 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapiens: Foundation for Human Vision Models
Aug 22, 2024



We present Sapiens, a family of models for four fundamental human-centric vision tasks - 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction. Our models natively support 1K high-resolution inference and are extremely easy to adapt for individual tasks by simply fine-tuning models pretrained on over 300 million in-the-wild human images. We observe that, given the same computational budget, self-supervised pretraining on a curated dataset of human images significantly boosts the performance for a diverse set of human-centric tasks. The resulting models exhibit remarkable generalization to in-the-wild data, even when labeled data is scarce or entirely synthetic. Our simple model design also brings scalability - model performance across tasks improves as we scale the number of parameters from 0.3 to 2 billion. Sapiens consistently surpasses existing baselines across various human-centric benchmarks. We achieve significant improvements over the prior state-of-the-art on Humans-5K (pose) by 7.6 mAP, Humans-2K (part-seg) by 17.1 mIoU, Hi4D (depth) by 22.4% relative RMSE, and THuman2 (normal) by 53.5% relative angular error.
MidasTouch: Monte-Carlo inference over distributions across sliding touch
Oct 25, 2022



We present MidasTouch, a tactile perception system for online global localization of a vision-based touch sensor sliding on an object surface. This framework takes in posed tactile images over time, and outputs an evolving distribution of sensor pose on the object's surface, without the need for visual priors. Our key insight is to estimate local surface geometry with tactile sensing, learn a compact representation for it, and disambiguate these signals over a long time horizon. The backbone of MidasTouch is a Monte-Carlo particle filter, with a measurement model based on a tactile code network learned from tactile simulation. This network, inspired by LIDAR place recognition, compactly summarizes local surface geometries. These generated codes are efficiently compared against a precomputed tactile codebook per-object, to update the pose distribution. We further release the YCB-Slide dataset of real-world and simulated forceful sliding interactions between a vision-based tactile sensor and standard YCB objects. While single-touch localization can be inherently ambiguous, we can quickly localize our sensor by traversing salient surface geometries. Project page: https://suddhu.github.io/midastouch-tactile/
Grasp Stability Prediction with Sim-to-Real Transfer from Tactile Sensing
Aug 04, 2022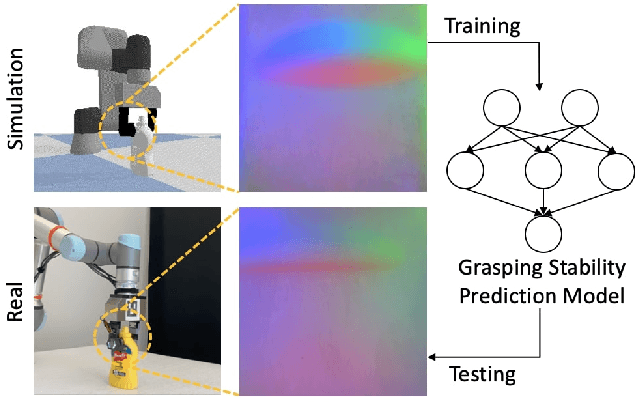
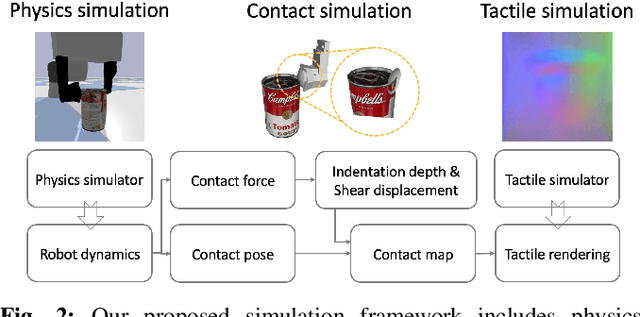
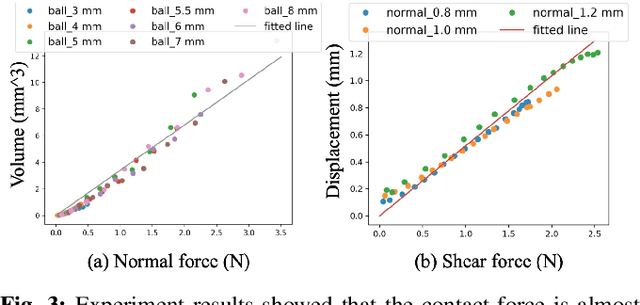
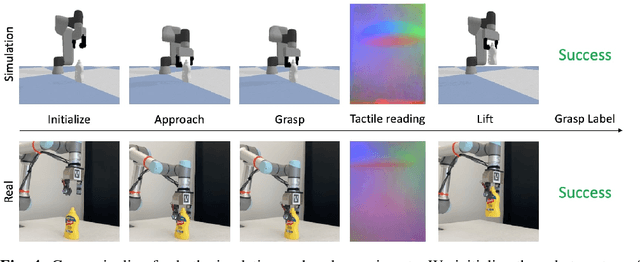
Robot simulation has been an essential tool for data-driven manipulation tasks. However, most existing simulation frameworks lack either efficient and accurate models of physical interactions with tactile sensors or realistic tactile simulation. This makes the sim-to-real transfer for tactile-based manipulation tasks still challenging. In this work, we integrate simulation of robot dynamics and vision-based tactile sensors by modeling the physics of contact. This contact model uses simulated contact forces at the robot's end-effector to inform the generation of realistic tactile outputs. To eliminate the sim-to-real transfer gap, we calibrate our physics simulator of robot dynamics, contact model, and tactile optical simulator with real-world data, and then we demonstrate the effectiveness of our system on a zero-shot sim-to-real grasp stability prediction task where we achieve an average accuracy of 90.7% on various objects. Experiments reveal the potential of applying our simulation framework to more complicated manipulation tasks. We open-source our simulation framework at https://github.com/CMURoboTouch/Taxim/tree/taxim-robot.
Theseus: A Library for Differentiable Nonlinear Optimization
Jul 19, 2022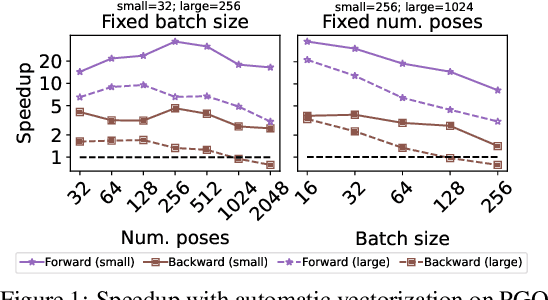
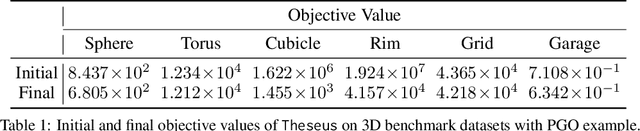
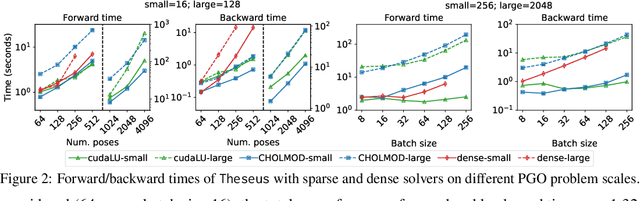
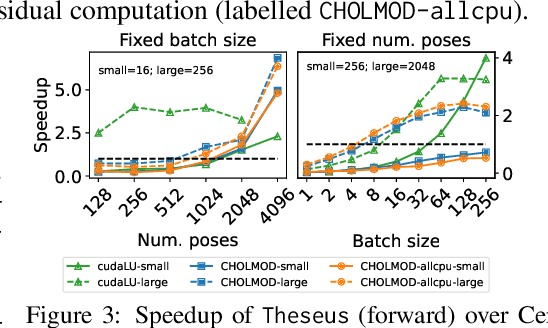
We present Theseus, an efficient application-agnostic open source library for differentiable nonlinear least squares (DNLS) optimization built on PyTorch, providing a common framework for end-to-end structured learning in robotics and vision. Existing DNLS implementations are application specific and do not always incorporate many ingredients important for efficiency. Theseus is application-agnostic, as we illustrate with several example applications that are built using the same underlying differentiable components, such as second-order optimizers, standard costs functions, and Lie groups. For efficiency, Theseus incorporates support for sparse solvers, automatic vectorization, batching, GPU acceleration, and gradient computation with implicit differentiation and direct loss minimization. We do extensive performance evaluation in a set of applications, demonstrating significant efficiency gains and better scalability when these features are incorporated. Project page: https://sites.google.com/view/theseus-ai
Vision Checklist: Towards Testable Error Analysis of Image Models to Help System Designers Interrogate Model Capabilities
Jan 31, 2022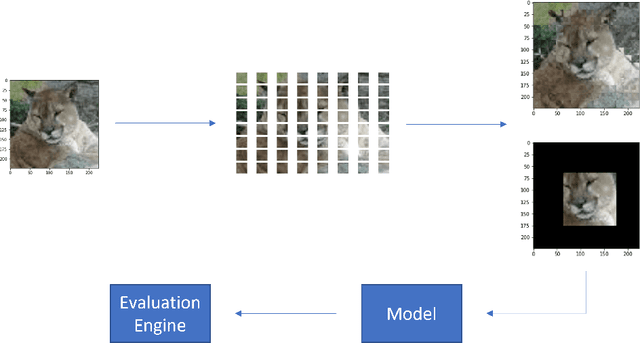



Using large pre-trained models for image recognition tasks is becoming increasingly common owing to the well acknowledged success of recent models like vision transformers and other CNN-based models like VGG and Resnet. The high accuracy of these models on benchmark tasks has translated into their practical use across many domains including safety-critical applications like autonomous driving and medical diagnostics. Despite their widespread use, image models have been shown to be fragile to changes in the operating environment, bringing their robustness into question. There is an urgent need for methods that systematically characterise and quantify the capabilities of these models to help designers understand and provide guarantees about their safety and robustness. In this paper, we propose Vision Checklist, a framework aimed at interrogating the capabilities of a model in order to produce a report that can be used by a system designer for robustness evaluations. This framework proposes a set of perturbation operations that can be applied on the underlying data to generate test samples of different types. The perturbations reflect potential changes in operating environments, and interrogate various properties ranging from the strictly quantitative to more qualitative. Our framework is evaluated on multiple datasets like Tinyimagenet, CIFAR10, CIFAR100 and Camelyon17 and for models like ViT and Resnet. Our Vision Checklist proposes a specific set of evaluations that can be integrated into the previously proposed concept of a model card. Robustness evaluations like our checklist will be crucial in future safety evaluations of visual perception modules, and be useful for a wide range of stakeholders including designers, deployers, and regulators involved in the certification of these systems. Source code of Vision Checklist would be open for public use.
PatchGraph: In-hand tactile tracking with learned surface normals
Nov 15, 2021

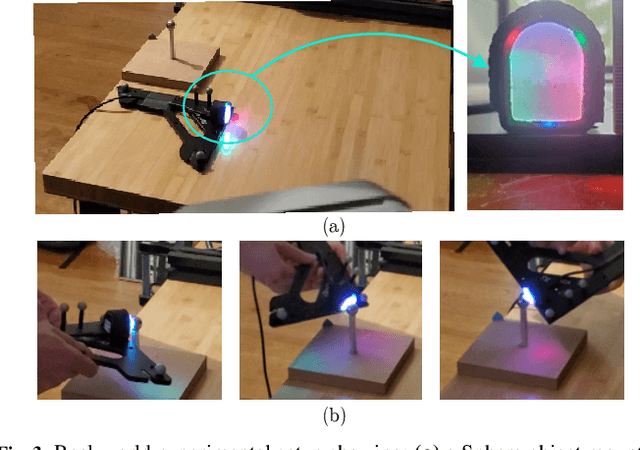
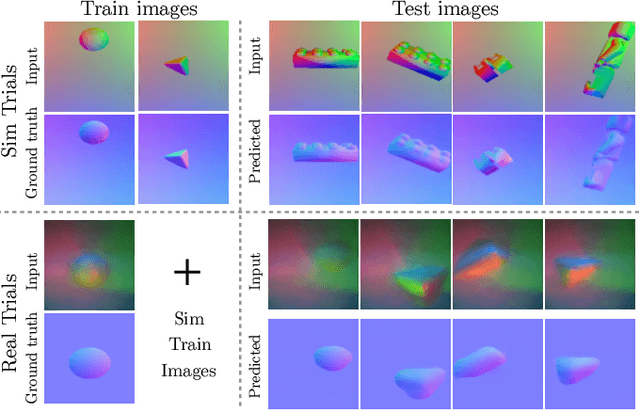
We address the problem of tracking 3D object poses from touch during in-hand manipulations. Specifically, we look at tracking small objects using vision-based tactile sensors that provide high-dimensional tactile image measurements at the point of contact. While prior work has relied on a-priori information about the object being localized, we remove this requirement. Our key insight is that an object is composed of several local surface patches, each informative enough to achieve reliable object tracking. Moreover, we can recover the geometry of this local patch online by extracting local surface normal information embedded in each tactile image. We propose a novel two-stage approach. First, we learn a mapping from tactile images to surface normals using an image translation network. Second, we use these surface normals within a factor graph to both reconstruct a local patch map and use it to infer 3D object poses. We demonstrate reliable object tracking for over 100 contact sequences across unique shapes with four objects in simulation and two objects in the real-world. Supplementary video: https://youtu.be/JwNTC9_nh8M
LEO: Learning Energy-based Models in Graph Optimization
Aug 04, 2021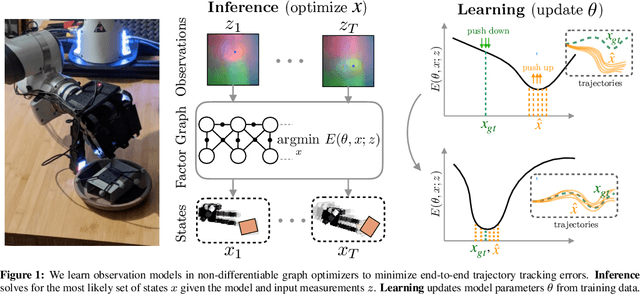
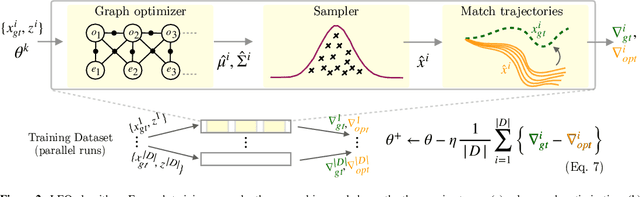
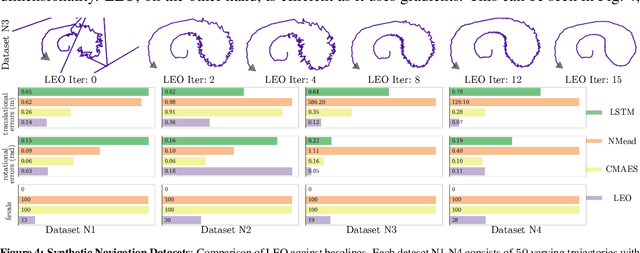
We address the problem of learning observation models end-to-end for estimation. Robots operating in partially observable environments must infer latent states from multiple sensory inputs using observation models that capture the joint distribution between latent states and observations. This inference problem can be formulated as an objective over a graph that optimizes for the most likely sequence of states using all previous measurements. Prior work uses observation models that are either known a-priori or trained on surrogate losses independent of the graph optimizer. In this paper, we propose a method to directly optimize end-to-end tracking performance by learning observation models with the graph optimizer in the loop. This direct approach may appear, however, to require the inference algorithm to be fully differentiable, which many state-of-the-art graph optimizers are not. Our key insight is to instead formulate the problem as that of energy-based learning. We propose a novel approach, LEO, for learning observation models end-to-end with non-differentiable graph optimizers. LEO alternates between sampling trajectories from the graph posterior and updating the model to match these samples to ground truth trajectories. We propose a way to generate such samples efficiently using incremental Gauss-Newton solvers. We compare LEO against baselines on datasets drawn from two distinct tasks: navigation and real-world planar pushing. We show that LEO is able to learn complex observation models with lower errors and fewer samples. Supplementary video: https://youtu.be/qWcH9CBXs5c
Learning Tactile Models for Factor Graph-based State Estimation
Dec 07, 2020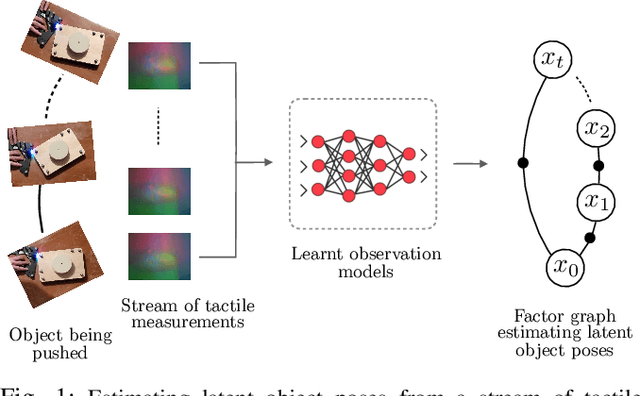
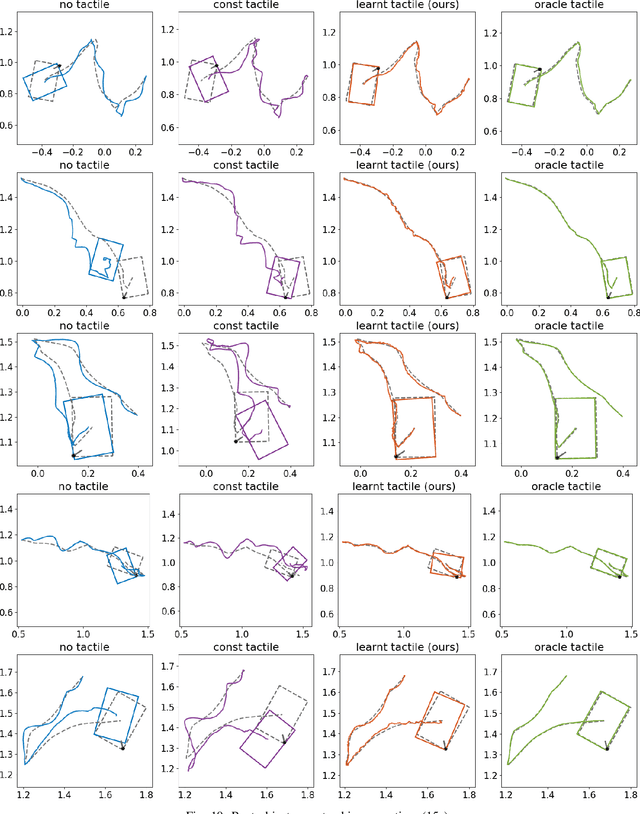
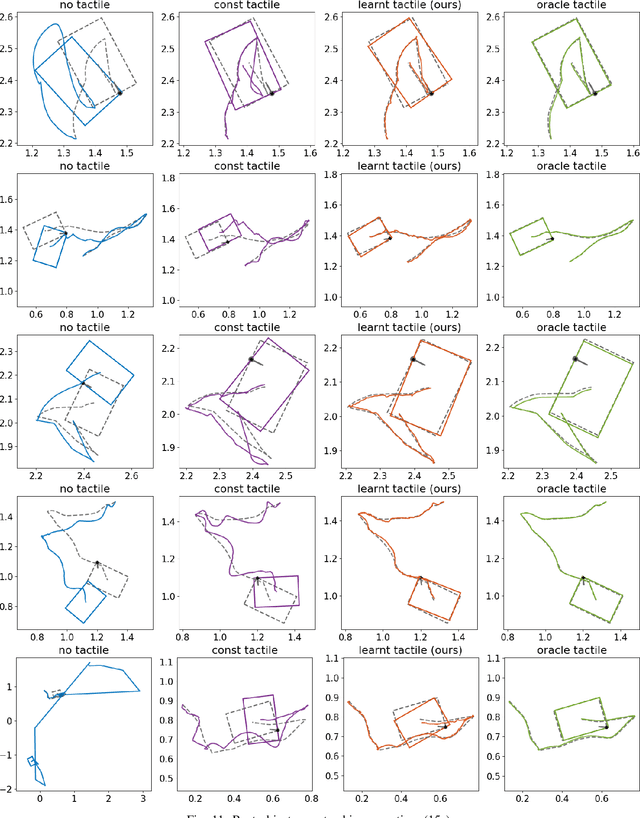
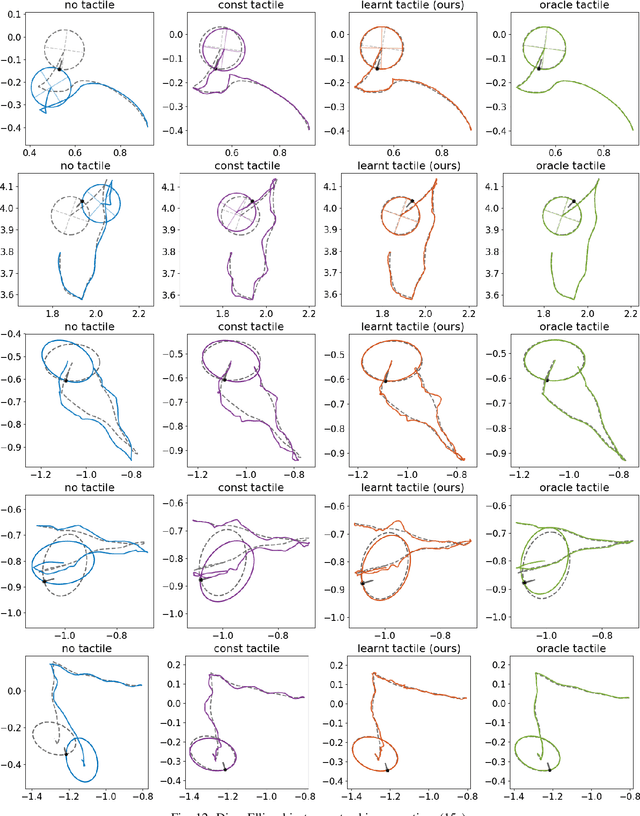
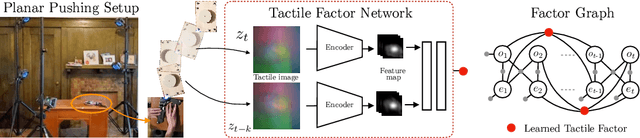
We address the problem of estimating object pose from touch during manipulation under occlusion. Vision-based tactile sensors provide rich, local measurements at the point of contact. A single such measurement, however, contains limited information and multiple measurements are needed to infer latent object state. We solve this inference problem using a factor graph. In order to incorporate tactile measurements in the graph, we need local observation models that can map high-dimensional tactile images onto a low-dimensional state space. Prior work has used low-dimensional force measurements or hand-designed functions to interpret tactile measurements. These methods, however, can be brittle and difficult to scale across objects and sensors. Our key insight is to directly learn tactile observation models that predict the relative pose of the sensor given a pair of tactile images. These relative poses can then be incorporated as factors within a factor graph. We propose a two-stage approach: first we learn local tactile observation models supervised with ground truth data, and then integrate these models along with physics and geometric factors within a factor graph optimizer. We demonstrate reliable object tracking using only tactile feedback for over 150 real-world planar pushing sequences with varying trajectories across three object shapes. Supplementary video: https://youtu.be/gp5fuIZTXMA
Towards high-throughput 3D insect capture for species discovery and diagnostics
Sep 07, 2017
Digitisation of natural history collections not only preserves precious information about biological diversity, it also enables us to share, analyse, annotate and compare specimens to gain new insights. High-resolution, full-colour 3D capture of biological specimens yields color and geometry information complementary to other techniques (e.g., 2D capture, electron scanning and micro computed tomography). However 3D colour capture of small specimens is slow for reasons including specimen handling, the narrow depth of field of high magnification optics, and the large number of images required to resolve complex shapes of specimens. In this paper, we outline techniques to accelerate 3D image capture, including using a desktop robotic arm to automate the insect handling process; using a calibrated pan-tilt rig to avoid attaching calibration targets to specimens; using light field cameras to capture images at an extended depth of field in one shot; and using 3D Web and mixed reality tools to facilitate the annotation, distribution and visualisation of 3D digital models.