 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocuments Are People and Words Are Items: A Psychometric Approach to Textual Data with Contextual Embeddings
Sep 10, 2025This research introduces a novel psychometric method for analyzing textual data using large language models. By leveraging contextual embeddings to create contextual scores, we transform textual data into response data suitable for psychometric analysis. Treating documents as individuals and words as items, this approach provides a natural psychometric interpretation under the assumption that certain keywords, whose contextual meanings vary significantly across documents, can effectively differentiate documents within a corpus. The modeling process comprises two stages: obtaining contextual scores and performing psychometric analysis. In the first stage, we utilize natural language processing techniques and encoder based transformer models to identify common keywords and generate contextual scores. In the second stage, we employ various types of factor analysis, including exploratory and bifactor models, to extract and define latent factors, determine factor correlations, and identify the most significant words associated with each factor. Applied to the Wiki STEM corpus, our experimental results demonstrate the method's potential to uncover latent knowledge dimensions and patterns within textual data. This approach not only enhances the psychometric analysis of textual data but also holds promise for applications in fields rich in textual information, such as education, psychology, and law.
Each to Their Own: Exploring the Optimal Embedding in RAG
Jul 23, 2025Recently, as Large Language Models (LLMs) have fundamentally impacted various fields, the methods for incorporating up-to-date information into LLMs or adding external knowledge to construct domain-specific models have garnered wide attention. Retrieval-Augmented Generation (RAG), serving as an inference-time scaling method, is notable for its low cost and minimal effort for parameter tuning. However, due to heterogeneous training data and model architecture, the variant embedding models used in RAG exhibit different benefits across various areas, often leading to different similarity calculation results and, consequently, varying response quality from LLMs. To address this problem, we propose and examine two approaches to enhance RAG by combining the benefits of multiple embedding models, named Mixture-Embedding RAG and Confident RAG. Mixture-Embedding RAG simply sorts and selects retrievals from multiple embedding models based on standardized similarity; however, it does not outperform vanilla RAG. In contrast, Confident RAG generates responses multiple times using different embedding models and then selects the responses with the highest confidence level, demonstrating average improvements of approximately 10% and 5% over vanilla LLMs and RAG, respectively. The consistent results across different LLMs and embedding models indicate that Confident RAG is an efficient plug-and-play approach for various domains. We will release our code upon publication.
DAM-GT: Dual Positional Encoding-Based Attention Masking Graph Transformer for Node Classification
May 23, 2025Neighborhood-aware tokenized graph Transformers have recently shown great potential for node classification tasks. Despite their effectiveness, our in-depth analysis of neighborhood tokens reveals two critical limitations in the existing paradigm. First, current neighborhood token generation methods fail to adequately capture attribute correlations within a neighborhood. Second, the conventional self-attention mechanism suffers from attention diversion when processing neighborhood tokens, where high-hop neighborhoods receive disproportionate focus, severely disrupting information interactions between the target node and its neighborhood tokens. To address these challenges, we propose DAM-GT, Dual positional encoding-based Attention Masking graph Transformer. DAM-GT introduces a novel dual positional encoding scheme that incorporates attribute-aware encoding via an attribute clustering strategy, effectively preserving node correlations in both topological and attribute spaces. In addition, DAM-GT formulates a new attention mechanism with a simple yet effective masking strategy to guide interactions between target nodes and their neighborhood tokens, overcoming the issue of attention diversion. Extensive experiments on various graphs with different homophily levels as well as different scales demonstrate that DAM-GT consistently outperforms state-of-the-art methods in node classification tasks.
Diffusion Augmented Complex Maximum Total Correntropy Algorithm for Power System Frequency Estimation
Apr 10, 2025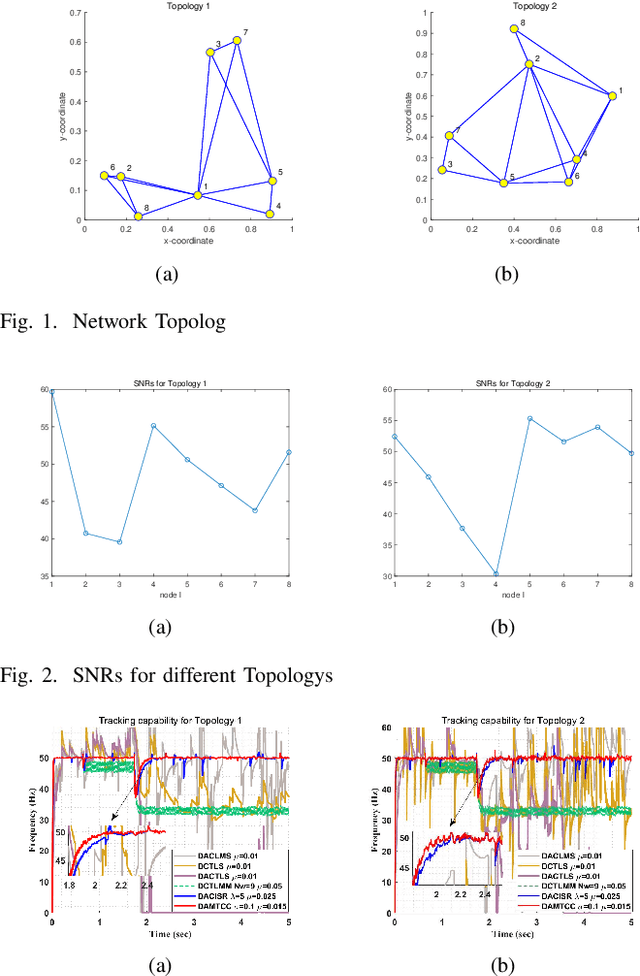
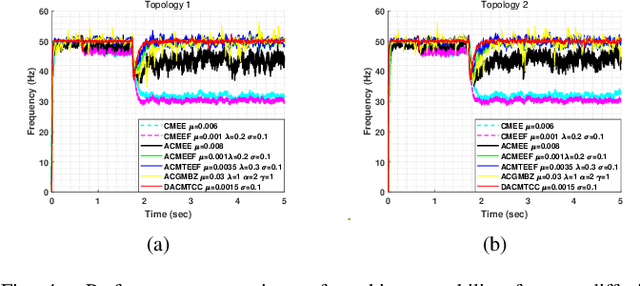
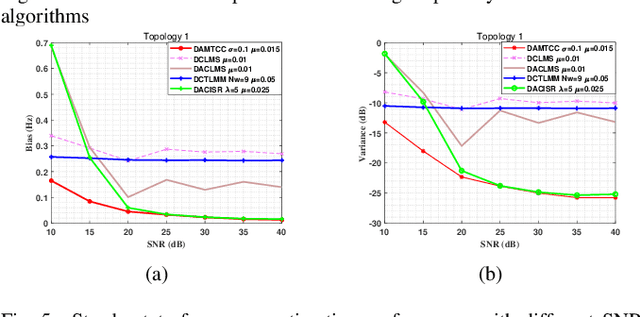
Currently, adaptive filtering algorithms have been widely applied in frequency estimation for power systems. However, research on diffusion tasks remains insufficient. Existing diffusion adaptive frequency estimation algorithms exhibit certain limitations in handling input noise and lack robustness against impulsive noise. Moreover, traditional adaptive filtering algorithms designed based on the strictly-linear (SL) model fail to effectively address frequency estimation challenges in unbalanced three-phase power systems. To address these issues, this letter proposes an improved diffusion augmented complex maximum total correntropy (DAMTCC) algorithm based on the widely linear (WL) model. The proposed algorithm not only significantly enhances the capability to handle input noise but also demonstrates superior robustness to impulsive noise. Furthermore, it successfully resolves the critical challenge of frequency estimation in unbalanced three-phase power systems, offering an efficient and reliable solution for diffusion power system frequency estimation. Finally, we analyze the stability of the algorithm and computer simulations verify the excellent performance of the algorithm.
Mixture of Decoupled Message Passing Experts with Entropy Constraint for General Node Classification
Feb 12, 2025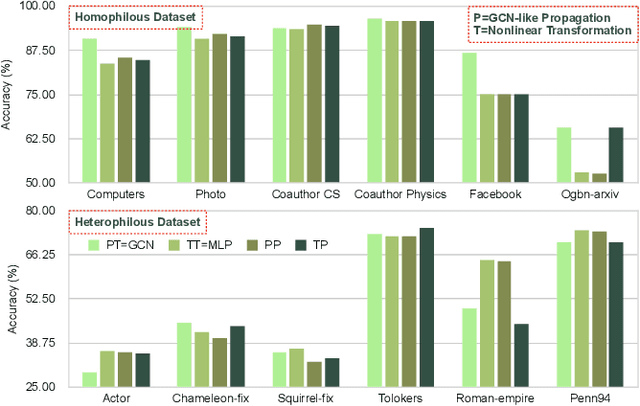

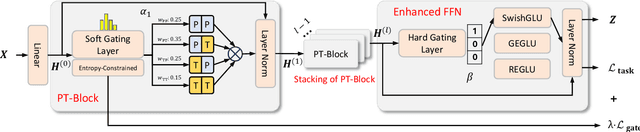
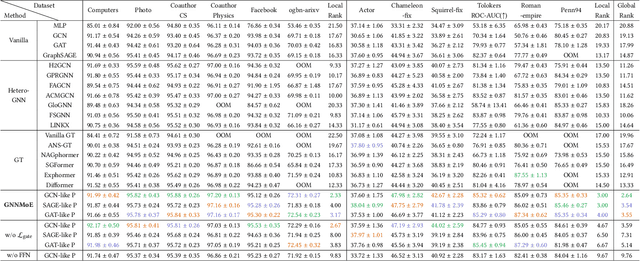
The varying degrees of homophily and heterophily in real-world graphs persistently constrain the universality of graph neural networks (GNNs) for node classification. Adopting a data-centric perspective, this work reveals an inherent preference of different graphs towards distinct message encoding schemes: homophilous graphs favor local propagation, while heterophilous graphs exhibit preference for flexible combinations of propagation and transformation. To address this, we propose GNNMoE, a universal node classification framework based on the Mixture-of-Experts (MoE) mechanism. The framework first constructs diverse message-passing experts through recombination of fine-grained encoding operators, then designs soft and hard gating layers to allocate the most suitable expert networks for each node's representation learning, thereby enhancing both model expressiveness and adaptability to diverse graphs. Furthermore, considering that soft gating might introduce encoding noise in homophilous scenarios, we introduce an entropy constraint to guide sharpening of soft gates, achieving organic integration of weighted combination and Top-K selection. Extensive experiments demonstrate that GNNMoE significantly outperforms mainstream GNNs, heterophilous GNNs, and graph transformers in both node classification performance and universality across diverse graph datasets.
Rethinking Tokenized Graph Transformers for Node Classification
Feb 12, 2025Node tokenized graph Transformers (GTs) have shown promising performance in node classification. The generation of token sequences is the key module in existing tokenized GTs which transforms the input graph into token sequences, facilitating the node representation learning via Transformer. In this paper, we observe that the generations of token sequences in existing GTs only focus on the first-order neighbors on the constructed similarity graphs, which leads to the limited usage of nodes to generate diverse token sequences, further restricting the potential of tokenized GTs for node classification. To this end, we propose a new method termed SwapGT. SwapGT first introduces a novel token swapping operation based on the characteristics of token sequences that fully leverages the semantic relevance of nodes to generate more informative token sequences. Then, SwapGT leverages a Transformer-based backbone to learn node representations from the generated token sequences. Moreover, SwapGT develops a center alignment loss to constrain the representation learning from multiple token sequences, further enhancing the model performance. Extensive empirical results on various datasets showcase the superiority of SwapGT for node classification.
OASIS: Open Agent Social Interaction Simulations with One Million Agents
Nov 26, 2024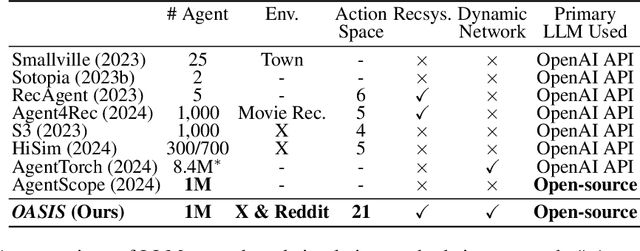
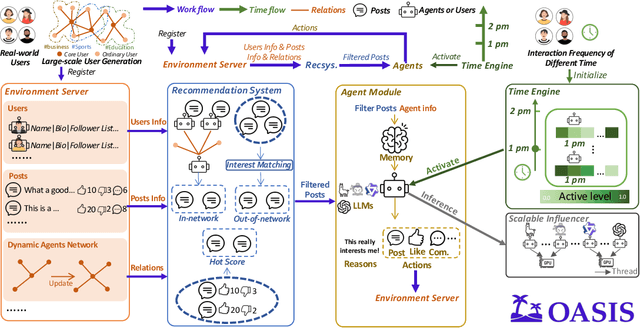

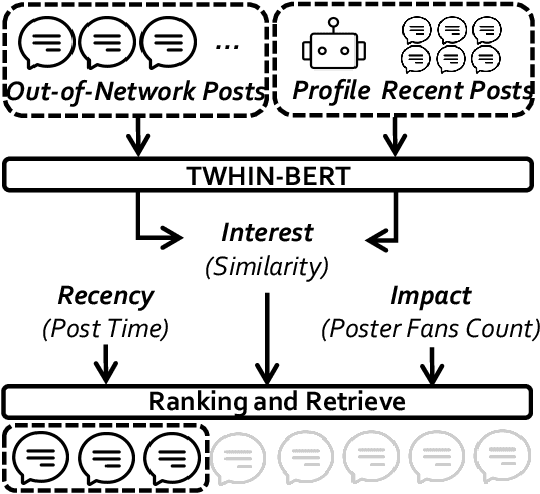
There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
OASIS: Open Agents Social Interaction Simulations on One Million Agents
Nov 21, 2024There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
Leveraging Contrastive Learning for Enhanced Node Representations in Tokenized Graph Transformers
Jun 27, 2024While tokenized graph Transformers have demonstrated strong performance in node classification tasks, their reliance on a limited subset of nodes with high similarity scores for constructing token sequences overlooks valuable information from other nodes, hindering their ability to fully harness graph information for learning optimal node representations. To address this limitation, we propose a novel graph Transformer called GCFormer. Unlike previous approaches, GCFormer develops a hybrid token generator to create two types of token sequences, positive and negative, to capture diverse graph information. And a tailored Transformer-based backbone is adopted to learn meaningful node representations from these generated token sequences. Additionally, GCFormer introduces contrastive learning to extract valuable information from both positive and negative token sequences, enhancing the quality of learned node representations. Extensive experimental results across various datasets, including homophily and heterophily graphs, demonstrate the superiority of GCFormer in node classification, when compared to representative graph neural networks (GNNs) and graph Transformers.
NTFormer: A Composite Node Tokenized Graph Transformer for Node Classification
Jun 27, 2024



Recently, the emerging graph Transformers have made significant advancements for node classification on graphs. In most graph Transformers, a crucial step involves transforming the input graph into token sequences as the model input, enabling Transformer to effectively learn the node representations. However, we observe that existing methods only express partial graph information of nodes through single-type token generation. Consequently, they require tailored strategies to encode additional graph-specific features into the Transformer to ensure the quality of node representation learning, limiting the model flexibility to handle diverse graphs. To this end, we propose a new graph Transformer called NTFormer to address this issue. NTFormer introduces a novel token generator called Node2Par, which constructs various token sequences using different token elements for each node. This flexibility allows Node2Par to generate valuable token sequences from different perspectives, ensuring comprehensive expression of rich graph features. Benefiting from the merits of Node2Par, NTFormer only leverages a Transformer-based backbone without graph-specific modifications to learn node representations, eliminating the need for graph-specific modifications. Extensive experiments conducted on various benchmark datasets containing homophily and heterophily graphs with different scales demonstrate the superiority of NTFormer over representative graph Transformers and graph neural networks for node classification.