 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning How Much to Think: Difficulty-Aware Dynamic MoEs for Graph Node Classification
Apr 13, 2026Mixture-of-Experts (MoE) architectures offer a scalable path for Graph Neural Networks (GNNs) in node classification tasks but typically rely on static and rigid routing strategies that enforce a uniform expert budget or coarse-grained expert toggles on all nodes. This limitation overlooks the varying discriminative difficulty of nodes and leads to under-fitting for hard nodes and redundant computation for easy ones. To resolve this issue, we propose D2MoE, a novel framework that shifts the focus from static expert selection to node-wise expert resource allocation. By using predictive entropy as a real-time proxy for difficulty, D2MoE employs a difficulty-driven top-p routing mechanism to adaptively concentrate expert resources on hard nodes while reducing overhead for easy ones, achieving continuous and fine-grained expert budget scaling for node classification. Experiments on 13 benchmarks demonstrate that D2MoE achieves consistent state-of-the-art performance, surpassing leading baselines by up to 7.92% in accuracy on heterophilous graphs. Notably, on large-scale graphs, it reduces memory consumption by up to 73.07% and training time by 46.53% compared to the best-performing Graph MoE, thereby validating its superior efficiency.
CrossHGL: A Text-Free Foundation Model for Cross-Domain Heterogeneous Graph Learning
Mar 29, 2026Heterogeneous graph representation learning (HGRL) is essential for modeling complex systems with diverse node and edge types. However, most existing methods are limited to closed-world settings with shared schemas and feature spaces, hindering cross-domain generalization. While recent graph foundation models improve transferability, they often target homogeneous graphs, rely on domain-specific schemas, or require rich textual attributes. Consequently, text-free and few-shot cross-domain HGRL remains underexplored. To address this, we propose CrossHGL, a foundation framework that preserves and transfers multi-relational structural semantics without external textual supervision. Specifically, a semantic-preserving transformation strategy homogenizes heterogeneous graphs while encoding interaction semantics into edge features. Based on this, a prompt-aware multi-domain pre-training framework with a Tri-Prompt mechanism captures transferable knowledge across feature, edge, and structure perspectives via self-supervised contrastive learning. For target-domain adaptation, we develop a parameter-efficient fine-tuning strategy that freezes the pre-trained backbone and performs few-shot classification via prompt composition and prototypical learning. Experiments on node-level and graph-level tasks show that CrossHGL consistently outperforms state-of-the-art baselines, yielding average relative improvements of 25.1% and 7.6% in Micro-F1 for node and graph classification, respectively, while remaining competitive in challenging feature-degenerated settings.
Adaptive Substructure-Aware Expert Model for Molecular Property Prediction
Apr 08, 2025Molecular property prediction is essential for applications such as drug discovery and toxicity assessment. While Graph Neural Networks (GNNs) have shown promising results by modeling molecules as molecular graphs, their reliance on data-driven learning limits their ability to generalize, particularly in the presence of data imbalance and diverse molecular substructures. Existing methods often overlook the varying contributions of different substructures to molecular properties, treating them uniformly. To address these challenges, we propose ASE-Mol, a novel GNN-based framework that leverages a Mixture-of-Experts (MoE) approach for molecular property prediction. ASE-Mol incorporates BRICS decomposition and significant substructure awareness to dynamically identify positive and negative substructures. By integrating a MoE architecture, it reduces the adverse impact of negative motifs while improving adaptability to positive motifs. Experimental results on eight benchmark datasets demonstrate that ASE-Mol achieves state-of-the-art performance, with significant improvements in both accuracy and interpretability.
Unveiling Latent Information in Transaction Hashes: Hypergraph Learning for Ethereum Ponzi Scheme Detection
Mar 27, 2025With the widespread adoption of Ethereum, financial frauds such as Ponzi schemes have become increasingly rampant in the blockchain ecosystem, posing significant threats to the security of account assets. Existing Ethereum fraud detection methods typically model account transactions as graphs, but this approach primarily focuses on binary transactional relationships between accounts, failing to adequately capture the complex multi-party interaction patterns inherent in Ethereum. To address this, we propose a hypergraph modeling method for the Ponzi scheme detection method in Ethereum, called HyperDet. Specifically, we treat transaction hashes as hyperedges that connect all the relevant accounts involved in a transaction. Additionally, we design a two-step hypergraph sampling strategy to significantly reduce computational complexity. Furthermore, we introduce a dual-channel detection module, including the hypergraph detection channel and the hyper-homo graph detection channel, to be compatible with existing detection methods. Experimental results show that, compared to traditional homogeneous graph-based methods, the hyper-homo graph detection channel achieves significant performance improvements, demonstrating the superiority of hypergraph in Ponzi scheme detection. This research offers innovations for modeling complex relationships in blockchain data.
Instruction-Aligned Visual Attention for Mitigating Hallucinations in Large Vision-Language Models
Mar 24, 2025Despite the significant success of Large Vision-Language models(LVLMs), these models still suffer hallucinations when describing images, generating answers that include non-existent objects. It is reported that these models tend to over-focus on certain irrelevant image tokens that do not contain critical information for answering the question and distort the output. To address this, we propose an Instruction-Aligned Visual Attention(IAVA) approach, which identifies irrelevant tokens by comparing changes in attention weights under two different instructions. By applying contrastive decoding, we dynamically adjust the logits generated from original image tokens and irrelevant image tokens, reducing the model's over-attention to irrelevant information. The experimental results demonstrate that IAVA consistently outperforms existing decoding techniques on benchmarks such as MME, POPE, and TextVQA in mitigating object hallucinations. Our IAVA approach is available online at https://github.com/Lee-lab558/IAVA.
Mixture of Decoupled Message Passing Experts with Entropy Constraint for General Node Classification
Feb 12, 2025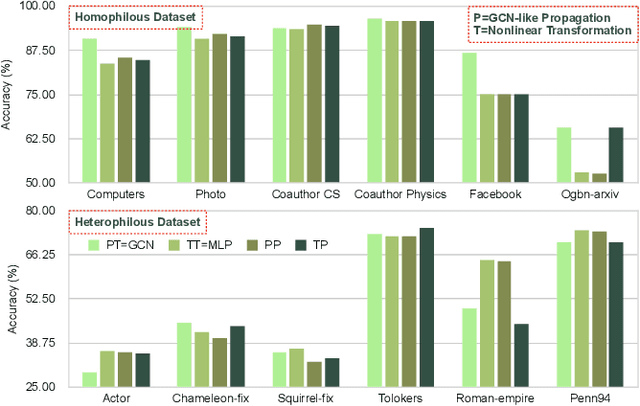

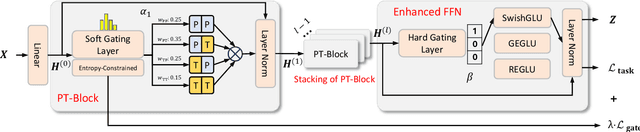
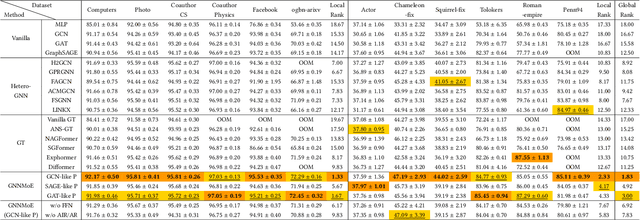
The varying degrees of homophily and heterophily in real-world graphs persistently constrain the universality of graph neural networks (GNNs) for node classification. Adopting a data-centric perspective, this work reveals an inherent preference of different graphs towards distinct message encoding schemes: homophilous graphs favor local propagation, while heterophilous graphs exhibit preference for flexible combinations of propagation and transformation. To address this, we propose GNNMoE, a universal node classification framework based on the Mixture-of-Experts (MoE) mechanism. The framework first constructs diverse message-passing experts through recombination of fine-grained encoding operators, then designs soft and hard gating layers to allocate the most suitable expert networks for each node's representation learning, thereby enhancing both model expressiveness and adaptability to diverse graphs. Furthermore, considering that soft gating might introduce encoding noise in homophilous scenarios, we introduce an entropy constraint to guide sharpening of soft gates, achieving organic integration of weighted combination and Top-K selection. Extensive experiments demonstrate that GNNMoE significantly outperforms mainstream GNNs, heterophilous GNNs, and graph transformers in both node classification performance and universality across diverse graph datasets.
Efficient Parallel Genetic Algorithm for Perturbed Substructure Optimization in Complex Network
Dec 30, 2024



Evolutionary computing, particularly genetic algorithm (GA), is a combinatorial optimization method inspired by natural selection and the transmission of genetic information, which is widely used to identify optimal solutions to complex problems through simulated programming and iteration. Due to its strong adaptability, flexibility, and robustness, GA has shown significant performance and potentiality on perturbed substructure optimization (PSSO), an important graph mining problem that achieves its goals by modifying network structures. However, the efficiency and practicality of GA-based PSSO face enormous challenges due to the complexity and diversity of application scenarios. While some research has explored acceleration frameworks in evolutionary computing, their performance on PSSO remains limited due to a lack of scenario generalizability. Based on these, this paper is the first to present the GA-based PSSO Acceleration framework (GAPA), which simplifies the GA development process and supports distributed acceleration. Specifically, it reconstructs the genetic operation and designs a development framework for efficient parallel acceleration. Meanwhile, GAPA includes an extensible library that optimizes and accelerates 10 PSSO algorithms, covering 4 crucial tasks for graph mining. Comprehensive experiments on 18 datasets across 4 tasks and 10 algorithms effectively demonstrate the superiority of GAPA, achieving an average of 4x the acceleration of Evox. The repository is in https://github.com/NetAlsGroup/GAPA.
CoF: Coarse to Fine-Grained Image Understanding for Multi-modal Large Language Models
Dec 22, 2024



The impressive performance of Large Language Model (LLM) has prompted researchers to develop Multi-modal LLM (MLLM), which has shown great potential for various multi-modal tasks. However, current MLLM often struggles to effectively address fine-grained multi-modal challenges. We argue that this limitation is closely linked to the models' visual grounding capabilities. The restricted spatial awareness and perceptual acuity of visual encoders frequently lead to interference from irrelevant background information in images, causing the models to overlook subtle but crucial details. As a result, achieving fine-grained regional visual comprehension becomes difficult. In this paper, we break down multi-modal understanding into two stages, from Coarse to Fine (CoF). In the first stage, we prompt the MLLM to locate the approximate area of the answer. In the second stage, we further enhance the model's focus on relevant areas within the image through visual prompt engineering, adjusting attention weights of pertinent regions. This, in turn, improves both visual grounding and overall performance in downstream tasks. Our experiments show that this approach significantly boosts the performance of baseline models, demonstrating notable generalization and effectiveness. Our CoF approach is available online at https://github.com/Gavin001201/CoF.
Mixture of Experts Meets Decoupled Message Passing: Towards General and Adaptive Node Classification
Dec 11, 2024


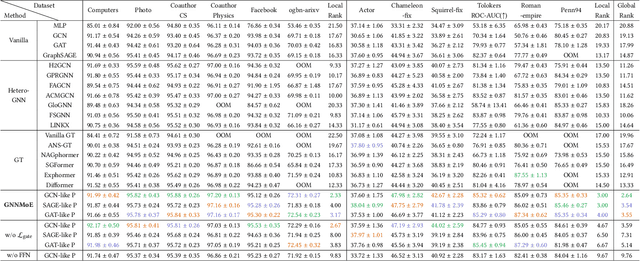
Graph neural networks excel at graph representation learning but struggle with heterophilous data and long-range dependencies. And graph transformers address these issues through self-attention, yet face scalability and noise challenges on large-scale graphs. To overcome these limitations, we propose GNNMoE, a universal model architecture for node classification. This architecture flexibly combines fine-grained message-passing operations with a mixture-of-experts mechanism to build feature encoding blocks. Furthermore, by incorporating soft and hard gating layers to assign the most suitable expert networks to each node, we enhance the model's expressive power and adaptability to different graph types. In addition, we introduce adaptive residual connections and an enhanced FFN module into GNNMoE, further improving the expressiveness of node representation. Extensive experimental results demonstrate that GNNMoE performs exceptionally well across various types of graph data, effectively alleviating the over-smoothing issue and global noise, enhancing model robustness and adaptability, while also ensuring computational efficiency on large-scale graphs.
Lateral Movement Detection via Time-aware Subgraph Classification on Authentication Logs
Nov 15, 2024Lateral movement is a crucial component of advanced persistent threat (APT) attacks in networks. Attackers exploit security vulnerabilities in internal networks or IoT devices, expanding their control after initial infiltration to steal sensitive data or carry out other malicious activities, posing a serious threat to system security. Existing research suggests that attackers generally employ seemingly unrelated operations to mask their malicious intentions, thereby evading existing lateral movement detection methods and hiding their intrusion traces. In this regard, we analyze host authentication log data from a graph perspective and propose a multi-scale lateral movement detection framework called LMDetect. The main workflow of this framework proceeds as follows: 1) Construct a heterogeneous multigraph from host authentication log data to strengthen the correlations among internal system entities; 2) Design a time-aware subgraph generator to extract subgraphs centered on authentication events from the heterogeneous authentication multigraph; 3) Design a multi-scale attention encoder that leverages both local and global attention to capture hidden anomalous behavior patterns in the authentication subgraphs, thereby achieving lateral movement detection. Extensive experiments on two real-world authentication log datasets demonstrate the effectiveness and superiority of our framework in detecting lateral movement behaviors.