 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormAct: A Benchmark for Hidden Social Norm Compliance in Embodied Planning
Jun 26, 2026Multimodal large language models (MLLMs) are increasingly deployed as embodied planners in egocentric environments, where task success requires not only achieving instructed goals but also acting in socially appropriate ways. While explicit goals may render certain actions optimal, implicit social norms often impose hidden constraints. Existing evaluations typically focus on explicit goal achievement or direct norm knowledge, seldom assessing whether planners can infer and apply these hidden constraints within action sequences. We introduce NormAct, a benchmark for embodied social-norm interactions that evaluates plans on Goal Achievement, Norm Compliance, and overall Task Success. NormAct uniquely embeds hidden norms within ordinary tasks, testing whether models can realize them without explicit instruction. Experiments with state-of-the-art MLLMs (GPT-5.4, Claude Opus 4.7, Gemini 3 Pro) reveal a significant gap: models achieve explicit goals in 67.3\% of cases, but comply with hidden norms in only 26.4\%. Cue-condition experiments indicate that this gap stems not from a lack of general social knowledge, but from challenges in activating and grounding relevant norms in context. To address this, we propose NormPerceptor, a context-conditioned cue generator that infers scene-relevant norms prior to planning, increasing Task Success from 24.2\% to 46.7\%. Our results underscore the importance of enabling embodied agents to proactively detect hidden norms, ground them in visual evidence, and integrate them as action-planning constraints. Our benchmark is publicly available at https://huggingface.co/datasets/Caleb196x/NormAct.
Adaptive Punishment for Cooperation in Mixed-Motive Games
May 23, 2026Mixed-motive scenarios are ubiquitous in real-world multi-agent interactions, where self-interested agents often defect for immediate rewards, overlooking the potential of altruistic cooperation to improve long-term gains and collective welfare. Peer punishment can deter defection, but as costly second-order altruism, its persistent imposition may undermine the punisher's interests. Existing approaches often struggle to effectively implement punishment to promote cooperation. To balance the efficacy and cost of punishment, we propose Adaptive Punishment for Cooperation (APC), a distributed method that determines punishment intensity based on both a dynamic punishment probability and the severity of defection. This dynamic probability substantially reduces costly and ineffective punishment while also promotes cooperation. To accurately assess defection and its severity, we use a defection awareness module, whose learning is guided by game reward. Theoretical analysis and empirical results show APC performs effectively in iterated public goods game. Empirically, APC also significantly outperforms existing baselines across sequential social dilemmas, learning rational and effective punishment policies that foster cooperation by strategically deterring defection.
Expectation Error Bounds for Transfer Learning in Linear Regression and Linear Neural Networks
Mar 30, 2026In transfer learning, the learner leverages auxiliary data to improve generalization on a main task. However, the precise theoretical understanding of when and how auxiliary data help remains incomplete. We provide new insights on this issue in two canonical linear settings: ordinary least squares regression and under-parameterized linear neural networks. For linear regression, we derive exact closed-form expressions for the expected generalization error with bias-variance decomposition, yielding necessary and sufficient conditions for auxiliary tasks to improve generalization on the main task. We also derive globally optimal task weights as outputs of solvable optimization programs, with consistency guarantees for empirical estimates. For linear neural networks with shared representations of width $q \leq K$, where $K$ is the number of auxiliary tasks, we derive a non-asymptotic expectation bound on the generalization error, yielding the first non-vacuous sufficient condition for beneficial auxiliary learning in this setting, as well as principled directions for task weight curation. We achieve this by proving a new column-wise low-rank perturbation bound for random matrices, which improves upon existing bounds by preserving fine-grained column structures. Our results are verified on synthetic data simulated with controlled parameters.
Credibility Governance: A Social Mechanism for Collective Self-Correction under Weak Truth Signals
Mar 03, 2026Online platforms increasingly rely on opinion aggregation to allocate real-world attention and resources, yet common signals such as engagement votes or capital-weighted commitments are easy to amplify and often track visibility rather than reliability. This makes collective judgments brittle under weak truth signals, noisy or delayed feedback, early popularity surges, and strategic manipulation. We propose Credibility Governance (CG), a mechanism that reallocates influence by learning which agents and viewpoints consistently track evolving public evidence. CG maintains dynamic credibility scores for both agents and opinions, updates opinion influence via credibility-weighted endorsements, and updates agent credibility based on the long-run performance of the opinions they support, rewarding early and persistent alignment with emerging evidence while filtering short-lived noise. We evaluate CG in POLIS, a socio-physical simulation environment that models coupled belief dynamics and downstream feedback under uncertainty. Across settings with initial majority misalignment, observation noise and contamination, and misinformation shocks, CG outperforms vote-based, stake-weighted, and no-governance baselines, yielding faster recovery to the true state, reduced lock-in and path dependence, and improved robustness under adversarial pressure. Our implementation and experimental scripts are publicly available at https://github.com/Wanying-He/Credibility_Governance.
Social World Model-Augmented Mechanism Design Policy Learning
Oct 22, 2025Designing adaptive mechanisms to align individual and collective interests remains a central challenge in artificial social intelligence. Existing methods often struggle with modeling heterogeneous agents possessing persistent latent traits (e.g., skills, preferences) and dealing with complex multi-agent system dynamics. These challenges are compounded by the critical need for high sample efficiency due to costly real-world interactions. World Models, by learning to predict environmental dynamics, offer a promising pathway to enhance mechanism design in heterogeneous and complex systems. In this paper, we introduce a novel method named SWM-AP (Social World Model-Augmented Mechanism Design Policy Learning), which learns a social world model hierarchically modeling agents' behavior to enhance mechanism design. Specifically, the social world model infers agents' traits from their interaction trajectories and learns a trait-based model to predict agents' responses to the deployed mechanisms. The mechanism design policy collects extensive training trajectories by interacting with the social world model, while concurrently inferring agents' traits online during real-world interactions to further boost policy learning efficiency. Experiments in diverse settings (tax policy design, team coordination, and facility location) demonstrate that SWM-AP outperforms established model-based and model-free RL baselines in cumulative rewards and sample efficiency.
Cross-attention Secretly Performs Orthogonal Alignment in Recommendation Models
Oct 10, 2025Cross-domain sequential recommendation (CDSR) aims to align heterogeneous user behavior sequences collected from different domains. While cross-attention is widely used to enhance alignment and improve recommendation performance, its underlying mechanism is not fully understood. Most researchers interpret cross-attention as residual alignment, where the output is generated by removing redundant and preserving non-redundant information from the query input by referencing another domain data which is input key and value. Beyond the prevailing view, we introduce Orthogonal Alignment, a phenomenon in which cross-attention discovers novel information that is not present in the query input, and further argue that those two contrasting alignment mechanisms can co-exist in recommendation models We find that when the query input and output of cross-attention are orthogonal, model performance improves over 300 experiments. Notably, Orthogonal Alignment emerges naturally, without any explicit orthogonality constraints. Our key insight is that Orthogonal Alignment emerges naturally because it improves scaling law. We show that baselines additionally incorporating cross-attention module outperform parameter-matched baselines, achieving a superior accuracy-per-model parameter. We hope these findings offer new directions for parameter-efficient scaling in multi-modal research.
Endoscopic Depth Estimation Based on Deep Learning: A Survey
Jul 28, 2025Endoscopic depth estimation is a critical technology for improving the safety and precision of minimally invasive surgery. It has attracted considerable attention from researchers in medical imaging, computer vision, and robotics. Over the past decade, a large number of methods have been developed. Despite the existence of several related surveys, a comprehensive overview focusing on recent deep learning-based techniques is still limited. This paper endeavors to bridge this gap by systematically reviewing the state-of-the-art literature. Specifically, we provide a thorough survey of the field from three key perspectives: data, methods, and applications, covering a range of methods including both monocular and stereo approaches. We describe common performance evaluation metrics and summarize publicly available datasets. Furthermore, this review analyzes the specific challenges of endoscopic scenes and categorizes representative techniques based on their supervision strategies and network architectures. The application of endoscopic depth estimation in the important area of robot-assisted surgery is also reviewed. Finally, we outline potential directions for future research, such as domain adaptation, real-time implementation, and enhanced model generalization, thereby providing a valuable starting point for researchers to engage with and advance the field.
SIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning
Jun 05, 2025The rich and multifaceted nature of human social interaction, encompassing multimodal cues, unobservable relations and mental states, and dynamical behavior, presents a formidable challenge for artificial intelligence. To advance research in this area, we introduce SIV-Bench, a novel video benchmark for rigorously evaluating the capabilities of Multimodal Large Language Models (MLLMs) across Social Scene Understanding (SSU), Social State Reasoning (SSR), and Social Dynamics Prediction (SDP). SIV-Bench features 2,792 video clips and 8,792 meticulously generated question-answer pairs derived from a human-LLM collaborative pipeline. It is originally collected from TikTok and YouTube, covering a wide range of video genres, presentation styles, and linguistic and cultural backgrounds. It also includes a dedicated setup for analyzing the impact of different textual cues-original on-screen text, added dialogue, or no text. Our comprehensive experiments on leading MLLMs reveal that while models adeptly handle SSU, they significantly struggle with SSR and SDP, where Relation Inference (RI) is an acute bottleneck, as further examined in our analysis. Our study also confirms the critical role of transcribed dialogue in aiding comprehension of complex social interactions. By systematically identifying current MLLMs' strengths and limitations, SIV-Bench offers crucial insights to steer the development of more socially intelligent AI. The dataset and code are available at https://kfq20.github.io/sivbench/.
A Language Vision Model Approach for Automated Tumor Contouring in Radiation Oncology
Mar 19, 2025



Background: Lung cancer ranks as the leading cause of cancer-related mortality worldwide. The complexity of tumor delineation, crucial for radiation therapy, requires expertise often unavailable in resource-limited settings. Artificial Intelligence(AI), particularly with advancements in deep learning (DL) and natural language processing (NLP), offers potential solutions yet is challenged by high false positive rates. Purpose: The Oncology Contouring Copilot (OCC) system is developed to leverage oncologist expertise for precise tumor contouring using textual descriptions, aiming to increase the efficiency of oncological workflows by combining the strengths of AI with human oversight. Methods: Our OCC system initially identifies nodule candidates from CT scans. Employing Language Vision Models (LVMs) like GPT-4V, OCC then effectively reduces false positives with clinical descriptive texts, merging textual and visual data to automate tumor delineation, designed to elevate the quality of oncology care by incorporating knowledge from experienced domain experts. Results: Deployments of the OCC system resulted in a significant reduction in the false discovery rate by 35.0%, a 72.4% decrease in false positives per scan, and an F1-score of 0.652 across our dataset for unbiased evaluation. Conclusions: OCC represents a significant advance in oncology care, particularly through the use of the latest LVMs to improve contouring results by (1) streamlining oncology treatment workflows by optimizing tumor delineation, reducing manual processes; (2) offering a scalable and intuitive framework to reduce false positives in radiotherapy planning using LVMs; (3) introducing novel medical language vision prompt techniques to minimize LVMs hallucinations with ablation study, and (4) conducting a comparative analysis of LVMs, highlighting their potential in addressing medical language vision challenges.
FedOSAA: Improving Federated Learning with One-Step Anderson Acceleration
Mar 14, 2025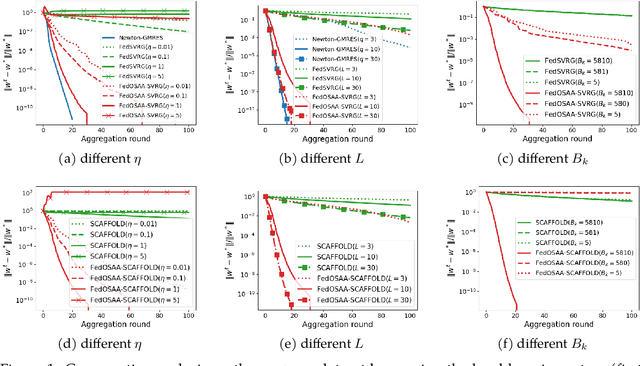
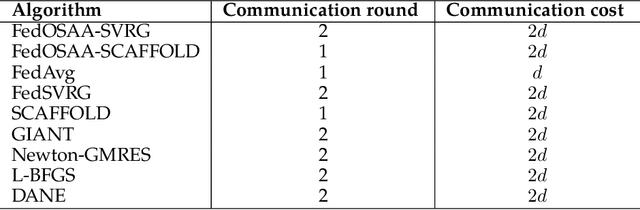
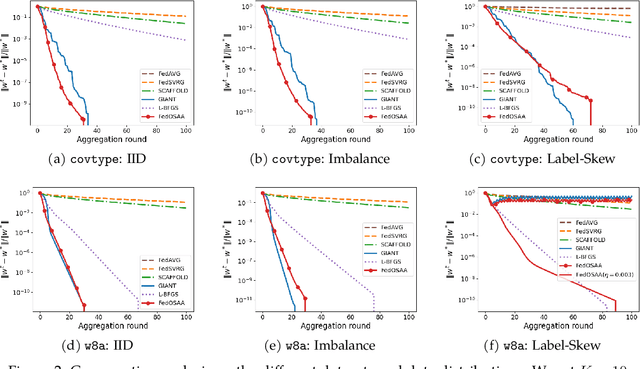
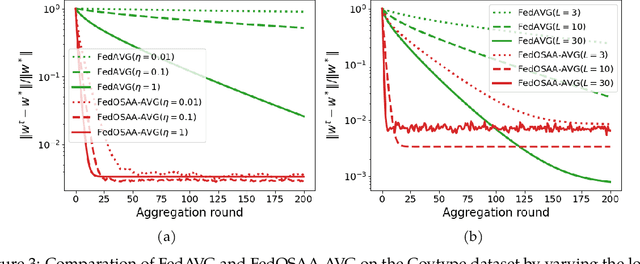
Federated learning (FL) is a distributed machine learning approach that enables multiple local clients and a central server to collaboratively train a model while keeping the data on their own devices. First-order methods, particularly those incorporating variance reduction techniques, are the most widely used FL algorithms due to their simple implementation and stable performance. However, these methods tend to be slow and require a large number of communication rounds to reach the global minimizer. We propose FedOSAA, a novel approach that preserves the simplicity of first-order methods while achieving the rapid convergence typically associated with second-order methods. Our approach applies one Anderson acceleration (AA) step following classical local updates based on first-order methods with variance reduction, such as FedSVRG and SCAFFOLD, during local training. This AA step is able to leverage curvature information from the history points and gives a new update that approximates the Newton-GMRES direction, thereby significantly improving the convergence. We establish a local linear convergence rate to the global minimizer of FedOSAA for smooth and strongly convex loss functions. Numerical comparisons show that FedOSAA substantially improves the communication and computation efficiency of the original first-order methods, achieving performance comparable to second-order methods like GIANT.