 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASS: Geometry-Aware Spherical Sampling for Disentangled Diversity Enhancement in Text-to-Image Generation
Feb 19, 2026Despite high semantic alignment, modern text-to-image (T2I) generative models still struggle to synthesize diverse images from a given prompt. This lack of diversity not only restricts user choice, but also risks amplifying societal biases. In this work, we enhance the T2I diversity through a geometric lens. Unlike most existing methods that rely primarily on entropy-based guidance to increase sample dissimilarity, we introduce Geometry-Aware Spherical Sampling (GASS) to enhance diversity by explicitly controlling both prompt-dependent and prompt-independent sources of variation. Specifically, we decompose the diversity measure in CLIP embeddings using two orthogonal directions: the text embedding, which captures semantic variation related to the prompt, and an identified orthogonal direction that captures prompt-independent variation (e.g., backgrounds). Based on this decomposition, GASS increases the geometric projection spread of generated image embeddings along both axes and guides the T2I sampling process via expanded predictions along the generation trajectory. Our experiments on different frozen T2I backbones (U-Net and DiT, diffusion and flow) and benchmarks demonstrate the effectiveness of disentangled diversity enhancement with minimal impact on image fidelity and semantic alignment.
Inference-time Physics Alignment of Video Generative Models with Latent World Models
Jan 15, 2026State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
DIMCIM: A Quantitative Evaluation Framework for Default-mode Diversity and Generalization in Text-to-Image Generative Models
Jun 05, 2025Recent advances in text-to-image (T2I) models have achieved impressive quality and consistency. However, this has come at the cost of representation diversity. While automatic evaluation methods exist for benchmarking model diversity, they either require reference image datasets or lack specificity about the kind of diversity measured, limiting their adaptability and interpretability. To address this gap, we introduce the Does-it/Can-it framework, DIM-CIM, a reference-free measurement of default-mode diversity ("Does" the model generate images with expected attributes?) and generalization capacity ("Can" the model generate diverse attributes for a particular concept?). We construct the COCO-DIMCIM benchmark, which is seeded with COCO concepts and captions and augmented by a large language model. With COCO-DIMCIM, we find that widely-used models improve in generalization at the cost of default-mode diversity when scaling from 1.5B to 8.1B parameters. DIMCIM also identifies fine-grained failure cases, such as attributes that are generated with generic prompts but are rarely generated when explicitly requested. Finally, we use DIMCIM to evaluate the training data of a T2I model and observe a correlation of 0.85 between diversity in training images and default-mode diversity. Our work provides a flexible and interpretable framework for assessing T2I model diversity and generalization, enabling a more comprehensive understanding of model performance.
Multi-Modal Language Models as Text-to-Image Model Evaluators
May 01, 2025The steady improvements of text-to-image (T2I) generative models lead to slow deprecation of automatic evaluation benchmarks that rely on static datasets, motivating researchers to seek alternative ways to evaluate the T2I progress. In this paper, we explore the potential of multi-modal large language models (MLLMs) as evaluator agents that interact with a T2I model, with the objective of assessing prompt-generation consistency and image aesthetics. We present Multimodal Text-to-Image Eval (MT2IE), an evaluation framework that iteratively generates prompts for evaluation, scores generated images and matches T2I evaluation of existing benchmarks with a fraction of the prompts used in existing static benchmarks. Moreover, we show that MT2IE's prompt-generation consistency scores have higher correlation with human judgment than scores previously introduced in the literature. MT2IE generates prompts that are efficient at probing T2I model performance, producing the same relative T2I model rankings as existing benchmarks while using only 1/80th the number of prompts for evaluation.
Entropy Rectifying Guidance for Diffusion and Flow Models
Apr 18, 2025Guidance techniques are commonly used in diffusion and flow models to improve image quality and consistency for conditional generative tasks such as class-conditional and text-to-image generation. In particular, classifier-free guidance (CFG) -- the most widely adopted guidance technique -- contrasts conditional and unconditional predictions to improve the generated images. This results, however, in trade-offs across quality, diversity and consistency, improving some at the expense of others. While recent work has shown that it is possible to disentangle these factors to some extent, such methods come with an overhead of requiring an additional (weaker) model, or require more forward passes per sampling step. In this paper, we propose Entropy Rectifying Guidance (ERG), a simple and effective guidance mechanism based on inference-time changes in the attention mechanism of state-of-the-art diffusion transformer architectures, which allows for simultaneous improvements over image quality, diversity and prompt consistency. ERG is more general than CFG and similar guidance techniques, as it extends to unconditional sampling. ERG results in significant improvements in various generation tasks such as text-to-image, class-conditional and unconditional image generation. We also show that ERG can be seamlessly combined with other recent guidance methods such as CADS and APG, further boosting generation performance.
PairBench: A Systematic Framework for Selecting Reliable Judge VLMs
Feb 21, 2025As large vision language models (VLMs) are increasingly used as automated evaluators, understanding their ability to effectively compare data pairs as instructed in the prompt becomes essential. To address this, we present PairBench, a low-cost framework that systematically evaluates VLMs as customizable similarity tools across various modalities and scenarios. Through PairBench, we introduce four metrics that represent key desiderata of similarity scores: alignment with human annotations, consistency for data pairs irrespective of their order, smoothness of similarity distributions, and controllability through prompting. Our analysis demonstrates that no model, whether closed- or open-source, is superior on all metrics; the optimal choice depends on an auto evaluator's desired behavior (e.g., a smooth vs. a sharp judge), highlighting risks of widespread adoption of VLMs as evaluators without thorough assessment. For instance, the majority of VLMs struggle with maintaining symmetric similarity scores regardless of order. Additionally, our results show that the performance of VLMs on the metrics in PairBench closely correlates with popular benchmarks, showcasing its predictive power in ranking models.
Improving the Scaling Laws of Synthetic Data with Deliberate Practice
Feb 21, 2025
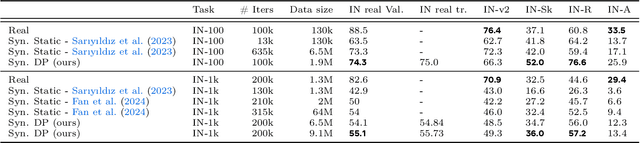
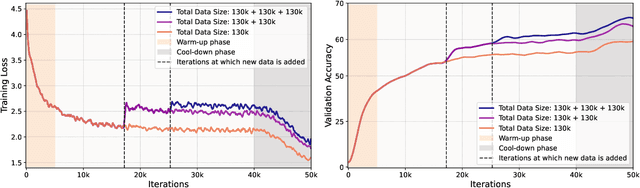

Inspired by the principle of deliberate practice in human learning, we propose Deliberate Practice for Synthetic Data Generation (DP), a novel framework that improves sample efficiency through dynamic synthetic data generation. Prior work has shown that scaling synthetic data is inherently challenging, as naively adding new data leads to diminishing returns. To address this, pruning has been identified as a key mechanism for improving scaling, enabling models to focus on the most informative synthetic samples. Rather than generating a large dataset and pruning it afterward, DP efficiently approximates the direct generation of informative samples. We theoretically show how training on challenging, informative examples improves scaling laws and empirically validate that DP achieves better scaling performance with significantly fewer training samples and iterations. On ImageNet-100, DP generates 3.4x fewer samples and requires six times fewer iterations, while on ImageNet-1k, it generates 8x fewer samples with a 30 percent reduction in iterations, all while achieving superior performance compared to prior work.
Object-centric Binding in Contrastive Language-Image Pretraining
Feb 19, 2025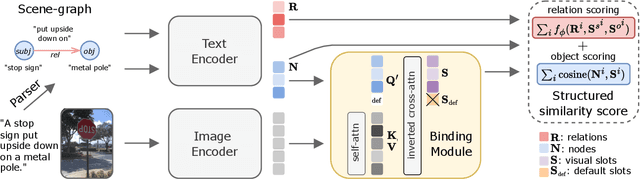
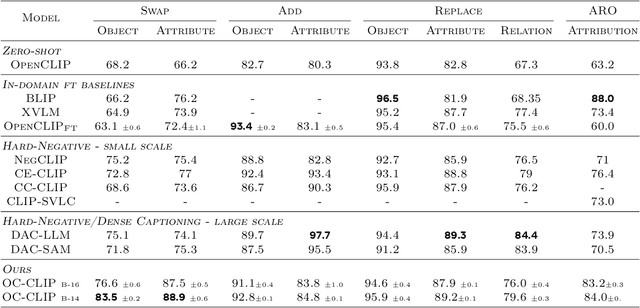
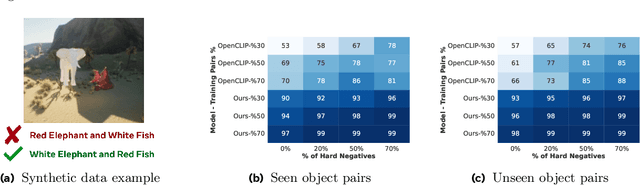
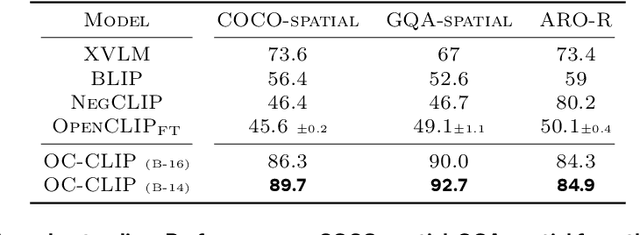
Recent advances in vision language models (VLM) have been driven by contrastive models such as CLIP, which learn to associate visual information with their corresponding text descriptions. However, these models have limitations in understanding complex compositional scenes involving multiple objects and their spatial relationships. To address these challenges, we propose a novel approach that diverges from commonly used strategies, which rely on the design of hard-negative augmentations. Instead, our work focuses on integrating inductive biases into pre-trained CLIP-like models to improve their compositional understanding without using any additional hard-negatives. To that end, we introduce a binding module that connects a scene graph, derived from a text description, with a slot-structured image representation, facilitating a structured similarity assessment between the two modalities. We also leverage relationships as text-conditioned visual constraints, thereby capturing the intricate interactions between objects and their contextual relationships more effectively. Our resulting model not only enhances the performance of CLIP-based models in multi-object compositional understanding but also paves the way towards more accurate and sample-efficient image-text matching of complex scenes.
Augmented Conditioning Is Enough For Effective Training Image Generation
Feb 06, 2025



Image generation abilities of text-to-image diffusion models have significantly advanced, yielding highly photo-realistic images from descriptive text and increasing the viability of leveraging synthetic images to train computer vision models. To serve as effective training data, generated images must be highly realistic while also sufficiently diverse within the support of the target data distribution. Yet, state-of-the-art conditional image generation models have been primarily optimized for creative applications, prioritizing image realism and prompt adherence over conditional diversity. In this paper, we investigate how to improve the diversity of generated images with the goal of increasing their effectiveness to train downstream image classification models, without fine-tuning the image generation model. We find that conditioning the generation process on an augmented real image and text prompt produces generations that serve as effective synthetic datasets for downstream training. Conditioning on real training images contextualizes the generation process to produce images that are in-domain with the real image distribution, while data augmentations introduce visual diversity that improves the performance of the downstream classifier. We validate augmentation-conditioning on a total of five established long-tail and few-shot image classification benchmarks and show that leveraging augmentations to condition the generation process results in consistent improvements over the state-of-the-art on the long-tailed benchmark and remarkable gains in extreme few-shot regimes of the remaining four benchmarks. These results constitute an important step towards effectively leveraging synthetic data for downstream training.