sentence structures, and 3) a contrastive adversarial training protocol to bolster the model's robustness and matching capabilities. Extensive offline evaluations demonstrate the superior robustness and effectiveness of our approach, and online A/B testing confirms its ability to improve relevance in the same exposure position, resulting in more clicks and conversions. To the best of our knowledge, this method is the first interaction-based approach for large e-commerce search relevance calculation. Notably, we have deployed it for the entire search traffic on alibaba.com, the largest B2B e-commerce platform in the world.
General2Specialized LLMs Translation for E-commerce
Mar 06, 2024Existing Neural Machine Translation (NMT) models mainly handle translation in the general domain, while overlooking domains with special writing formulas, such as e-commerce and legal documents. Taking e-commerce as an example, the texts usually include amounts of domain-related words and have more grammar problems, which leads to inferior performances of current NMT methods. To address these problems, we collect two domain-related resources, including a set of term pairs (aligned Chinese-English bilingual terms) and a parallel corpus annotated for the e-commerce domain. Furthermore, we propose a two-step fine-tuning paradigm (named G2ST) with self-contrastive semantic enhancement to transfer one general NMT model to the specialized NMT model for e-commerce. The paradigm can be used for the NMT models based on Large language models (LLMs). Extensive evaluations on real e-commerce titles demonstrate the superior translation quality and robustness of our G2ST approach, as compared with state-of-the-art NMT models such as LLaMA, Qwen, GPT-3.5, and even GPT-4.
On Practical Diversified Recommendation with Controllable Category Diversity Framework
Feb 06, 2024



Recommender systems have made significant strides in various industries, primarily driven by extensive efforts to enhance recommendation accuracy. However, this pursuit of accuracy has inadvertently given rise to echo chamber/filter bubble effects. Especially in industry, it could impair user's experiences and prevent user from accessing a wider range of items. One of the solutions is to take diversity into account. However, most of existing works focus on user's explicit preferences, while rarely exploring user's non-interaction preferences. These neglected non-interaction preferences are especially important for broadening user's interests in alleviating echo chamber/filter bubble effects.Therefore, in this paper, we first define diversity as two distinct definitions, i.e., user-explicit diversity (U-diversity) and user-item non-interaction diversity (N-diversity) based on user historical behaviors. Then, we propose a succinct and effective method, named as Controllable Category Diversity Framework (CCDF) to achieve both high U-diversity and N-diversity simultaneously.Specifically, CCDF consists of two stages, User-Category Matching and Constrained Item Matching. The User-Category Matching utilizes the DeepU2C model and a combined loss to capture user's preferences in categories, and then selects the top-$K$ categories with a controllable parameter $K$.These top-$K$ categories will be used as trigger information in Constrained Item Matching. Offline experimental results show that our proposed DeepU2C outperforms state-of-the-art diversity-oriented methods, especially on N-diversity task. The whole framework is validated in a real-world production environment by conducting online A/B testing.
* A Two-stage Controllable Category Diversity Framework for Recommendation
Deep Evolutional Instant Interest Network for CTR Prediction in Trigger-Induced Recommendation
Jan 17, 2024



The recommendation has been playing a key role in many industries, e.g., e-commerce, streaming media, social media, etc. Recently, a new recommendation scenario, called Trigger-Induced Recommendation (TIR), where users are able to explicitly express their instant interests via trigger items, is emerging as an essential role in many e-commerce platforms, e.g., Alibaba.com and Amazon. Without explicitly modeling the user's instant interest, traditional recommendation methods usually obtain sub-optimal results in TIR. Even though there are a few methods considering the trigger and target items simultaneously to solve this problem, they still haven't taken into account temporal information of user behaviors, the dynamic change of user instant interest when the user scrolls down and the interactions between the trigger and target items. To tackle these problems, we propose a novel method -- Deep Evolutional Instant Interest Network (DEI2N), for click-through rate prediction in TIR scenarios. Specifically, we design a User Instant Interest Modeling Layer to predict the dynamic change of the intensity of instant interest when the user scrolls down. Temporal information is utilized in user behavior modeling. Moreover, an Interaction Layer is introduced to learn better interactions between the trigger and target items. We evaluate our method on several offline and real-world industrial datasets. Experimental results show that our proposed DEI2N outperforms state-of-the-art baselines. In addition, online A/B testing demonstrates the superiority over the existing baseline in real-world production environments.
EdgeNet : Encoder-decoder generative Network for Auction Design in E-commerce Online Advertising
May 09, 2023


We present a new encoder-decoder generative network dubbed EdgeNet, which introduces a novel encoder-decoder framework for data-driven auction design in online e-commerce advertising. We break the neural auction paradigm of Generalized-Second-Price(GSP), and improve the utilization efficiency of data while ensuring the economic characteristics of the auction mechanism. Specifically, EdgeNet introduces a transformer-based encoder to better capture the mutual influence among different candidate advertisements. In contrast to GSP based neural auction model, we design an autoregressive decoder to better utilize the rich context information in online advertising auctions. EdgeNet is conceptually simple and easy to extend to the existing end-to-end neural auction framework. We validate the efficiency of EdgeNet on a wide range of e-commercial advertising auction, demonstrating its potential in improving user experience and platform revenue.
Unified Vision-Language Representation Modeling for E-Commerce Same-Style Products Retrieval
Feb 20, 2023Same-style products retrieval plays an important role in e-commerce platforms, aiming to identify the same products which may have different text descriptions or images. It can be used for similar products retrieval from different suppliers or duplicate products detection of one supplier. Common methods use the image as the detected object, but they only consider the visual features and overlook the attribute information contained in the textual descriptions, and perform weakly for products in image less important industries like machinery, hardware tools and electronic component, even if an additional text matching module is added. In this paper, we propose a unified vision-language modeling method for e-commerce same-style products retrieval, which is designed to represent one product with its textual descriptions and visual contents. It contains one sampling skill to collect positive pairs from user click log with category and relevance constrained, and a novel contrastive loss unit to model the image, text, and image+text representations into one joint embedding space. It is capable of cross-modal product-to-product retrieval, as well as style transfer and user-interactive search. Offline evaluations on annotated data demonstrate its superior retrieval performance, and online testings show it can attract more clicks and conversions. Moreover, this model has already been deployed online for similar products retrieval in alibaba.com, the largest B2B e-commerce platform in the world.