 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Retargeting: A Principled, Ultrafast Neural Hand Retargeting Algorithm
Mar 10, 2025We introduce Geometric Retargeting (GeoRT), an ultrafast, and principled neural hand retargeting algorithm for teleoperation, developed as part of our recent Dexterity Gen (DexGen) system. GeoRT converts human finger keypoints to robot hand keypoints at 1KHz, achieving state-of-the-art speed and accuracy with significantly fewer hyperparameters. This high-speed capability enables flexible postprocessing, such as leveraging a foundational controller for action correction like DexGen. GeoRT is trained in an unsupervised manner, eliminating the need for manual annotation of hand pairs. The core of GeoRT lies in novel geometric objective functions that capture the essence of retargeting: preserving motion fidelity, ensuring configuration space (C-space) coverage, maintaining uniform response through high flatness, pinch correspondence and preventing self-collisions. This approach is free from intensive test-time optimization, offering a more scalable and practical solution for real-time hand retargeting.
DexterityGen: Foundation Controller for Unprecedented Dexterity
Feb 06, 2025



Teaching robots dexterous manipulation skills, such as tool use, presents a significant challenge. Current approaches can be broadly categorized into two strategies: human teleoperation (for imitation learning) and sim-to-real reinforcement learning. The first approach is difficult as it is hard for humans to produce safe and dexterous motions on a different embodiment without touch feedback. The second RL-based approach struggles with the domain gap and involves highly task-specific reward engineering on complex tasks. Our key insight is that RL is effective at learning low-level motion primitives, while humans excel at providing coarse motion commands for complex, long-horizon tasks. Therefore, the optimal solution might be a combination of both approaches. In this paper, we introduce DexterityGen (DexGen), which uses RL to pretrain large-scale dexterous motion primitives, such as in-hand rotation or translation. We then leverage this learned dataset to train a dexterous foundational controller. In the real world, we use human teleoperation as a prompt to the controller to produce highly dexterous behavior. We evaluate the effectiveness of DexGen in both simulation and real world, demonstrating that it is a general-purpose controller that can realize input dexterous manipulation commands and significantly improves stability by 10-100x measured as duration of holding objects across diverse tasks. Notably, with DexGen we demonstrate unprecedented dexterous skills including diverse object reorientation and dexterous tool use such as pen, syringe, and screwdriver for the first time.
Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation
Dec 20, 2023To achieve human-level dexterity, robots must infer spatial awareness from multimodal sensing to reason over contact interactions. During in-hand manipulation of novel objects, such spatial awareness involves estimating the object's pose and shape. The status quo for in-hand perception primarily employs vision, and restricts to tracking a priori known objects. Moreover, visual occlusion of objects in-hand is imminent during manipulation, preventing current systems to push beyond tasks without occlusion. We combine vision and touch sensing on a multi-fingered hand to estimate an object's pose and shape during in-hand manipulation. Our method, NeuralFeels, encodes object geometry by learning a neural field online and jointly tracks it by optimizing a pose graph problem. We study multimodal in-hand perception in simulation and the real-world, interacting with different objects via a proprioception-driven policy. Our experiments show final reconstruction F-scores of $81$% and average pose drifts of $4.7\,\text{mm}$, further reduced to $2.3\,\text{mm}$ with known CAD models. Additionally, we observe that under heavy visual occlusion we can achieve up to $94$% improvements in tracking compared to vision-only methods. Our results demonstrate that touch, at the very least, refines and, at the very best, disambiguates visual estimates during in-hand manipulation. We release our evaluation dataset of 70 experiments, FeelSight, as a step towards benchmarking in this domain. Our neural representation driven by multimodal sensing can serve as a perception backbone towards advancing robot dexterity. Videos can be found on our project website https://suddhu.github.io/neural-feels/
Perceiving Extrinsic Contacts from Touch Improves Learning Insertion Policies
Sep 28, 2023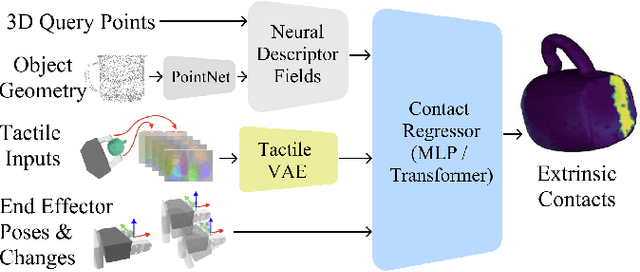

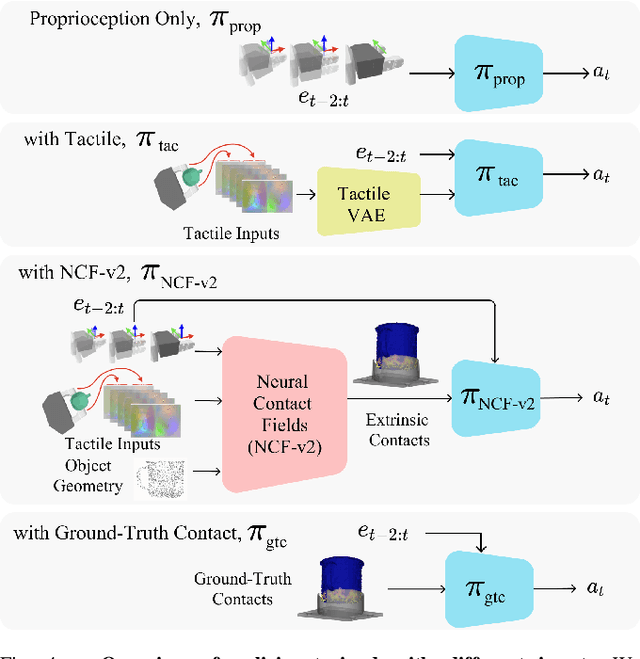
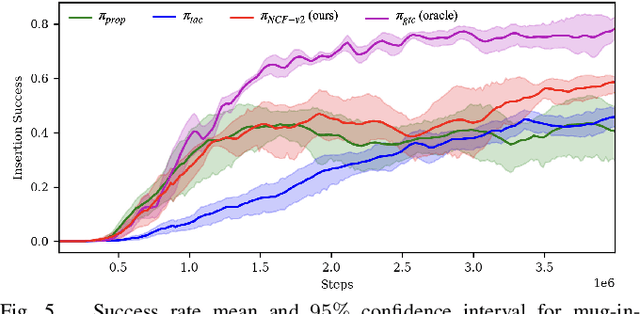
Robotic manipulation tasks such as object insertion typically involve interactions between object and environment, namely extrinsic contacts. Prior work on Neural Contact Fields (NCF) use intrinsic tactile sensing between gripper and object to estimate extrinsic contacts in simulation. However, its effectiveness and utility in real-world tasks remains unknown. In this work, we improve NCF to enable sim-to-real transfer and use it to train policies for mug-in-cupholder and bowl-in-dishrack insertion tasks. We find our model NCF-v2, is capable of estimating extrinsic contacts in the real-world. Furthermore, our insertion policy with NCF-v2 outperforms policies without it, achieving 33% higher success and 1.36x faster execution on mug-in-cupholder, and 13% higher success and 1.27x faster execution on bowl-in-dishrack.
Theseus: A Library for Differentiable Nonlinear Optimization
Jul 19, 2022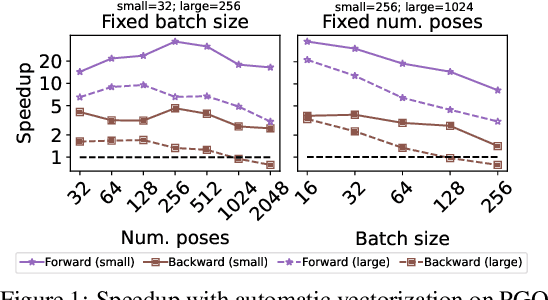
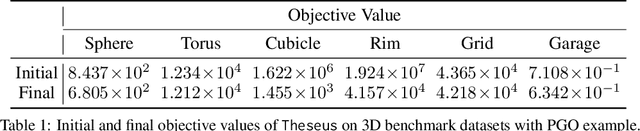
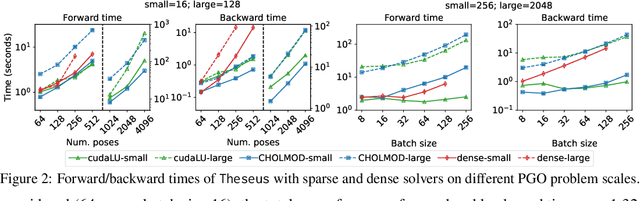
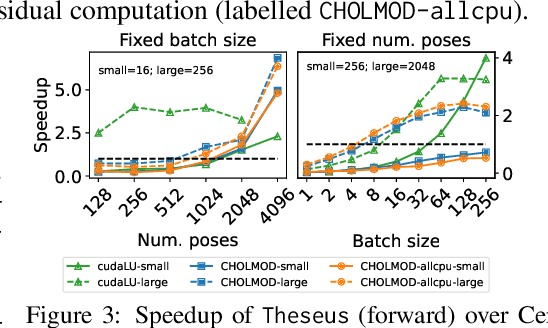
We present Theseus, an efficient application-agnostic open source library for differentiable nonlinear least squares (DNLS) optimization built on PyTorch, providing a common framework for end-to-end structured learning in robotics and vision. Existing DNLS implementations are application specific and do not always incorporate many ingredients important for efficiency. Theseus is application-agnostic, as we illustrate with several example applications that are built using the same underlying differentiable components, such as second-order optimizers, standard costs functions, and Lie groups. For efficiency, Theseus incorporates support for sparse solvers, automatic vectorization, batching, GPU acceleration, and gradient computation with implicit differentiation and direct loss minimization. We do extensive performance evaluation in a set of applications, demonstrating significant efficiency gains and better scalability when these features are incorporated. Project page: https://sites.google.com/view/theseus-ai
K-level Reasoning for Zero-Shot Coordination in Hanabi
Jul 14, 2022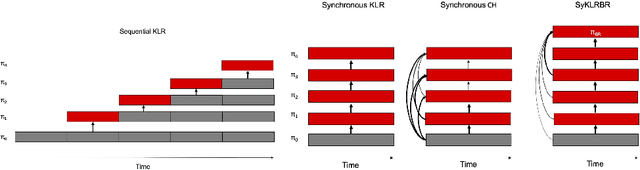
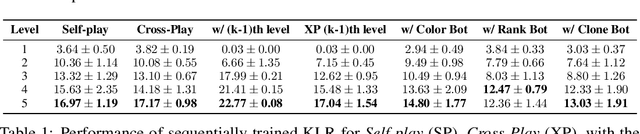

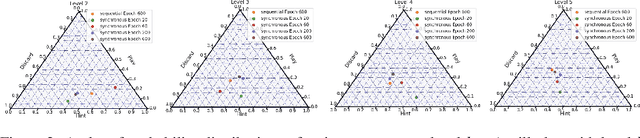
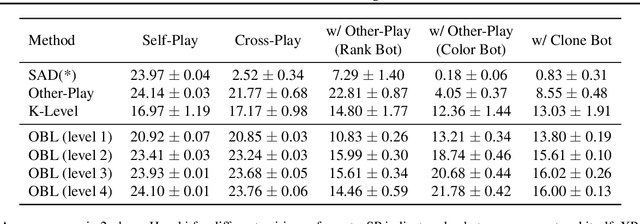
The standard problem setting in cooperative multi-agent settings is self-play (SP), where the goal is to train a team of agents that works well together. However, optimal SP policies commonly contain arbitrary conventions ("handshakes") and are not compatible with other, independently trained agents or humans. This latter desiderata was recently formalized by Hu et al. 2020 as the zero-shot coordination (ZSC) setting and partially addressed with their Other-Play (OP) algorithm, which showed improved ZSC and human-AI performance in the card game Hanabi. OP assumes access to the symmetries of the environment and prevents agents from breaking these in a mutually incompatible way during training. However, as the authors point out, discovering symmetries for a given environment is a computationally hard problem. Instead, we show that through a simple adaption of k-level reasoning (KLR) Costa Gomes et al. 2006, synchronously training all levels, we can obtain competitive ZSC and ad-hoc teamplay performance in Hanabi, including when paired with a human-like proxy bot. We also introduce a new method, synchronous-k-level reasoning with a best response (SyKLRBR), which further improves performance on our synchronous KLR by co-training a best response.
* Neurips 2021. 15 pages. 2 figures
On learning adaptive acquisition policies for undersampled multi-coil MRI reconstruction
Mar 30, 2022

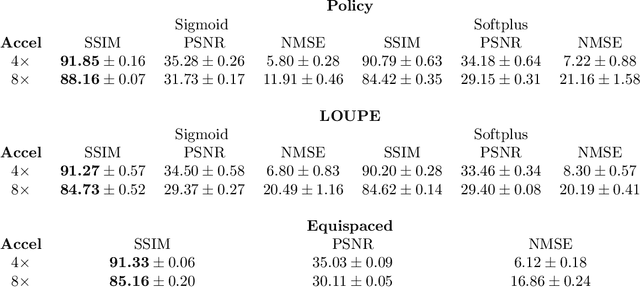

Most current approaches to undersampled multi-coil MRI reconstruction focus on learning the reconstruction model for a fixed, equidistant acquisition trajectory. In this paper, we study the problem of joint learning of the reconstruction model together with acquisition policies. To this end, we extend the End-to-End Variational Network with learnable acquisition policies that can adapt to different data points. We validate our model on a coil-compressed version of the large scale undersampled multi-coil fastMRI dataset using two undersampling factors: $4\times$ and $8\times$. Our experiments show on-par performance with the learnable non-adaptive and handcrafted equidistant strategies at $4\times$, and an observed improvement of more than $2\%$ in SSIM at $8\times$ acceleration, suggesting that potentially-adaptive $k$-space acquisition trajectories can improve reconstructed image quality for larger acceleration factors. However, and perhaps surprisingly, our best performing policies learn to be explicitly non-adaptive.
Active 3D Shape Reconstruction from Vision and Touch
Jul 20, 2021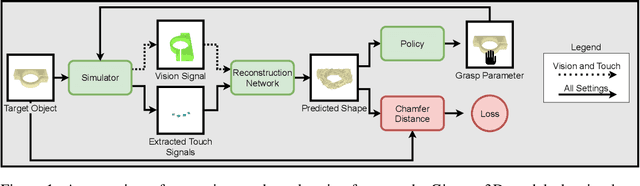
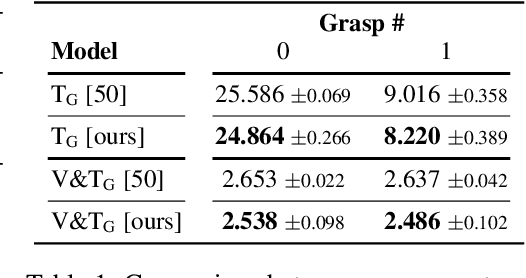
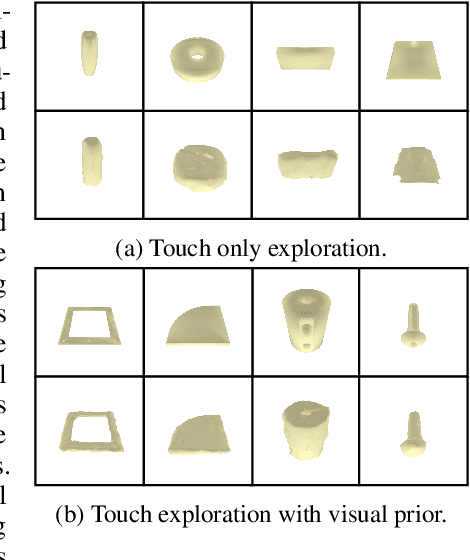
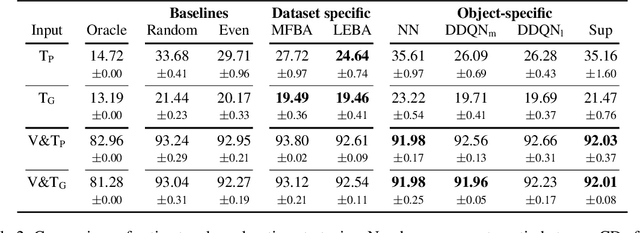
Humans build 3D understandings of the world through active object exploration, using jointly their senses of vision and touch. However, in 3D shape reconstruction, most recent progress has relied on static datasets of limited sensory data such as RGB images, depth maps or haptic readings, leaving the active exploration of the shape largely unexplored. In active touch sensing for 3D reconstruction, the goal is to actively select the tactile readings that maximize the improvement in shape reconstruction accuracy. However, the development of deep learning-based active touch models is largely limited by the lack of frameworks for shape exploration. In this paper, we focus on this problem and introduce a system composed of: 1) a haptic simulator leveraging high spatial resolution vision-based tactile sensors for active touching of 3D objects; 2) a mesh-based 3D shape reconstruction model that relies on tactile or visuotactile signals; and 3) a set of data-driven solutions with either tactile or visuotactile priors to guide the shape exploration. Our framework enables the development of the first fully data-driven solutions to active touch on top of learned models for object understanding. Our experiments show the benefits of such solutions in the task of 3D shape understanding where our models consistently outperform natural baselines. We provide our framework as a tool to foster future research in this direction.
MBRL-Lib: A Modular Library for Model-based Reinforcement Learning
Apr 20, 2021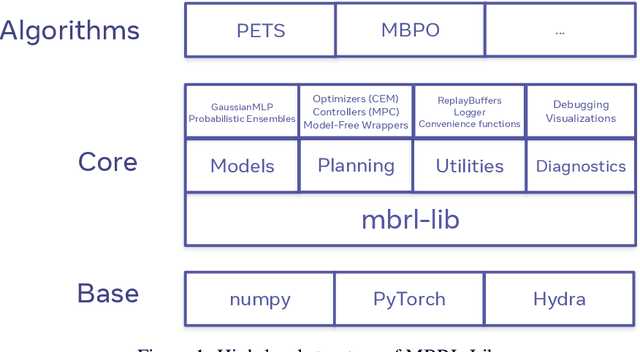

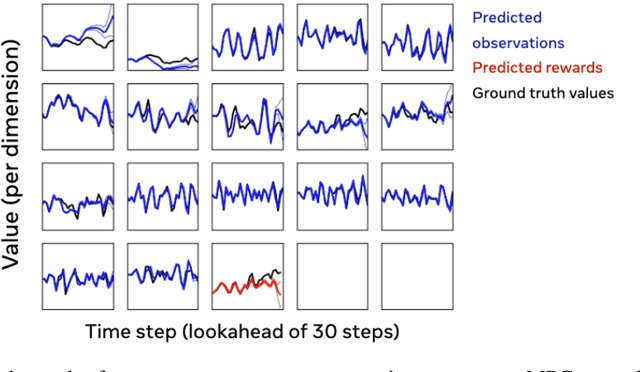
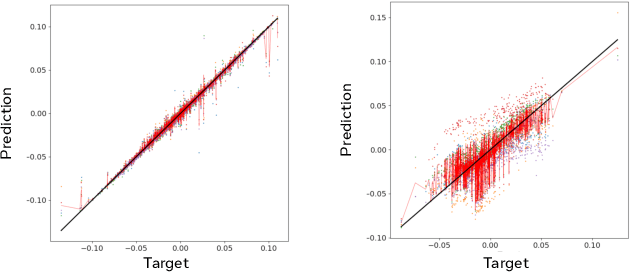
Model-based reinforcement learning is a compelling framework for data-efficient learning of agents that interact with the world. This family of algorithms has many subcomponents that need to be carefully selected and tuned. As a result the entry-bar for researchers to approach the field and to deploy it in real-world tasks can be daunting. In this paper, we present MBRL-Lib -- a machine learning library for model-based reinforcement learning in continuous state-action spaces based on PyTorch. MBRL-Lib is designed as a platform for both researchers, to easily develop, debug and compare new algorithms, and non-expert user, to lower the entry-bar of deploying state-of-the-art algorithms. MBRL-Lib is open-source at https://github.com/facebookresearch/mbrl-lib.
Off-Belief Learning
Mar 06, 2021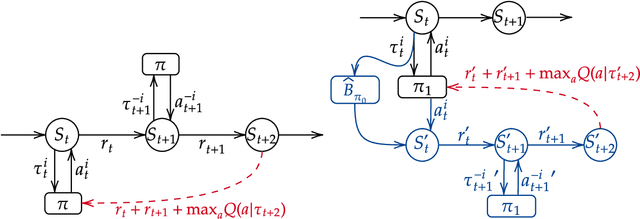

The standard problem setting in Dec-POMDPs is self-play, where the goal is to find a set of policies that play optimally together. Policies learned through self-play may adopt arbitrary conventions and rely on multi-step counterfactual reasoning based on assumptions about other agents' actions and thus fail when paired with humans or independently trained agents. In contrast, no current methods can learn optimal policies that are fully grounded, i.e., do not rely on counterfactual information from observing other agents' actions. To address this, we present off-belief learning} (OBL): at each time step OBL agents assume that all past actions were taken by a given, fixed policy ($\pi_0$), but that future actions will be taken by an optimal policy under these same assumptions. When $\pi_0$ is uniform random, OBL learns the optimal grounded policy. OBL can be iterated in a hierarchy, where the optimal policy from one level becomes the input to the next. This introduces counterfactual reasoning in a controlled manner. Unlike independent RL which may converge to any equilibrium policy, OBL converges to a unique policy, making it more suitable for zero-shot coordination. OBL can be scaled to high-dimensional settings with a fictitious transition mechanism and shows strong performance in both a simple toy-setting and the benchmark human-AI/zero-shot coordination problem Hanabi.