 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling
May 24, 2026Physical world knowledge resides mainly in videos. Equipping Vision-Language-Action (VLA) models with such knowledge is fundamental for safe and generalizable planning. Predictive world modeling enables VLA to internalize physical dynamics and long-term causality by predicting future video from past observations. However, naive next-frame prediction faces two challenges: 1) unlike semantically distinct text tokens, video tokens are low-entropy and redundant, causing prediction to degenerate into trivial extrapolation. 2) world modeling poses a temporal dilemma: dense prediction captures instantaneous dynamics, but cannot efficiently model long-horizon causality. To learn world knowledge effectively, we introduce X-Foresight, a predictive world model integrated directly into the VLA architecture to jointly learn world modeling and real-time action control. At its core lies a long-horizon chunk-wise auto-regressive strategy that addresses both challenges: by predicting semantically distant chunks rather than adjacent frames, it escapes trivial extrapolation, while preserving dense intra-chunk frames for instantaneous dynamics and sparse inter-chunk transitions for long-term causality. A curriculum learning schedule progressively extends prediction horizons and stabilizes long-horizon training. To capture long-term causality effectively, we present temporal importance sampling, which concentrates supervision on safety-critical chunks identified by ego-motion and behavioral signals. We further delegate photorealistic synthesis to a diffusion-based multi-view renderer, improving photorealistic appearance. Comprehensive experiments demonstrate that X-Foresight significantly outperforms VLA baselines in planning performance while maintaining strong generative fidelity, establishing a robust paradigm for world-knowledge-driven autonomous systems.
Composer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
Separators in Enhancing Autoregressive Pretraining for Vision Mamba
Mar 04, 2026The state space model Mamba has recently emerged as a promising paradigm in computer vision, attracting significant attention due to its efficient processing of long sequence tasks. Mamba's inherent causal mechanism renders it particularly suitable for autoregressive pretraining. However, current autoregressive pretraining methods are constrained to short sequence tasks, failing to fully exploit Mamba's prowess in handling extended sequences. To address this limitation, we introduce an innovative autoregressive pretraining method for Vision Mamba that substantially extends the input sequence length. We introduce new \textbf{S}epara\textbf{T}ors for \textbf{A}uto\textbf{R}egressive pretraining to demarcate and differentiate between different images, known as \textbf{STAR}. Specifically, we insert identical separators before each image to demarcate its inception. This strategy enables us to quadruple the input sequence length of Vision Mamba while preserving the original dimensions of the dataset images. Employing this long sequence pretraining technique, our STAR-B model achieved an impressive accuracy of 83.5\% on ImageNet-1k, which is highly competitive in Vision Mamba. These results underscore the potential of our method in enhancing the performance of vision models through improved leveraging of long-range dependencies.
Leveraging Contrastive Learning for Enhanced Node Representations in Tokenized Graph Transformers
Jun 27, 2024


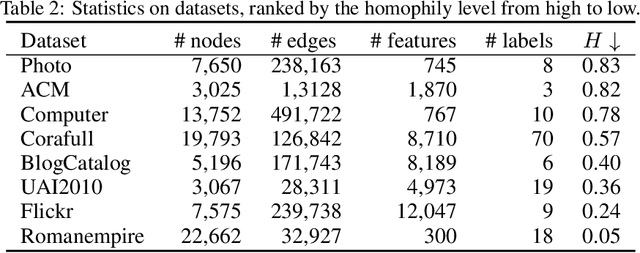
While tokenized graph Transformers have demonstrated strong performance in node classification tasks, their reliance on a limited subset of nodes with high similarity scores for constructing token sequences overlooks valuable information from other nodes, hindering their ability to fully harness graph information for learning optimal node representations. To address this limitation, we propose a novel graph Transformer called GCFormer. Unlike previous approaches, GCFormer develops a hybrid token generator to create two types of token sequences, positive and negative, to capture diverse graph information. And a tailored Transformer-based backbone is adopted to learn meaningful node representations from these generated token sequences. Additionally, GCFormer introduces contrastive learning to extract valuable information from both positive and negative token sequences, enhancing the quality of learned node representations. Extensive experimental results across various datasets, including homophily and heterophily graphs, demonstrate the superiority of GCFormer in node classification, when compared to representative graph neural networks (GNNs) and graph Transformers.
You Only Need Less Attention at Each Stage in Vision Transformers
Jun 01, 2024The advent of Vision Transformers (ViTs) marks a substantial paradigm shift in the realm of computer vision. ViTs capture the global information of images through self-attention modules, which perform dot product computations among patchified image tokens. While self-attention modules empower ViTs to capture long-range dependencies, the computational complexity grows quadratically with the number of tokens, which is a major hindrance to the practical application of ViTs. Moreover, the self-attention mechanism in deep ViTs is also susceptible to the attention saturation issue. Accordingly, we argue against the necessity of computing the attention scores in every layer, and we propose the Less-Attention Vision Transformer (LaViT), which computes only a few attention operations at each stage and calculates the subsequent feature alignments in other layers via attention transformations that leverage the previously calculated attention scores. This novel approach can mitigate two primary issues plaguing traditional self-attention modules: the heavy computational burden and attention saturation. Our proposed architecture offers superior efficiency and ease of implementation, merely requiring matrix multiplications that are highly optimized in contemporary deep learning frameworks. Moreover, our architecture demonstrates exceptional performance across various vision tasks including classification, detection and segmentation.
Knowledge Distillation via Token-level Relationship Graph
Jun 20, 2023Knowledge distillation is a powerful technique for transferring knowledge from a pre-trained teacher model to a student model. However, the true potential of knowledge transfer has not been fully explored. Existing approaches primarily focus on distilling individual information or instance-level relationships, overlooking the valuable information embedded in token-level relationships, which may be particularly affected by the long-tail effects. To address the above limitations, we propose a novel method called Knowledge Distillation with Token-level Relationship Graph (TRG) that leverages the token-wise relational knowledge to enhance the performance of knowledge distillation. By employing TRG, the student model can effectively emulate higher-level semantic information from the teacher model, resulting in improved distillation results. To further enhance the learning process, we introduce a token-wise contextual loss called contextual loss, which encourages the student model to capture the inner-instance semantic contextual of the teacher model. We conduct experiments to evaluate the effectiveness of the proposed method against several state-of-the-art approaches. Empirical results demonstrate the superiority of TRG across various visual classification tasks, including those involving imbalanced data. Our method consistently outperforms the existing baselines, establishing a new state-of-the-art performance in the field of knowledge distillation.
Class-aware Information for Logit-based Knowledge Distillation
Nov 27, 2022



Knowledge distillation aims to transfer knowledge to the student model by utilizing the predictions/features of the teacher model, and feature-based distillation has recently shown its superiority over logit-based distillation. However, due to the cumbersome computation and storage of extra feature transformation, the training overhead of feature-based methods is much higher than that of logit-based distillation. In this work, we revisit the logit-based knowledge distillation, and observe that the existing logit-based distillation methods treat the prediction logits only in the instance level, while many other useful semantic information is overlooked. To address this issue, we propose a Class-aware Logit Knowledge Distillation (CLKD) method, that extents the logit distillation in both instance-level and class-level. CLKD enables the student model mimic higher semantic information from the teacher model, hence improving the distillation performance. We further introduce a novel loss called Class Correlation Loss to force the student learn the inherent class-level correlation of the teacher. Empirical comparisons demonstrate the superiority of the proposed method over several prevailing logit-based methods and feature-based methods, in which CLKD achieves compelling results on various visual classification tasks and outperforms the state-of-the-art baselines.
Feature Interaction Interpretability: A Case for Explaining Ad-Recommendation Systems via Neural Interaction Detection
Jun 19, 2020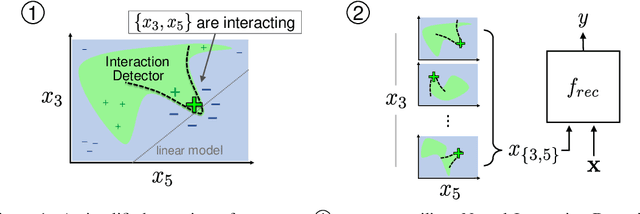
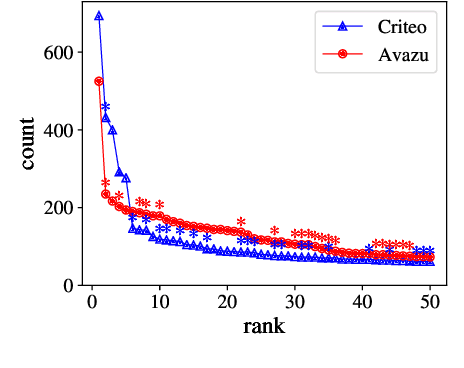


Recommendation is a prevalent application of machine learning that affects many users; therefore, it is important for recommender models to be accurate and interpretable. In this work, we propose a method to both interpret and augment the predictions of black-box recommender systems. In particular, we propose to interpret feature interactions from a source recommender model and explicitly encode these interactions in a target recommender model, where both source and target models are black-boxes. By not assuming the structure of the recommender system, our approach can be used in general settings. In our experiments, we focus on a prominent use of machine learning recommendation: ad-click prediction. We found that our interaction interpretations are both informative and predictive, e.g., significantly outperforming existing recommender models. What's more, the same approach to interpret interactions can provide new insights into domains even beyond recommendation, such as text and image classification.