 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Discerning with LLM-Enhanced Generative Retrieval
Dec 11, 2024



Sequential recommendation systems aim to provide personalized recommendations for users based on their interaction history. To achieve this, they often incorporate auxiliary information, such as textual descriptions of items and auxiliary tasks, like predicting user preferences and intent. Despite numerous efforts to enhance these models, they still suffer from limited personalization. To address this issue, we propose a new paradigm, which we term preference discerning. In preference dscerning, we explicitly condition a generative sequential recommendation system on user preferences within its context. To this end, we generate user preferences using Large Language Models (LLMs) based on user reviews and item-specific data. To evaluate preference discerning capabilities of sequential recommendation systems, we introduce a novel benchmark that provides a holistic evaluation across various scenarios, including preference steering and sentiment following. We assess current state-of-the-art methods using our benchmark and show that they struggle to accurately discern user preferences. Therefore, we propose a new method named Mender ($\textbf{M}$ultimodal Prefer$\textbf{en}$ce $\textbf{d}$iscern$\textbf{er}$), which improves upon existing methods and achieves state-of-the-art performance on our benchmark. Our results show that Mender can be effectively guided by human preferences even though they have not been observed during training, paving the way toward more personalized sequential recommendation systems. We will open-source the code and benchmarks upon publication.
Multisample Flow Matching: Straightening Flows with Minibatch Couplings
Apr 28, 2023



Simulation-free methods for training continuous-time generative models construct probability paths that go between noise distributions and individual data samples. Recent works, such as Flow Matching, derived paths that are optimal for each data sample. However, these algorithms rely on independent data and noise samples, and do not exploit underlying structure in the data distribution for constructing probability paths. We propose Multisample Flow Matching, a more general framework that uses non-trivial couplings between data and noise samples while satisfying the correct marginal constraints. At very small overhead costs, this generalization allows us to (i) reduce gradient variance during training, (ii) obtain straighter flows for the learned vector field, which allows us to generate high-quality samples using fewer function evaluations, and (iii) obtain transport maps with lower cost in high dimensions, which has applications beyond generative modeling. Importantly, we do so in a completely simulation-free manner with a simple minimization objective. We show that our proposed methods improve sample consistency on downsampled ImageNet data sets, and lead to better low-cost sample generation.
Theseus: A Library for Differentiable Nonlinear Optimization
Jul 19, 2022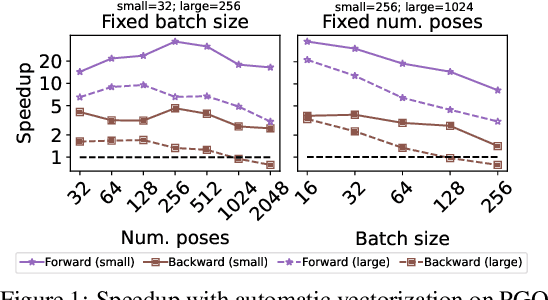
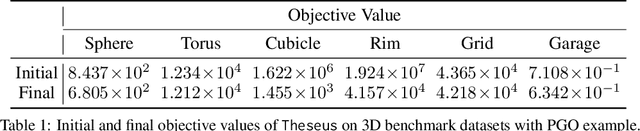
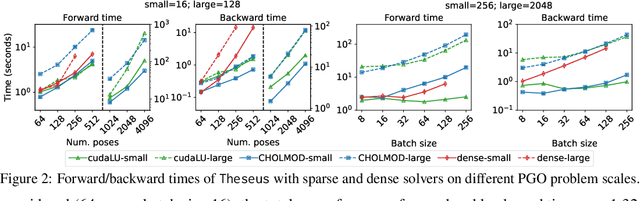
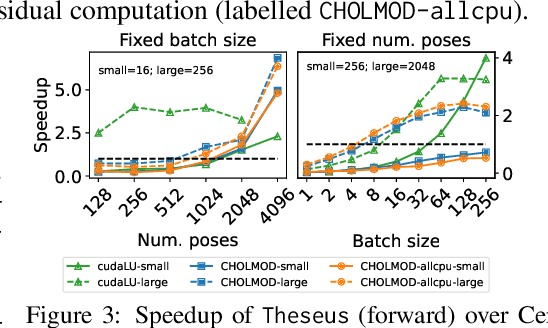
We present Theseus, an efficient application-agnostic open source library for differentiable nonlinear least squares (DNLS) optimization built on PyTorch, providing a common framework for end-to-end structured learning in robotics and vision. Existing DNLS implementations are application specific and do not always incorporate many ingredients important for efficiency. Theseus is application-agnostic, as we illustrate with several example applications that are built using the same underlying differentiable components, such as second-order optimizers, standard costs functions, and Lie groups. For efficiency, Theseus incorporates support for sparse solvers, automatic vectorization, batching, GPU acceleration, and gradient computation with implicit differentiation and direct loss minimization. We do extensive performance evaluation in a set of applications, demonstrating significant efficiency gains and better scalability when these features are incorporated. Project page: https://sites.google.com/view/theseus-ai
Domain Adaptation via CycleGAN for Retina Segmentation in Optical Coherence Tomography
Jul 06, 2021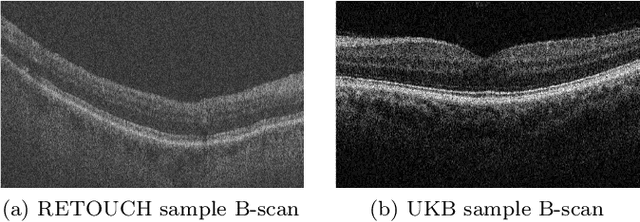
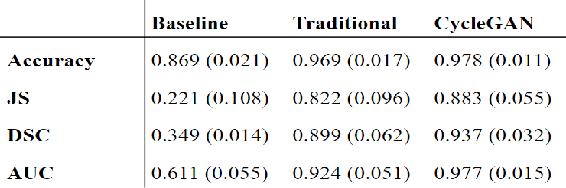
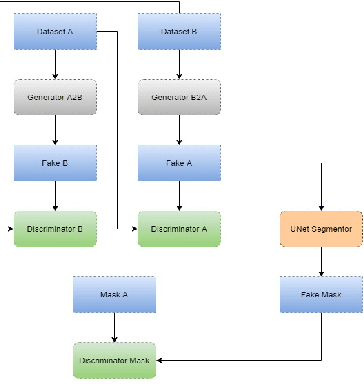
With the FDA approval of Artificial Intelligence (AI) for point-of-care clinical diagnoses, model generalizability is of the utmost importance as clinical decision-making must be domain-agnostic. A method of tackling the problem is to increase the dataset to include images from a multitude of domains; while this technique is ideal, the security requirements of medical data is a major limitation. Additionally, researchers with developed tools benefit from the addition of open-sourced data, but are limited by the difference in domains. Herewith, we investigated the implementation of a Cycle-Consistent Generative Adversarial Networks (CycleGAN) for the domain adaptation of Optical Coherence Tomography (OCT) volumes. This study was done in collaboration with the Biomedical Optics Research Group and Functional & Anatomical Imaging & Shape Analysis Lab at Simon Fraser University. In this study, we investigated a learning-based approach of adapting the domain of a publicly available dataset, UK Biobank dataset (UKB). To evaluate the performance of domain adaptation, we utilized pre-existing retinal layer segmentation tools developed on a different set of RETOUCH OCT data. This study provides insight on state-of-the-art tools for domain adaptation compared to traditional processing techniques as well as a pipeline for adapting publicly available retinal data to the domains previously used by our collaborators.